Что такое витрина данных?
Витрина данных — это простая форма хранилища данных, ориентированная на одно направление деятельности или тему. С витриной данных сотрудники могут быстрее получать доступ к данным и статистическим показателям, потому что не нужно тратить время на поиск по более сложному хранилищу данных или вручную собирать данные из разных источников.
Зачем создавать витрину данных?
Витрина данных обеспечивает более простой доступ к данным, необходимым для определенного отдела или производственного направления внутри организации. Например, если ваш отдел маркетинга ищет данные, которые помогут ему повысить эффективность рекламной кампании в период праздников, просматривать и выбирать нужные данные из нескольких разрозненных систем довольно затратно и с точки зрения времени, и с точки зрения денег, причем невозможно обеспечить точность.
Сотрудники подразделений, которые вынуждены искать данные в разных источниках, как правило, пользуются таблицами для обмена информацией и сотрудничества. Это часто приводит к человеческим ошибкам, путанице, сложным согласованиям и появлению нескольких источников достоверных данных — так называемому «табличному кошмару». Витрины данных стали довольно популярны как централизованные хранилища, в которых собираются и упорядочиваются нужные данные, после чего могут создаваться отчеты, информационные панели и визуализации.
Различия между витриной данных, озером данных и хранилищем данных
Витрины данных, озера данных и хранилища данных используются в разных ситуациях и для разных целей.
Хранилище данных — это система управления данными, которая поддерживает анализ бизнес-данных и выполнение аналитики для всей организации. Хранилища данных часто содержат большие объемы данных, в том числе исторических. Обычно данные поступают в хранилище из многочисленных источников, таких как журналы приложений и транзакционные приложения. В хранилище данных хранятся структурированные данные с определенными целями.
Озеро данных позволяет организациям хранить большие объемы структурированных и неструктурированных данных (например, из социальных сетей или данных о посещениях) и мгновенно предоставлять к ним доступ для выполнения в реальном времени аналитики, углубленной аналитики данных и построения сценариев использования машинного обучения. Данные поступают в озеро данных в своей исходной форме, без изменений.
Основное различие между озером данных и хранилищем данных состоит в том, что в озере хранятся большие объемы необработанных данных без заранее определенной структуры. Организациям не нужно определять заранее, как будут использоваться эти данные.
Витрина данных — это простая форма хранилища данных, которое ориентировано на определенную тему или направление деятельности, например на продажи, финансы или маркетинг. С учетом этой узкой специализации получается, что витрины данных собирают данные из меньшего количества источников, чем хранилища данных. Источниками для витрины данных могут служить внутренние операционные системы, центральное хранилище данных и внешние данные.
Преимущества витрины данных
Витрина данных, созданная для определенного отдела или направления деятельности, дает ряд преимуществ:
- Единый источник достоверных данных. Централизованный характер витрины данных гарантирует, что все в отделе или организации принимают решения, опираясь на одни и те же данные. Это важное преимущество, потому что данным и основанным на них прогнозам можно доверять, так что заинтересованные лица могут сосредоточиться на принятии решений и выполнении действий, а не на обсуждении данных.
- Более быстрый доступ к данным. Конкретные бизнес-отделы или пользователи могут быстро получать доступ к нужному им подмножеству данных из корпоративного хранилища данных, и объединять эту информацию с данными из других источников. Когда связи с источниками нужных данных будут установлены, сотрудники смогут получать оперативные данные из витрины данных по мере необходимости, а не обращаться в отдел ИТ, чтобы запросить периодически собираемую информацию. В результате повышается производительность как бизнес-отделов, так и ИТ.
- Быстрое получение статистических данных ускоряет принятие решений. Хранилище данных помогает принимать решения на уровне предприятия, а витрина данных предоставляет аналитику данных на уровне отделов и подразделений. Аналитики могут сосредоточиться на определенных проблемах и возможностях в таких сферах, как финансы и HR, и быстрее переходить от просмотра данных к статистическим показателям, которые позволяют быстрее принимать более взвешенные решения.
- Более простое и быстрое применение. Настройка корпоративного хранилища данных для обслуживания всей компанией может потребовать немало времени и усилий. А витрине данных, настроенной на обслуживание потребностей определенного отдела, достаточно доступа к гораздо меньшему количеству множеств данных. Поэтому витрину данных проще создавать и быстрее можно начать использовать.
- Создание гибкого и масштабируемого решения для управления данными. Витрины данных предлагают гибкие системы по управлению данными, которые работают с учетом потребностей компании, в том числе могут использовать информацию, собранную при выполнении прошлых проектов, чтобы способствовать решению текущих задач. Отделы и подразделения могут обновлять и изменять свои витрины данных, опираясь на новые и недавно запущенные проекты по аналитике.
- Анализ переходных процессов. Некоторые проекты по аналитике данных выполняются в сжатые сроки. Например, нужно провести анализ онлайн-продаж по результатам двухнедельной рекламной акции, чтобы представить его на совещании отдела. И отдел может быстро настроить витрину данных для выполнения такого проекта.
Перенос витрин данных в облако
Рабочие группы и отделы стараются действовать более гибко и опираться на данные при внедрении общей стратегии и принятии повседневных решений. Но, как правило, бывает непросто превратить постоянно растущий объем данных в статистические показатели. Финансовые директора проводят в среднем по 2,24 часа в день, анализируя таблицы данных. Рабочие группы обычно обращаются за помощью в отдел ИТ, и ИТ-специалистам приходится тратить немало сил, чтобы соответствовать запросам пользователей и предоставлять данные из разнообразных источников в больших объемах, а также быстрее реагировать на запросы.
Создание витрин данных также может осложнить задачи и без того загруженному работой отделу ИТ, потому что им нужно будет постоянно контролировать эти витрины данных и обеспечивать их безопасность. Перенос витрин данных в облако может решить многие проблемы как рабочих групп, так и отделов ИТ, потому что администрированием и обеспечением безопасности в облаке будет заниматься поставщик облачных решений. Таким образом значительно сокращается число задач, которые нужно выполнять вручную, и снижаются операционные расходы.
Как Oracle Autonomous Database обеспечивает работу облачных витрин данных
Oracle предлагает готовое комплексное решение самообслуживания, которое позволяет рабочим группам и отделам пользоваться надежными статистическими показателями, полученными в результате глубокого анализа данных. Эти показатели помогут им быстрее принимать решения.
Сотрудники и отделы могут быстро объединять все нужные данные из разных источников и в разных форматах, включая пространственные объекты и графы, в единую базу данных, которая способствует налаживанию сотрудничества в защищенном режиме благодаря тому, что витрины данных предоставляют единственный источник достоверных данных. Аналитики могут с легкостью использовать инструменты самообслуживания для работы с данными и возможности машинного обучения (не занимаясь самостоятельно написанием программного кода), чтобы ускорить загрузку данных, их преобразование и подготовку, автоматически выявлять шаблоны и тенденции, делать прогнозы и получать статистические показатели на основе данных известного проиcхождения.
Контролируемые и безопасные решения Oracle позволяют снизить нагрузку на отделы ИТ. Отделы ИТ могут полагаться на простые, надежные и воспроизводимые методы при любых запросах на аналитику данных от различных подразделений организации, и таким образом значительно повышать производительность.
Oracle Autonomous Database для аналитики и хранилища данных автоматизирует инициализацию, настройку, обеспечение безопасности, отладку, масштабирование, внесение исправлений, создание резервных копий и ремонт. Он практически полностью устраняет потребность в ручном выполнении сложных задач, которые могут вести к человеческим ошибкам. Встроенные инструменты для работы с данными позволяют в режиме самообслуживания с легкостью выполнять загрузку данных, их преобразование, бизнес-моделирование и автоматическое вычисление статистических показателей для витрин данных. Администраторы баз данных могут не тратить силы на решение рутинных задач, а вместо этого заняться проектированием новых приложений и помогать другим отделам в достижении поставленных целей. Специалисты из сферы финансов, HR и маркетинга получают безопасный доступ к данным и могут рассчитывать на неизменно быстрые и качественные ответы на запросы даже в периоды пиковых нагрузок независимо от того, сколько пользователей одновременно обращаются за информацией. Autonomous Database выполняет масштабирование автоматически в зависимости от рабочей нагрузки без простоев в работе.
Витрина данных (Data Mart)
Предметно-ориентированная и, как правило, содержащая данные по одному из направлений деятельности компании база данных. Она отвечает тем же требованиям, что и хранилище данных, но, в отличие от него, нейтрально к приложениям. В витрине информация хранится оптимизированно с точки зрения решения конкретных задач.
Кроме того, под витриной данных иногда понимают относительно небольшое хранилище или же его часть, предназначенную для применения конкретным подразделением организации и/или определенной группой пользователей. Если в корпоративной системе имеется две витрины данных, то общие данные, содержащиеся в обеих секциях одновременно, должны быть представлены идентично.
Витрины данных имеют следующие достоинства:
- пользователи видят и работают только с теми данными, которые им нужны;
- витрины являются максимально приближенными к пользователю;
- витрины данных проще в проектировании, настройке и поддержке, чем полноразмерное хранилище;
- для витрин данных не требуется использовать мощные вычислительные средства.
К недостаткам витрин данных можно отнести сложность контроля целостности и противоречивости данных.
Простор для данных
Если коротко, то витрины (витрина от англ. data mart) – это набор структурированных данных. Обычно это данные по определенной теме или задаче в компании. Например, витрина с данными о заказчиках для отдела маркетинга может содержать подробные данные по договорам, истории заказов и поставок, оплатах, звонках и адресах доставки. Ничего лишнего, только нужные и актуальные очищенные данные, полученные из других ИС предприятия. Таких витрин даже на одном предприятии может быть множество.

Чаще всего с помощью витрин анализируют данные и строят ML-модели. Также витрины могут использоваться на предприятиях в качестве мастер-данных, например как справочники. Помимо этого, витрина может выступать периферическим узлом в сетях обмена данными между различными участниками. Примером концепции построения таких сетей для обмена данными является Data mesh (вот тут есть хороший перевод статьи по теме Хабр).
Типовой проект внедрения витрин состоит из технологической и прикладной частей. Если для решения технологических задач брать готовый инструмент, а не писать систему с нуля, то можно заложить больше ресурсов на прикладные задачи, которым зачастую уделяют незаслуженно мало внимания. Для B2B и других проектов, предполагающих внедрение множества витрин у различных заказчиков, готовый инструмент позволит существенно снизить технические риски, уменьшить затраты и сократить сроки внедрения.
Что требуется от витрины?
Сразу хотелось бы ответить на вопрос: а почему нельзя просто взять любую из существующих СУБД и сразу закрыть технологические задачи?

На самом деле, можно, но, как обычно, всё дело в деталях, а точнее в требованиях к витринам, которые нередко упускаются из вида и могут болезненно проявиться уже на поздних этапах, например при ОПЭ:
- Изоляция данных. Обновление данных, например загрузка справочника, может быть растянуто во времени, при этом до окончания загрузки текущая версия справочника должна быть полностью доступна с исключением «грязного чтения» загружаемой версии.
- Гарантии атомарности операций при обновлении данных. В случае сбоев и ошибок загрузки данных витрина остаётся в состоянии, которое предшествовало сбойному процессу. Другими словами, или данные обновляются полностью, или не обновляются вовсе, не оставляя следов сбойных операций.
- Устойчивость к дубликатам изменений. Весьма сложно и дорого реализовывать во всех ИС-источниках данных выгрузку по принципу exactly-once. Наличие дублей одинаковых изменений объектов не должно приводить к нарушению логической целостности состояния витрин.
- Системная темпоральность. Мало какая реляционная СУБД имеет функцию системной темпоральности «из коробки». Ведение системного времени и версионирование записей по системному времени позволяет сравнивать состояние данных витрины между двумя разными моментами времени или проводить «расследование», основываясь на данных, которые были в витрине в определенный момент в прошлом. Одним из вариантов обеспечения темпоральности является реализация SCD2 с ведением диапазонов сроков действия для версий записи.
- Эффективное выполнение различных видов запросов: сравнительно редких и тяжелых аналитических запросов, затрагивающих большой объем данных (OLAP-нагрузка), и множества одновременных простых запросов (OLTP-нагрузка). Как правило, СУБД заточены на какой-то один вариант нагрузки: OLAP или OLTP.
Концепция
С середины 2020 года наша команда разрабатывает Систему, предназначенную для построения витрин данных. Начав с разработки прототипа, мы продолжили развивать функционал в рамках той же архитектуры. Сейчас это открытое программное обеспечение, которое мы используем при внедрениях витрин данных.
У нас в тех. проекте записано: «Простор – интеграционная система, обеспечивающая унифицированный интерфейс темпоральной реляционной СУБД к гетерогенному хранилищу данных». Гетерогенное хранилище позволяет использовать сильные стороны каждой из СУБД, входящих в состав хранилища, и не быть заложником недостатков одной из них.
В Просторе гетерогенное хранилище представлено такими СУБД:
- Greenplum – аналитическая СУБД, предназначенная для OLAP-нагрузки. Хорошо горизонтально масштабируется, имеет высокий уровень поддержки стандарта SQL.
- Clickhouse – аналитическая СУБД. Демонстрирует одни из лучших в классе показатели выполнения агрегационных запросов. Не полностью поддерживает SQL и имеет ряд иных ограничений при эксплуатации, например при изменении или удалении записей.
- Tarantool – In-memory СУБД с персистентным хранением данных. Отличные показатели при OLTP-нагрузке (чтение отдельных записей). В кластерном режиме имеет ограничения по исполнению SQL-запросов.
- PostgreSQL – всеми любимая реляционная СУБД. Хорошо держит OLTP-нагрузку, но горизонтально не масштабируется и, соответственно, не подходит для аналитических запросов с действительно большим объемом данных.
Состав СУБД хранилища данных можно изменять в зависимости от характера предполагаемой нагрузки или уже в процессе эксплуатации. Для небольших витрин можно использовать одну СУБД, например PostgreSQL. Для крупных витрин, содержащих большие объемы данных и предполагающих разнородные запросы, можно использовать различные сочетания, например Greenplum + Tarantool или Greenplum + Tarantool + Clickhouse.
Ядро системы – сервис, выполняющий роль координатора и диспетчера. Обеспечивает единый интерфейс доступа, маршрутизирует запросы, управляет процессами загрузки и выгрузки данных, контролирует целостность данных. Также ядро парсит входящие SQL-запросы и обогащает их до вида, готового к исполнению в той или иной СУБД. Непосредственно выполнением запросов занимаются СУБД хранилища.

Обмен большими объемами данных между витриной и поставщиками/потребителями этих данных выполняется через Kafka. Но если речь идет о небольших объемах данных (сотни записей), то загружать или читать данные можно напрямую через Ядро.
Ядро управляет специальными компонентами – коннекторами, предназначенными для массивно-параллельной загрузки данных из Kafka в СУБД хранилища и массивно-параллельной выгрузки данных в Kafka из СУБД хранилища.
С точки зрения пользователя
Если пользователем называть поставщика или потребителя данных, то с точки зрения такого «пользователя» Простор выглядит так:

- Единый интерфейс доступа – JDBC 4.2. Подключиться к Простору можно как к обычной реляционной СУБД, например, используя SQL-клиент, в котором доступны все элементы логической модели и запросы к ним.
- Единая логическая реляционная модель данных, скрывающая «под капотом» реальные физические модели данных СУБД хранилища. При изменении логической модели данных автоматически изменяются и соответствующие физические модели в СУБД хранилища. Логическая модель – внешнее пользовательское представление модели данных витрины. Включает следующие логические сущности: a. Логическая таблица (table) – для «пользователя» это обычная таблица, но с возможностью указать момент времени в прошлом, относительно которого требуется «наблюдать» данные таблицы.
SELECT * FROM customers FOR SYSTEM_TIME AS OF '2021-12-01 15:00:00'
Также для логической таблицы можно ограничить СУБД хранилища, в которых она будет физически расположена. b. Логическое представление (view) – сохраненный именованный SQL-запрос, к которому можно выполнять запросы, также с возможностью указания момента времени «наблюдения» данных. c. Логическое материализованное представление (materialized view) – необычная логическая таблица, новые или измененные данные в которую попадают автоматически на основании сохраненного запроса к другим логическим таблицам, расположенным в других СУБД хранилища. Особой возможностью запросов к логическим материализованным представлениям является автоматическое перенаправление такого запроса к исходным логическим таблицам, если отставание данных материализованного представления больше заданного предела. Материализованные представления позволяют реализовать более интересные варианты топологии витрины, в которых одна из СУБД исполняет роль отказоустойчивого мастера, а другая — содержит материализованные read-only-представления. d. Логическая внешняя таблица – виртуальная таблица, по сути являющаяся указателем на источник или приёмник данных. Записывая или считывая данные из этой таблицы, можно управлять загрузкой и выгрузкой данных.
-- открыть новую дельту BEGIN DELTA; -- загрузка данных в логическую таблицу customers из Kafka INSERT INTO customers SELECT * FROM customers_kafka_ext; -- загрузка данных в логическую таблицу calls из Kafka INSERT INTO calls SELECT * FROM calls_kafka_ext; -- загрузка данных в логическую таблицу balance из Kafka INSERT INTO balance SELECT * FROM balance_kafka_ext; -- закрыть дельту COMMIT DELTA;
Все изменения, выполненные в одной дельте, помечаются единой меткой времени комита дельты. Изменения данных, производимые в рамках открытой дельты, изолированы от пользовательских запросов с целью исключения «грязного чтения». Можно утверждать, что изменения в рамках дельты доступны для пользователя целиком и одномоментно или не доступны вовсе. Если необходимо, то открытую дельту можно откатить.
Заключение
Простор – система для построения витрин данных, доступная под лицензией Apache 2.0. Для тестирования и ознакомления с возможностями системы можно развернуть минимальную конфигурацию, где Простор использует в качестве хранилища только PostgreSQL. Инструкция по развертыванию доступна тут. Если объем данных для витрины не очень большой, то такая конфигурация может использоваться и для PROD.
Введение в витрины данных
Бизнес-пользователи сильно полагаются на централизованно управляемые источники данных, созданные ит-специалистами (ИТ), но это может занять несколько месяцев для ИТ-отдела для доставки изменений в данном источнике данных. В ответ пользователи часто прибегают к созданию собственных киосков данных с базами данных Access, локальными файлами, сайтами и электронными таблицами SharePoint, что приводит к нехватке управления и надлежащему надзору, чтобы обеспечить поддержку таких источников данных и обеспечить разумное производительность.
Datamarts помогает преодолеть разрыв между бизнес-пользователями и ИТ-службами. Datamarts — это решения для самостоятельной аналитики, позволяющие пользователям хранить и изучать данные, загруженные в полностью управляемую базу данных. Datamarts предоставляют простой и необязательный интерфейс для приема данных из разных источников данных, извлечения и загрузки данных с помощью Power Query, а затем их загрузки в базу данных SQL Azure, полностью управляемую и не требующую настройки или оптимизации.
После загрузки данных в datamart можно дополнительно определить связи и политики бизнес-аналитики и анализа. Datamarts автоматически создает семантические модели или семантические модели, которые можно использовать для создания отчетов и панелей мониторинга Power BI. Вы также можете запросить datamart с помощью конечной точки T-SQL или визуального интерфейса.
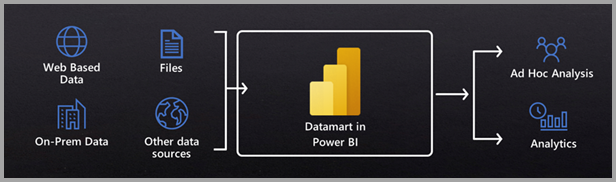
Datamarts предлагает следующие преимущества:
- Пользователи самообслуживания могут легко выполнять аналитику реляционной базы данных без необходимости администратора базы данных
- Datamarts обеспечивают сквозное прием данных, подготовку и изучение с помощью SQL, включая интерфейсы без кода
- Включение создания семантических моделей и отчетов в рамках единого целостного интерфейса
- 100 % на основе веб-сайтов, никакого другого программного обеспечения не требуется
- Интерфейс без кода, который приводит к полному управляемому объекту datamart
- Автоматическая настройка производительности
- Встроенный визуальный и редактор SQL-запросов для нерегламентированного анализа
- Поддержка SQL и других популярных клиентских средств
- Встроенная интеграция с Power BI, Microsoft Office и другими предложениями Microsoft Analytics
- Включено с емкостями Power BI Premium и Premium на пользователя
Когда следует использовать datamarts
Диаграммы данных предназначены для интерактивных рабочих нагрузок данных для сценариев самообслуживания. Например, если вы работаете с учетом или финансами, вы можете создавать собственные модели данных и коллекции, которые можно использовать для самостоятельного обслуживания бизнес-вопросов и ответов с помощью T-SQL и визуальных запросов. Кроме того, эти коллекции данных по-прежнему можно использовать для более традиционных возможностей создания отчетов Power BI. Datamarts рекомендуется для клиентов, которым нужна доменная ориентация, децентрализованное владение данными и архитектура, например пользователи, которым нужны данные в качестве продукта или платформы данных самообслуживания.
Datamarts предназначены для поддержки следующих сценариев:
- Данные самообслуживания отделов: централизация небольших и умеренных объемов данных (примерно 100 ГБ) в полностью управляемой базе данных SQL. Datamarts позволяет назначить одно хранилище для самостоятельного подчиненного отчета (например, excel, отчетов Power BI, других), тем самым уменьшая инфраструктуру в решениях самообслуживания.
- Аналитика реляционной базы данных с помощью Power BI: доступ к данным datamart с помощью внешних клиентов SQL. Azure Synapse и другие службы и средства, использующие T-SQL, также могут использовать диаграммы данных в Power BI.
- Комплексные семантические модели. Включение создателей Power BI для создания комплексных решений без зависимостей от других средств или ИТ-команд. Datamarts избавляется от управления оркестрацией между потоками данных и семантических моделей с помощью автоматически созданных семантических моделей, обеспечивая визуальные возможности для запроса данных и нерегламентированного анализа, все поддерживаемые базой данных SQL Azure.
В следующей таблице описываются эти предложения и лучшие варианты использования для каждого из них, включая их роль с данными.
- Внешний общий доступ
- Совместное использование между границами отдела или организации с включенной безопасностью
- Загрузка данных в диаграммы данных с различными расписаниями обновления
- Разделение этапов подготовки данных и данных от хранилища, поэтому их можно повторно использовать семантические модели.
- Объединение данных из нескольких источников
- Выборочный общий доступ к таблицам datamart для подробных отчетов
- Составные модели — семантическая модель с данными из datamart и других источников данных за пределами datamart
- Модели прокси-сервера — семантическая модель, использующая DirectQuery для автоматически созданной модели, используя один источник истины
Интеграция datamarts и потоков данных
- Для решений с существующими потоками данных:
- Простое использование данных с данными для применения дополнительных преобразований или включения нерегламентированного анализа и запроса с помощью запросов SQL
- Легко интегрировать решение хранения данных без кода без управления семантических моделей
- Выполнение повторного извлечения, преобразования и загрузки (ETL) в большом масштабе для больших объемов данных
- Создание собственного озера данных и использование потоков данных в качестве конвейера для данныхmarts

Сравнение потоков данных с данными
В этом разделе описываются различия между потоками данных и данными.
Потоки данных обеспечивают повторное использование извлечения, преобразования и загрузки (ETL). Таблицы нельзя просматривать, запрашивать или изучать без семантической модели, но их можно определить для повторного использования. Данные предоставляются в формате Power BI или CDM, если вы приносите собственное озеро данных. Потоки данных используются Power BI для приема данных в диаграммы данных. Потоки данных следует использовать всякий раз, когда вы хотите повторно использовать логику ETL.
Используйте потоки данных, когда необходимо:
- Создайте повторно используемые и доступные для совместного использования данные для элементов в Power BI.
Datamarts — это полностью управляемая база данных, которая позволяет хранить и изучать данные в реляционной и полностью управляемой базе данных SQL Azure. Datamarts обеспечивают поддержку SQL, конструктор визуальных запросов без кода, безопасность на уровне строк (RLS) и автоматическое создание семантической модели для каждого объекта datamart. Вы можете выполнять нерегламентированный анализ и создавать отчеты в Интернете.
Используйте диаграммы данных, когда необходимо:
- Сортировка, фильтрация, выполнение простой статистической обработки или с помощью выражений, определенных в SQL
- Для выходных данных, которые представляют собой результаты, наборы, таблицы и отфильтрованные таблицы данных
- Предоставление доступных данных через конечную точку SQL
- Включение пользователей, у которых нет доступа к Power BI Desktop
Связанный контент
В этой статье представлен обзор данныхmarts и множество способов их использования.
В следующих статьях содержатся дополнительные сведения о datamarts и Power BI:
- Общие сведения о диаграммах данных
- Начало работы с datamarts
- Анализ данных
- Создание отчетов с помощью datamarts
- Управление доступом в datamarts
- Администрирование Datamart
- Руководство по принятию решений Microsoft Fabric: хранилище данных или lakehouse
Дополнительные сведения о потоках данных и преобразовании данных см. в следующих статьях:
- Введение в потоки данных и самостоятельную подготовку данных
- Руководство. Формирование и объединение данных в Power BI Desktop