аргумент stratify в train_test_split против StratifiedShuffleSplit
В чем разница между использованием аргумента stratify в функции train_test_split sklearn и функцией StratifiedShuffleSplit ? Разве они не делают одно и то же?
Поделиться Источник 19 апреля 2020 в 05:08
1 ответ
Эти два модуля выполняют разные операции.
train_test_split ,, как явно подразумевает его название, используется для разделения данных в одном учебном и одном тестовом подмножестве, а аргумент stratify позволяет это делать стратифицированным образом.
StratifiedShuffleSplit , с другой стороны, предоставляет разделения для перекрестной проверки; из документации:
Стратифицированный перекрестный валидатор ShuffleSplit
Предоставляет индексы обучения/теста для разделения данных в наборах обучения/теста.
Обратите внимание на множественные наборы (моё подчеркивание).
Таким образом, StratifiedShuffleSplit следует использовать вместо KFold , когда мы хотим убедиться, что разделения CV являются стратифицированными, а не заменяют train_test_split .
Параметр «стратифицировать» из метода «train_test_split» (scikit Learn)
Я пытаюсь использовать train_test_split из пакета scikit Learn, но у меня возникли проблемы с параметром stratify . Вот код:
from sklearn import cross_validation, datasets X = iris.data[. 2] y = iris.target cross_validation.train_test_split(X,y,stratify=y) Однако, я продолжаю сталкиваться с следующей проблемой:
raise TypeError("Invalid parameters passed: %s" % str(options)) TypeError: Invalid parameters passed:
Есть ли у кого-то идеи, что происходит? Ниже приведена документация по функции.
[. ]
stratify : похожее на массив или None (по умолчанию — None)
Если не None, данные разбиваются в стратифицированном виде, используя это как массив меток.
Новое в версии 0.17: stratify разделение
[. ]
Поделиться Источник 17 января 2016 в 19:05
6 ответов
Этот параметр stratify создает разделение, так что пропорция значений в полученной выборке будет такой же, как и пропорция значений, предоставленных параметру stratify .
Например, если переменная y является бинарной категориальной переменной со значениями 0 и 1 и содержит 25% нулей и 75% единиц, stratify=y гарантирует, что ваше случайное разделение содержит 25% значений 0 и 75% значений 1 .
Поделиться 11 августа 2016 в 07:00
Для моего будущего, который приходит сюда через Google:
train_test_split теперь находится в model_selection , поэтому:
from sklearn.model_selection import train_test_split # given: # features: xs # ground truth: ys x_train, x_test, y_train, y_test = train_test_split(xs, ys, test_size=0.33, random_state=0, stratify=ys) это способ использовать его. Установка random_state желательна для воспроизводимости.
Поделиться 12 октября 2017 в 18:36
Scikit-Learn просто говорит вам, что он не распознает аргумент «stratify», а не то, что вы неправильно его используете. Это происходит потому, что параметр был добавлен в версии 0.17, как указано в документации, которую вы процитировали.
Поэтому вам просто нужно обновить Scikit-Learn.
Поделиться 10 декабря 2016 в 10:33
В этом контексте стратификация означает, что метод train_test_split возвращает обучающие и тестовые подмножества, которые имеют те же пропорции классовых меток, что и входной набор данных.
Поделиться 01 декабря 2017 в 00:14
Ответ, который я могу дать, заключается в том, что стратификация сохраняет пропорцию распределения данных в целевом столбце — и описывает ту же пропорцию распределения в train_test_split. Возьмем, например, если проблема заключается в бинарной классификации, а целевой столбец имеет пропорцию 80% = да, а 20% = нет. Поскольку в целевом столбце в 4 раза больше ‘да’, чем ‘нет’, разделив на train и test без стратификации, мы можем столкнуться с проблемой попадания только ‘да’ в наш тренировочный набор, а все ‘нет’ попадают в наш тестовый набор. (т.е. тренировочный набор может не иметь ‘нет’ в своем целевом столбце)
Следовательно, путем стратефикации, целевой столбец для набора тренировок имеет 80% ‘да’ и 20% ‘нет’, а также целевой столбец для набора тестировок имеет 80% ‘да’ и 20% ‘нет’ соответственно.
Следовательно, Stratify делает даже распределение target(label) в наборе тренировок и тестировок — так же, как оно распределено в исходном наборе данных.
from sklearn.model_selection import train_test_split X_train, y_train, X_test, y_test = train_test_split(features, target, test-size = 0.25, stratify = target, random_state = 43) Поделиться 02 мая 2022 в 21:37
Попробуйте запустить этот код, он «просто работает»:
from sklearn import cross_validation, datasets iris = datasets.load_iris() X = iris.data[. 2] y = iris.target x_train, x_test, y_train, y_test = cross_validation.train_test_split(X,y,train_size=.8, stratify=y) y_test array([0, 0, 0, 0, 2, 2, 1, 0, 1, 2, 2, 0, 0, 1, 0, 1, 1, 2, 1, 2, 0, 2, 2, 1, 2, 1, 1, 0, 2, 1]) Для чего нужен train_test_split в sklearn?
Сейчас занимаюсь машинным обучением, может кто подробно рассказать, для чего в МО нужны X_train,X_test,y_train,y_test, аргументы, которые мы получаем в результате функции train_test_split() ?
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=42) И каким образом задается параметр test_size?
Отслеживать
задан 12 дек 2019 в 15:59
389 1 1 золотой знак 5 5 серебряных знаков 16 16 бронзовых знаков
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Таким образом вы делите свою выборку на тренировочную и тестовую часть. Обучение будет происходит на тренировочной выборке, а на тестовой — проверка полученных «знаний». test_size используется для разбиения выборки(в вашем случае будет 20% использовано на тесты).
Отслеживать
ответ дан 12 дек 2019 в 18:05
386 1 1 серебряный знак 13 13 бронзовых знаков
А как формируется тренировочная и тестовая часть?
12 дек 2019 в 19:38
Вы сами их формируете, разбивая выборку.
12 дек 2019 в 19:55
- python
- машинное-обучение
-
Важное на Мете
Похожие
Подписаться на ленту
Лента вопроса
Для подписки на ленту скопируйте и вставьте эту ссылку в вашу программу для чтения RSS.
Дизайн сайта / логотип © 2024 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2024.3.8.5973
Примеры разделения датасета на train и test c Scikit-learn
Если вы разбиваете датасет на данные для обучения и тестирования, нужно помнить о некоторых моментах. Далее следует обсуждение трех передовых практик, которые стоит учитывать при подобном разделении. А также демонстрация того, как реализовать эти соображения в Python.
В данной статье обсуждаются три конкретных особенности, которые следует учитывать при разделении набора данных, подходы к решению связанных проблем и практическая реализация на Python.
Для наших примеров мы будем использовать модуль train_test_split библиотеки Scikit-learn, который очень полезен для разделения датасетов, независимо от того, будете ли вы применять Scikit-learn для выполнения других задач машинного обучения. Конечно, можно выполнить такие разбиения каким-либо другим способом (возможно, используя только Numpy). Библиотека Scikit-learn включает полезные функции, позволяющее сделать это немного проще.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.67, random_state=42)Возможно, вы использовали этот модуль для разделения данных в прошлом, но при этом не приняли во внимание некоторые детали.
Случайное перемешивание строк
Первое, на что следует обратить внимание: перемешаны ли ваши экземпляры? Это следует делать пока нет причин не перетасовывать данные (например, они представляют собой временные интервалы). Мы должны убедиться в том, что наши экземпляры не разбиты на выборки по классам. Это потенциально вносит в нашу модель некоторую нежелательную предвзятость.
Например, посмотрите, как одна из версий набора данных iris, упорядочивает свои экземпляры при загрузке:
from sklearn.datasets import load_iris iris = load_iris() X, y = iris.data, iris.target print(f"Классы датасета: ")Классы датасета: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]Если такой набор данных с тремя классами при равном числе экземпляров в каждом разделить на две выборки: 2/3 для обучения и 1/3 для тестирования, то полученные поднаборы будут иметь нулевое пересечение классовых меток. Это, очевидно, недопустимо при изучении признаков для предсказания классов. К счастью, функция train_test_split по умолчанию автоматически перемешивает данные (вы можете переопределить это, установив для параметра shuffle значение False ).
- В функцию должны быть переданы как вектор признаков, так и целевой вектор (X и y).
- Для воспроизводимости вы должны установить аргумент random_state .
- Также необходимо определить либо train_size , либо test_size , но оба они не нужны. Если вы явно устанавливаете оба параметра, они должны составлять в сумме 1.
Вы можете убедится, что теперь наши классы перемешаны.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.67, random_state=42) print(f"Классы в y_train:\n") print(f"Классы в y_test:\n")Классы в y_train: [1 2 1 0 2 1 0 0 0 1 2 0 0 0 1 0 1 2 0 1 2 0 2 2 1 1 2 1 0 1 2 0 0 1 1 0 2 0 0 1 1 2 1 2 2 1 0 0 2 2 0 0 0 1 2 0 2 2 0 1 1 2 1 2 0 2 1 2 1 1 1 0 1 1 0 1 2 2 0 1 2 2 0 2 0 1 2 2 1 2 1 1 2 2 0 1 2 0 1 2] Классы в y_test: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1 0 0 0 2 1 1 0 0 1 2 2 1 2]Стратификация (равномерное распределение) классов
Данное размышление заключается в следующем. Равномерно ли распределено количество классов в наборах данных, разделенных для обучения и тестирования?
import numpy as np print(f"Количество строк в y_train по классам: ") print(f"Количество строк в y_test по классам: ")Количество строк в y_train по классам: [31 35 34] Количество строк в y_test по классам: [19 15 16]Это не равная разбивка. Главная идея заключается в том, получает ли наш алгоритм равные возможности для изучения признаков каждого из представленных классов и последующего тестирования результатов обучения, на равном числе экземпляров каждого класса. Хотя это особенно важно для небольших наборов данных, желательно постоянно уделять внимание данному вопросу.
Мы можем задать пропорцию классов при разделении на обучающий и проверяющий датасеты с помощью параметра stratify функции train_test_split . Стоит отметить, что мы будем стратифицировать в соответствии распределению по классам в y .
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.67, random_state=42, stratify=y) print(f"Количество строк в y_train по классам: ") print(f"Количество строк в y_test по классам: ")Количество строк в y_train по классам: [34 33 33] Количество строк в y_test по классам: [16 17 17]Сейчас это выглядит лучше, и представленные числа говорят нам, что это наиболее оптимально возможное разделение.
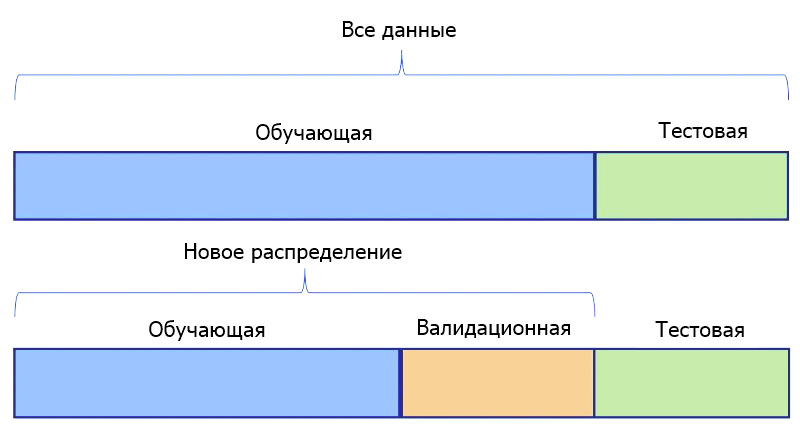
Дополнительное разделение
Третье соображение относится к проверочным данным (выборке валидации). Есть ли смысл для нашей задачи иметь только один тестовый датасет. Или мы должны подготовить два таких набора — один для проверки наших моделей во время их точной настройки, а еще один — в качестве окончательного датасета для сравнения моделей и выбора лучшей.
Если мы определим 2 таких набора, это будет означать, что одна выборка, будет храниться до тех пор, пока все предположения не будут проверены, все гиперпараметры не настроены, а все модели обучены для достижения максимальной производительности. Затем она будет показана моделям только один раз в качестве последнего шага в наших экспериментах.
Если вы хотите использовать датасеты для тестирования и валидации, создать их с помощью train_test_split легко. Для этого мы разделяем весь набор данных один раз для выделения обучающей выборки. Затем еще раз, чтобы разбить оставшиеся данные на датасеты для тестирования и валидации.
Ниже, используя набор данных digits, мы разделяем 70% для обучения и временно назначаем остаток для тестирования. Не забывайте применять методы, описанные выше.
from sklearn.datasets import load_digits digits = load_digits() X, y = digits.data, digits.target X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42, stratify=y) print(f"Количество строк в y_train по классам: ") print(f"Количество строк в y_test по классам: ")Количество строк в y_train по классам: [124 127 124 128 127 127 127 125 122 126] Количество строк в y_test по классам: [54 55 53 55 54 55 54 54 52 54]Обратите внимание на стратифицированные классы в полученных наборах. Затем мы повторно делим тестовый датасет.
X_test, X_val, y_test, y_val = train_test_split(X_test, y_test, train_size=0.5, random_state=42, stratify=y_test) print(f"Количество строк в y_test по классам: ") print(f"Количество строк в y_val по классам: ")Количество строк в y_test по классам: [27 27 27 27 27 28 27 27 26 27] Количество строк в y_val по классам: [27 28 26 28 27 27 27 27 26 27]Обратите внимание на стратификацию классов по всем наборам данных, которая является оптимальной.
Теперь вы готовы обучать, проверять и тестировать столько моделей машинного обучения, сколько вы сочтете нужным для ваших данных.Еще один совет: вы можете подумать об использовании перекрестной валидации вместо простой стратегии обучение/тестирование или обучение/валидация/тестирование. Мы рассмотрим вопросы кросс-валидации в следующий раз.