Как удалить wwn targetcli
Устанавливаем пакеты и запускаем службу
yum install targetcli scsi-target-utils -y systemctl enable target.service systemctl start target.serviceОткрываем порт сервиса
firewall-cmd --permanent --zone=public --add-port=3260/tcpЕсли необходимо удалить старую конфигурацию
targetcli clearconfig confirm=truetargetcli cd /backstores/block/ create data /dev/ cd /iscsi create wwn=iqn.XX-X-XX cd /iscsi//tpg1/portals delete 0.0.0.0 3260 create xxx.xxx.xxx.xx ip_port=3260 cd /iscsi//tpg1/luns create /backstores/block/ lun= cd /iscsi//tpg1 set attribute authentication=0 set attribute generate_node_acls=1 set attribute demo_mode_write_protect=0 #set attribute MaxBurstLength cd /iscsi//tpg1/acls create wwn=
Формат IQN имеет вид iqn.yyyy-mm.naming-author:unique-name , где:
yyyy-mm - год и месяц. naming-Authority - это обычно обратный синтаксис имени домена в Интернете организации. unique-name - это любое имя, которое вы хотите использовать, например, имя вашего хоста. iqn.2020-01.ru.tx0.iscsi:dss-12020-2023 | Tixo | info@tx0.ru | Погрузитесь в с Тиксо!
Ошибка targetcli «WWN not valid as: naa» при попытке добавления в ACL конфигурации Linux-IO FC Target хостов FC Initiator с WWPN от виртуальных машин Hyper-V Gen2
В одной из прошлых заметок мы уже упоминали о такой штуке, как Linux-IO (LIO) и показывали пример пакетного использования утилиты targetcli, которая используется для управления конфигурацией FC Target. Использование этой утилиты в типичном сценарии, когда хосты, выступающие в роли FC Initiator, являются физическими и имеют физические адаптеры FC HBA, не вызывает проблем. Однако, если в качестве Initiator мы попробуем добавить в конфигурацию LIO вместо физических FC HBA, виртуальные HBA из виртуальных машин Hyper-V, то здесь нам targetcli может выдать ошибку » WWN not valid as: naa «. В этой заметке мы поговорим о том, почему возникает такая ошибка и как её обойти.
Итак, предположим, у нас есть некая виртуальная машина Hyper-V Gen2, подключённая через технологию NPIV, к сети FC SAN. На эту виртуальную машину мы хотим пробросить какое-то блочное устройство с физического сервера на базе Linux с помощью LIO FC Target. Для этого на стороне Linux-сервера с помощью утилиты targetcli в конфигурации LIO мы пытаемся прописать в лист доступа (ACL) идентификаторы vHBA WWPN виртуальной машины. Делаем это командой типа:
# targetcli /qla2xxx/naa.50014380062e3204/acls create C003FF9BFEE40008
В этом примере идентификатор » C003FF9BFEE40008 » это WWPN vHBA нашей виртуальной машины. И здесь то мы и получим от targetcli ошибку несоответствия указанного идентификатора типу WWN:
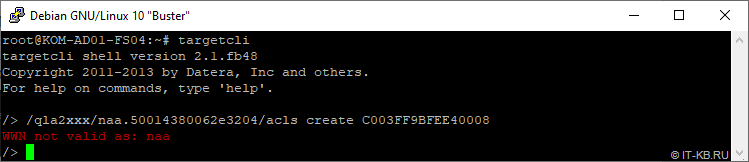
При этом попытки использовать разный регистр и разделители при указании WWPN в этой ситуации нас не спасут.
Исследование проблемы показало, что код исполняемого скрипта /usr/lib/python3/dist-packages/rtslib_fb/utils.py , поставляемого в пакете python3-rtslib-fb и используемого утилитой targetcli, содержит вызов функции normalize_wwn. В этой функции имеется код, определяющий валидность идентификаторов разного типа. В нашем случае эта функция выполняет проверку в соответствии со строкой вида:
'naa': lambda wwn: re.match(r"naa\.[125][0-9a-fA-F]$", wwn),
То есть если указанный нами идентификатор WWN/WWPN будет начинаться с цифровых символов «1«,»2» или «5«, то, скорее всего, мы не столкнёмся с описанной ошибкой. В нашем же случае идентификаторы WWPN vHBA виртуальной машины Hyper-V начинаются с буквенного символа «С«, что и вызывает «негодование» targetcli.
Правильным решением в этой ситуации будет обращение к разработчикам targetcli и исправление этой проблемы на глобальном уровне. Однако, вспоминая свои попытки получить отклик в мейл-группе LIO, можно предположить, что занятие это будет не интересное.
Чтобы решить эту проблему «здесь и сейчас» нам достаточно будет внести небольшую правку в выше обозначенную строчку скрипта utils.py , чтобы она приняла, например, следующий вид:
'naa': lambda wwn: re.match(r"naa\.[0-9a-fA-F]$", wwn),
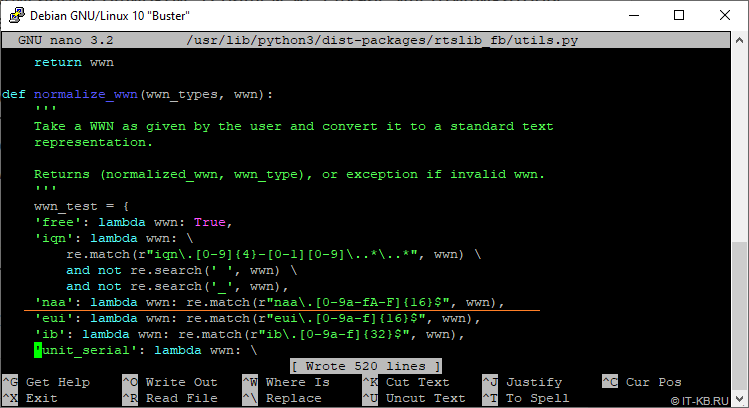
После правки, нужно перезапустить сеанс работы с утилитой targetcli.
При повторной попытке добавления в ACL идентификатора WWPN с виртуальной машины Hyper-V с выше обозначенной ошибкой мы уже не столкнёмся.
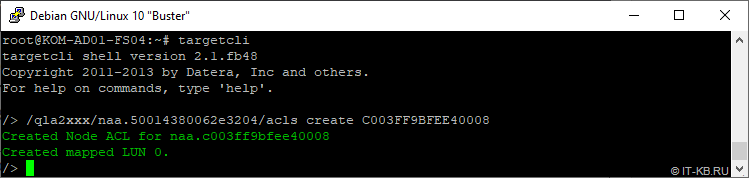
На самом деле с описанной проблемой скрипта utils.py я столкнулся ещё примерно полтора года назад при использовании пакета python3-rtslib-fb из репозиториев Debian 9, но отложил написание этой заметки «на потом». Но чуда за это время не произошло и «болячка не рассосалась».
Как удалить wwn targetcli
FC использует свою адресацию, поэтому для указания, с таким устройством работать, используется WWN (World Wide Name, параметр node_name (есть ещё port_name (WWP), но они отличаются, хотя и похожи)):
# в "чистом" виде $ cat /sys/class/fc_host/host10/node_name # в виде, xx:xx:xx. (только без последней ':') $ cat /sys/class/fc_host/host10/node_name | awk -F'x' '$2>' | while read a ; do echo $a | sed 's/../&:/g'; done; # или через утилиту systool $ systool -av -c fc_host | grep -i node_name | awk '$NF>' | awk -F'x' '$2>' | sed 's/\"//g' | while read a ; do echo $a | sed 's/../&:/g'; done; где host10 — наше целевое устройство. Можно посмотреть в каталоге /sys/class/fc_host/, либо через утилиту systool:
$ systool -av -c fc_host Если необходимо узнать WWN адаптера, доступной по Fibre Channel, то информацию можно найти в каталоге:
$ ls /sys/class/fc_remote_ports/ rport-6:0-2 , где rport-6:0-2 — один из доступных (в примере — только один) HBA.
Непосредственно WWN адаптера:
$ cat /sys/class/fc_remote_ports/rport-6\:0-2/port_name 0x210000e08b175d35 б) HBA Emulex
1 — ПРОГРАММЫ УПРАВЛЕНИЯ, ПРОШИВКИ
Первоначально скачиваем с сайта Emulex необходимые пакеты:
1) Application Kit 10.2.370.16 (GUI / CLI) — я скачивал GUI, поставил его и с ним работал, но не понял, как запустить саму GUI — работал через CLI;
2) Linux Elxflash Online Utility 10.2.370.19;
3) прошивки для своих карт: у меня LPE12000, поэтому скачивал:
3.1) Firmware 2.01a12;
3.2) Universal Boot.
Вначале устанавливаем Application Kit. Для этого понадобится немного подправить install.sh, т.к. установка на Fedora Linux не предусмотрена.
В моём случае пришлось строки 514-515 исправить, указав, что у меня RHEL7:
# было $ rhel_major_version=`cat /etc/redhat-release | awk -F'.' '$1>' | awk '$NF>'` $ rhel_minor_version=`cat /etc/redhat-release | awk -F'.' '$2>' | cut -d' ' -f1` # стало rhel_minor_version=0 rhel_major_version=7 Запускаем исправленный install.sh и ставим утилиту.
После этого лучше сразу обновить карту последними прошивками: для это и нужны Linux Elxflash Offline, Firmware и Universal Boot.
Распаковываем Linux Elxflash Online ( ../x86_64/rhel-7/elxflashOnline-10.2.370.19 ), во вложеные каталоги ./boot и ./firmware распаковываем содержимое Universal Boot и Firmware и запускам эту утилиту:
# просмотр доступных обновлений, оценка необходимости обновлений $ ./elxflash /auto /log=elxflash.log /update /preview Sat Sep 20 22:39:28 2014 HBA=LPe12000, Port Type=FC, WWN=10:00:00:90:FA:1A:D2:01, Update=Firmware, Image=ud201a12.all, New=201A12, Old=201A9, Status=Preview Sat Sep 20 22:39:28 2014 HBA=LPe12000, Port Type=FC, WWN=10:00:00:90:FA:1A:D2:01, Update=Boot Code, Image=UU513a3.prg, New=513A3, Old=512A11, Status=Preview elxflash: All required updates succeeded - Return Code=0 # прошивка FirmWare и Boot $ ./elxflash /auto /log=elxflash.log /update Sat Sep 20 22:40:26 2014 HBA=LPe12000, Port Type=FC, WWN=10:00:00:90:FA:1A:D2:01, Update=Firmware, Image=ud201a12.all, New=201A12, Old=201A9, Status=Success Sat Sep 20 22:40:45 2014 HBA=LPe12000, Port Type=FC, WWN=10:00:00:90:FA:1A:D2:01, Update=Boot Code, Image=UU513a3.prg, New=513A3, Old=512A11, Status=Success elxflash: All required updates succeeded - Return Code=0 Более подробное описание параметров доступны в «хелпе», а примеры — в файле ./lcreflsh.sh.
2 — УПРАВЛЕНИЕ HBA
Для управления Emulex HBA используется утилита hbacmd, входящая в состав ранее установленного пакета Application Kit.
Выбор топологии:
# по умолчанию: 0 (0 - кольцо и точка-точка, 2 - точка-точка, 4 - кольцо, 6 - точка-точка и кольцо) $ echo "2" > /sys/class/scsi_host/host6/lpfc_topology где host6 — номер устройства, которое можно определить из:
$ ls -ld /sys/bus/pci/drivers/lpfc/*/host* hbacmd — утилита управления HBA Emulex из пакета пакета OneCommand:
# Просмотр списка установленных Emulex HBA $ hbacmd listhbas # статистика работы $ hbacmd portstat # атрибуты HBA $ hbacmd hbaattrib # атрибуты порта $ hbacmd portattrib # перезапуск карты $ hbacmd reset
в) HBA QLogic
По умолчанию FC HBA стартует в режиме инициатора (initiator mode), поэтому надо карту при инициализации перевести в режим цели (target mode).
Для этого есть два варианта:
1) дописать в параметры ядра ещё один (и перегрузиться, конечно):
qla2xxx.qlini_mode=disabled 2) создать файл /etc/modprobe.d/qla2xxx.conf с такой строкой:
options qla2xxx qlini_mode=disabled При использовании второго варианта надо помнить, что данного вида карты инициализируются на очень раннем этапе загрузки, когда ещё «работает» образ initrd, то просто перезагрузка ничего не даст — необходимо пересобрать initrd, чтобы инициализация прошла:
# с Fedora 10 есть такой вариант $ /usr/libexec/plymouth/plymouth-update-initrd # более современный вариант $ dracut -f Проверка, что карта в нужном режиме:
$ cat /sys/module/qla2xxx/parameters/qlini_mode disabled Кроме данного параметра можно, при установке 2-х карт включить , указав соответствующий параметр ядра:
ql2xfailover=1 ConfigRequired=0 , где ql2xfailover — поддержку fallover-режима (активное резервирование при установке не менее 2-х плат HBA); ConfigRequired — указывает, как осуществлять привязку (bind) устройств: 0 — всех обнаруженных ОС, 1 — только устройств, определённых в файле /etc/qla2xxx.conf (по умолчанию: 0).
Более подробно о параметрах драйвера qla2xxx.ko.
К сожалению, параметр ql2xfailover можно использовать не всегда: во многих дистрибутивах в сборках qla2xxx этот функционал исключают (как и FC-target). Почему — могу только догадываться: возможно, чтобы не создавать конкуренцию дорогим решениям. Надо, при случае, попробовать собрать драйвер самому по данной инструкции: How to Configure the FC QLogic Target Driver for 22xx/23xx/24xx/25xx/26xx Adapters.
Управлять FC будем с помощью Linux SCSI Target (LIO), используя программу управления targetcli:
$ yum install targetcli И запустим службу восстановления конфигурации (Restore LIO kernel target configuration):
$ systemctl enable target.service $ systemctl start target.service Теперь вся работа — утилитой targetcli:
$ targetcli /> Если после запуска мы будет находиться не в корне (например, /qla2xxx), то выйдем на него:
# команда cd - аналогичная системной /qla2xxx> cd / # или только указанием пути /qla2xxx> / Посмотрим исходное состояние:
/> ls o- / . [. ] o- backstores . [. ] | o- block . [Storage Objects: 0] | o- fileio . [Storage Objects: 0] | o- pscsi . [Storage Objects: 0] | o- ramdisk . [Storage Objects: 0] o- iscsi . [Targets: 0] o- loopback . [Targets: 0] o- qla2xxx . [Targets: 0] o- sbp . [Targets: 0] o- vhost . [Targets: 0] Ветка qla2xxx — это указание наличия FC карты QLogic и её поддержки в системе.
Запросим информацию по этой ветке:
/> cd qla2xxx/ info Fabric module name: qla2xxx ConfigFS path: /sys/kernel/config/target/qla2xxx Allowed WWN types: naa Allowed WWNs list: naa.2100001b32180465 Fabric module features: acls Corresponding kernel module: tcm_qla2xxx Создадим объект хранилища для нашей будущей Цели (target):
# сразу, с указанием полного пути (в дальнейшем) /> /backstores/block/ create disk1tb /dev/md125 Created block storage object disk1tb using /dev/md125. В примере устройство /dev/md125 — программный RAID массив.
Создаём саму Цель:
/> /qla2xxx create naa.2100001b32180465 Created target naa.2100001b32180465. где 2100001b32180465 — WWN карты Fibre Channel, установленной в системе, берётся из вывода info узла /qla2xxx (см.выше).
Создаём лист доступа (ACL, access control list) с WWN карт, имеющих доступ к данной:
/> /qla2xxx/naa.2100001b32180465/acls create 210000e08b175d35 Created Node ACL for naa.210000e08b175d35 Привязываем ранее созданное блочное устройство к Цели:
/> /qla2xxx/naa.2100001b32180465/luns create /backstores/block/disk1tb Created LUN 0. Created LUN 0->0 mapping in node ACL naa.210000e08b175d35 Смотрим результат наших операций:
/> ls o- / . [. ] o- backstores . [. ] | o- block . [Storage Objects: 1] | | o- disk1tb . [/dev/md125 (931.4GiB) write-thru activated] | o- fileio . [Storage Objects: 0] | o- pscsi . [Storage Objects: 0] | o- ramdisk . [Storage Objects: 0] o- iscsi . [Targets: 0] o- loopback . [Targets: 0] o- qla2xxx . [Targets: 1] | o- naa.2100001b32180465 . [gen-acls] | o- acls . [ACLs: 1] | | o- naa.210000e08b175d35 . [Mapped LUNs: 1] | | o- mapped_lun0 . [lun0 block/disk1tb (rw)] | o- luns . [LUNs: 1] | o- lun0 . [block/disk1tb (/dev/md125)] o- sbp . [Targets: 0] o- vhost . [Targets: 0] Если всё устраивает, сохраняем конфигурацию (специально, если отключено автоматическое сохранение (по умолчанию)):
/> saveconfig Last 10 configs saved in /etc/target/backup. Configuration saved to /etc/target/saveconfig.json Указывается, что текущая конфигурация сохранена в /etc/target/saveconfig.json, а в /etc/target/backup находятся 10 предыдущих вариантов.
Если возникает желание/необходимость что-то удалить, переходим в нужную ветку дерева и удаляем, например, LUN:
/> /qla2xxx/naa.2100001b32180465/luns delete lun0 Deleted LUN 0. Теперь посмотрим, доступен ли наш LUN на целевой системе, Инициаторе, пересканировав доступные LUN:
# через шину SCSI $ echo "- - -" > /sys/class/scsi_host/hostX/scan # через Fibre channel $ echo "1" > /sys/class/fc_host/hostX/issue_lip где X — номер нашего FC HBA.
Смотрим, доступен ли соответствующий LUN в системе Инициатора:
$ lsscsi | grep -iE lio [6:0:0:0] disk LIO-ORG disk1tb 4.0 /dev/sdf Чтобы добавить одно заданное устройство, выполним:
$ echo "scsi add-single-device " > /proc/scsi/scsi Чтобы удалить заданное устройство, выполним:
$ echo "scsi remove-single-device " > /proc/scsi/scsi где H> B> T> L> — это хост, шина, целевой номер устройства и логический номер (host, bus, target, LUN) соответственно. Соответствующие устройству номера можно найти в каталоге /sys (только для ядер версии 2.6), файле /proc/scsi/scsi или выводе команды dmesg.
Удалить (отключить) LUN:
# через устройство /dev/sdX $ echo 1 > /sys/block/sdf/device/delete $ lsscsi | grep -iE lio 2. Infiniband
Infiniband — сравнительно молодой интерфейс, идея создания которого была в замене современной сетевой инфраструктуры Ethernet и Fibre Channel.
а) Общая информация по настройке
б) HCA: QLogic
в) HCA: Mellanox
3. iSCSI
4. Программный RAID
а) Создание RAID-массива
Для работы с программным RAID в Linux используется утилита mdadm. Создание с её помощью массива RAID1:
$ mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb /dev/sdc Сканирование системы на наличие массивов и вывода информации по ним (в форме для добавления в файл конфигураций /etc/mdadm/mdadm.conf):
$ mdadm --detail --scan --verbose ARRAY /dev/md0 level=raid1 num-devices=2 metadata=1.2 name=fmhstar.homed.local:0 UUID=3d274916:ce690922:3d669a74:7500515c devices=/dev/sdb,/dev/sdc б) Мониторинг состояния массива
Состояние RAID-массива отслеживается через файл /proc/mdstat:
# единичный просмотр $ cat /proc/mdstat # просмотр изменяющегося состояния, например, при пересборке массива $ watch cat /proc/mdstat Информация о конкретном дисковом разделе:
$ mdadm -E /dev/sdb2 Мониторинг состояния массива — разовая проверка:
$ mdadm --monitor --scan -1 --mail=postmaster@mydomain.ru Для постоянной периодической проверки эту команду надо внести в файл, например, mdRAIDmon, размещённый в папке /etc/cron.haurly/.
Или, для пятиминутной проверки внести в файл /etc/crontab следующую строку:
*/5 * * * * root run-parts /etc/cron.my5min Проверки работы системы оповещения:
$ mdadm --monitor --scan -1 --mail=postmaster@domain.name.ru --test в) Работа с разделами на RAID-массиве
Удаление LVM и RAID, где он размещён:
# вывод всех доступных групп томов (volume group) $ vgdisplay # удаление группы томов fedora-server $ vgremove fedora-server # вывод всех доступных физических томов (physical volume) $ pvdisplay # удаление физического тома /dev/md127 $ pvremove /dev/md127 Иногда после данных информация о томах всё ещё отображается, поэтому переподключить массив или перезагрузить сиситему.
г) Поддержка bitmap
Включение поддержки bitmap с хранением:
$ mkdir /RAID/ # на внешней ФС $ mdadm --grow --bitmap=/RAID/md0_3tb /dev/md0 # внутри этого же массива $ mdadm --grow --bitmap=internal /dev/md0 Просмотр включенных bitmap:
$ mdadm --examine /dev/sda2|grep Bitmap Отключение на RAID-массиве использование bitmap:
$ mdadm --grow --bitmap=none /dev/md1 Параметр bitmap в свойствах массива означает добавление дополнительной информации для восстановления RAID в случае сбоев. Сборка массива при замене жёсткого диска будет происходить быстрее, но общая производительность массива снизится примерно на 5% в случае размещения bitmap на том же диске, что и RAID или в самом RAID-массиве (по умолчанию).
д) Замена сбойных дисков
Выяснить, какой диск сбойный:
# cat /proc/mdstat
Подробная информация:
# mdadm -D /dev/mdX
где X — номер массива
Восстановление функционирования (rebuild) разделов диска по одному после однократного «несмертельного» сбоя:
# mdadm -a /dev/md /dev/sd
например:
# mdadm -a /dev/md0 /dev/sdb1
Нужно быть аккуратным с номерами разделов
В случае ошибки, удалить компонент из RAID командой:
# mdadm -r /dev/md0 /dev/sdb1
получается не всегда — устройство может быть занято.
Замена диска:
1) выключить компьютер и заменить диск;
2) включить компьютер и определить имеющиеся на обоих дисках разделы:
# fdisk /dev/sd -l
3) с помощью fdisk создать на новом диске разделы, идентичные оригиналу Необходимо пометить нужный раздел нового диска (sda1 или sdb1) как загрузочный до включения в зеркало.
Swap-разделы не подлежат зеркалированию в программном RAID.
е) Очистка дисков от метаданных RAID
Отмонтируем все разделы, размещённые на удаляемом RAID и остановим этот массив:
$ umount /dev/md0 $ mdadm --stop /dev/md0 Стираем суперблок, хранящий информацию о массиве, на всех дисках, входящих в удаляемый массив:
$ mdadm --zero-superblock /dev/sde1 $ mdadm --zero-superblock /dev/sdf1 Если не получилось, то делаем прямым затиранием:
$ dd if=/dev/zero of=/dev/sde1 bs=512 count=1 $ dd if=/dev/zero of=/dev/sdf1 bs=512 count=1 Выключаем систему, отключаем девственно чистые диски. :\
5. Работа с LVM
а) Отключение/подключение диска с LVM
Это требуется, например, после подключения диска с LVM к системе через, например, USB конвертер. Если отключать диск без некоторых дополнительных действий, то в системе останутся «зависшими» подключения, что может вызвать некоторые проблемы.
Для отключения надо:
1) отмонтировать все разделы на этом диске;
2) выполнить команду:
$ lvchange -an
3) удаляем блочное устройство (в современных системах происходит автоматически, но вдруг понадобится) /dev/sdf:
$ echo 1 > /sys/block/sdf/device/delete Всё, можно отключать питание.
Если LVM не подключается автоматически, то вручную это делается так (для устройства hostX, где X — номер в системе):
$ echo "- - -" > /sys/class/scsi_host/hostX/scan $ lvchange -ay
Теперь можно монтировать.
б) Создание томов LVM
Посредством утилиты fdisk создаём (описано в предыдущем пункте) на новом диске таблицу разделов и раздел на нём.
Создание новых томов (физического, группы и логического) на дополнительном диске /dev/sdb:
# Создание физического тома $ pvcreate /dev/sdb1 # Создание и инициализация группы томов $ vgcreate new-vg /dev/sdb1 $ vgchange -a y new-vg # создаём и форматируем под XFS логический том $ lvcreate -l +100%FREE -n new-lv new-vg $ mkfs.xfs /dev/new-vg/new-lv Добавляем новую запись к файл /etc/fstab и на этом заканчивается настройка.
в) Восстановление удалённых томов
Если случайно был удален том LVM (или специально, но потом понадобилось восстановление) — механизм резервного копирования метаданных volume group может спасти ситуацию.
Настройка архивирования находится в файле /etc/lvm/lvm.conf в секции backup.
По умолчанию архивирование включено, папка для архивов — /etc/lvm/archive и содержит архивы изменения vg за 30 дней.
Посмотреть чего менялось можно командой
$ vgcfgrestore -l VG . skipped . File: /etc/lvm/archive/VG_00393.vg VG name: VG Description: Created *before* executing 'lvremove /dev/VG/lv_name_4' Backup Time: Mon Oct 15 16:23:20 2012 File: /etc/lvm/archive/VG_00394.vg VG name: VG Description: Created *before* executing 'lvcreate -L20g -nsome_new_lv VG' Backup Time: Tue Oct 16 00:32:40 2012 Здесь видно имя файла архива и команда, перед (или иногда после) которой архивирование метаданных VG было выполнено.
В данном случае были удалены некоторые LV и после них создан новый.
Чтобы узнать, попал новый LV поверх старых (тогда естественно данные будут перезаписаны, зависит от количества записей в новый LV) надо посмотреть в архиве до удаления параметры extent_count и stripes нужного LV. stripes это номер начала блока на PV, extent_count — количество.
LV может состоять из нескольких сегментов, в каждом будет свой набор extent_count и stripes.
Потом посмотреть эти же параметры нового LV, но в архиве поcле создания нового LV.
Если эти регионы не пересеклись — значит новый LV создался в другом месте, чем удаленные LV.
Восстановление метаданных:
$ vgcfgrestore -f /etc/lvm/archive/VG_00390.vg VG это откатит все изменения с текущего момента до нужного архива, предшествующего указанной в vgcfgrestore -l команде.
Дальше остается только активировать восстановленные LV командой
$ lvchange -a y /dev/VG/lv_name г) Изменение размеров томов
Изменение размеров физического тома — задача весьма сложная и обычно не применяется. Безопаснее либо удалить физический том, изменить размер раздела и создать том заново, либо (как в данном примере) создать на доступном свободном пространстве дополнительный физический том и объединить его в группу томов, для которых требуется расширение.
При необходимости увеличить доступный объём дискового пространства на, например, корневом разделе, необходимо воспользоваться имеющимся функционалом LVM:
1) смотрим (например, утилитой fdisk) (пакет util-linux), где у нас есть свободное место на подключённых накопителях:
$ fdisk -l Предположим, что у нас есть /dev/sda1 — загрузчик (т.е. /boot) и /dev/sda2 — собственно корень системы (т.е. /) и имеет формат Linux LVM. И на том же диске есть ещё свободное неразделённое место.
2) формируем новый раздел на свободном месте накопителя (в данном случае /dev/sda) новый раздел в интерактивном режиме:
$ fdisk /dev/sda На запрос «Команда (m для справки)» жмём n (создание нового раздела), p (первичный раздел), 3 (номер нового раздела: 1 и 2 уже есть, новый будет /dev/sda 3 ), начальный и конечный блок оставляем как есть (или указываем необходимый объём, если будем использовать не всё доступное пространство).
После создания раздела необходимо указать его тип «Linux LVM»: наживаем t, затем выбираем созданный раздел (наш — 3) и указываем его тип — 8e.
Затем p (просмотреть созданные изменения): если всё устраивает — w (записать изменения и выйти), если не устраивает перенастраиваем или жмём q (выйти без изменений) и всё заново.
Внесённые изменения ещё не известны ядру, поэтому сообщаем ядру, чтобы оно приняло изменения, командой:
$ partprobe Создаём новый физический том на созданном разделе:
$ pvcreate /dev/sda3 Смотрим, на какой группе томов расположен корневой раздел /dev/sda2:
$ pvdisplay | grep -A 1 "/dev/sda2" PV Name /dev/sda2 VG Name lvmpart Добавляем к этой группе созданный нами раздел /dev/sda3:
$ vgextend lvmpart /dev/sda3 Смотрим путь, по которому доступен целевой логический том:
$ lvdisplay | grep -A 1 -B 1 " root" LV Path /dev/lvmpart/root LV Name root VG Name lvmpart Выделяем целевому тому необходимое место:
# всё свободное $ lvextend -l +100%FREE /dev/lvmpart/root # Дополнительно 5 ГиБ $ lvextend -L +5G /dev/lvmpart/root В качестве альтернативного пути может быть использован любой:
1) через mapper: /dev/mapper/lvmpart-root;
2) через любой путь в каталоге /dev/disk/.
Теперь остаётся изменить размер файловой системы, размещённой на целевом логическом томе. Это производится для каждой файловой системы по своему:
# для XFS - по точке монтирования $ xfs_growfs / # для EXT2/EXT3/ETX4 - по устройству $ resize2fs -z old_LVM.e2undo /dev/lvmpart/root # для RaiserFS - по устройству $ resize_reiserfs /dev/lvmpart/root Кроме этого изменение размера: XFS — в примонтированном состоянии, EXT x — не имеет значения (но отмонтированно представляется более безопасным для данных вариантом),
Для EXT x есть возможность (и она использована в примере) создания файла отката вносимых изменений: в представленном варианте — old_LVM.e2undo. В случае необходимости изменения отменяются утилитой e2undo (пакет e2fsprogs):
$ e2undo old_LVM.e2undo /dev/lvmpart/root Для увеличения размера целевой файловой системы всё сделано.
При необходимости уменьшить размер всё производится в обратном порядке, но действия производятся только на размонтированных файловых системах. Т.е., в случае с корневым разделом надо предварительно загрузиться с LiveCD с поддержкой LVM2. ВАЖНО!: операция уменьшения невозможна для XFS.
#=-- EXTx # 1) размонтируем $ umount /home # 2) проверим на ошибки $ e2fsck -f /dev/lvmpart/home # 3а) изменние командой e2fsadm # уменьшить на 1 ГБ $ e2fsadm -L -1G /dev/lvmpart/home # установить размер 5 ГБ $ e2fsadm -L 5G /dev/lvmpart/home # 3б) изменние вручную $ resize2fs -p /dev/lvmpart/home 5G $ lvreduce -L 5G /dev/lvmpart/home # 4) снова проверим на ошибки $ e2fsck -f /dev/lvmpart/home # 5) монтируем обратно $ mount /home #=-- ReiserFS $ umount /home $ resize_reiserfs -s-1G /dev/lvmpart/home $ lvreduce -L-1G /dev/lvmpart/home $ mount -t reiserfs /dev/lvmpart/home /home Теперь вносим изменения в группы томов и физические тома.
д) Дополнительная информация
6. Некоторые особенности настройки FreeNAS 10
Смена пароля root через CLI:
unix::> account user root unix::/account/user/root> set password=
Так же надо назначить IP адрес:
# смотрим все доступные интерфейсы unix::> network interface show # выбираем требуемый интерфейс unix::> network interface re0 # настраиваем и "поднимает" его unix::/network/interface/re0> set ipv6_disable=yes unix::/network/interface/re0> set dhcp=yes unix::/network/interface/re0> set enabled=yes В 10 версии полностью переработаны интерфейсы: и графический (GUI) и консольный (CLI).
Если используется Fibre Channel карта для работы с СХД на базе FreeNAS, то для создания и презентации соответствующего LUN надо использовать ctladm. По сути: в интерфейсе WebGUI настраивается iSCSI, а для работы активировать FC интерфейс:
# Просмотр всех доступных интерфейсов $ ctladm port -l # Активация FC-карты $ ctladm port -o on -t fc Хорошо поддерживаются FC-карты QLogix (устройство isp X ).
размещено: 2012-08-03,
последнее обновление: 2019-09-03,
автор: Fomalhaut
Комментарии пользователей [1 шт.]
Alex, 2018-11-12 в 16:01:24
Использование сервера с FC HBA QLogic на базе Debian GNU/Linux 9.3 и SCST в качестве СХД для томов CSV в кластере высоко-доступных виртуальных машин Hyper-V

Имеем удалённую площадку с одним хостом виртуализации на базе гипервизора Hyper-V (Windows Server 2012 R2) и пачкой виртуальных машин, запущенных на этом хосте. Всё работает, но есть желание хоть как-то повысить доступность виртуальных машин, так как в периоды обслуживания хоста возникает необходимость выключения всех ВМ, что в некоторых ситуациях приводит к нежелательным последствиям. Логичным решением здесь выступает построение, как минимум, двух-узлового кластера высоко-доступных виртуальных машин Hyper-V на базе Windows Failover Cluster. В таком кластере виртуальные машины должны размещаться на общем дисковом томе Cluster Shared Volumes (CSV), который должен быть доступен обоим хостам виртуализации. То есть, предполагается, что для построения кластера нам потребуется какое-то внешнее дисковое хранилище (СХД), к которому могут быть подключены хосты виртуализации.
Однако в нашем случае СХД на удалённой площадке нет, но есть свободные серверы. В этой заметке мы рассмотрим пример того, как с помощью Debian GNU/Linux 9.3 и свободно-распространяемого ПО Generic SCSI Target Subsystem for Linux ( SCST ) из обычного сервера сделать СХД. В результате у нас появится возможность создать двух-узловой кластер высоко-доступных виртуальных машин Hyper-V с подключением к третьему серверу, который будет использоваться в качестве СХД для организации общего тома CSV.
Конфигурация серверов
Для построения выше обозначенной конфигурации нами будут использоваться три сервера линейки HP ProLiant DL380 старого поколения Gen5. В серверы, помимо их базовой комплектации, дополнительно установлены старые оптические контролеры FC HBA 4G (сейчас такие можно купить «по рублю за чемодан»). Кстати, организовать точку подключения к СХД (Target) в ПО SCST можно и на базе более дешёвых сетевых адаптеров GigEthernet (iSCSI Target), но в данной заметке мы будем строить конфигурацию именно Fibre Channel Target на базе оптического адаптера FC HBA фирмы QLogic и SCST будет настраиваться соответствующим образом.
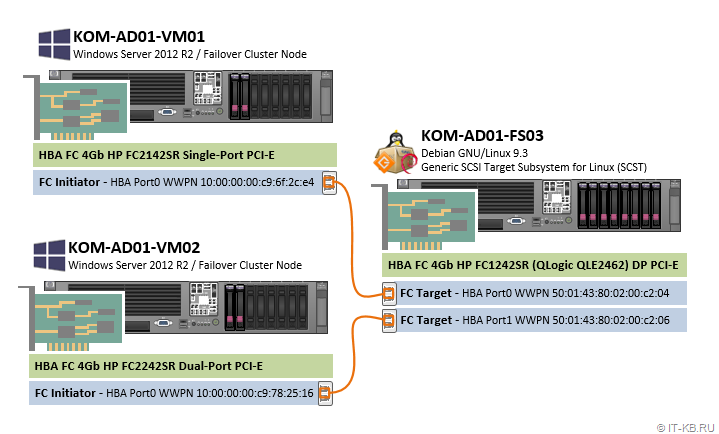
1) Сервер под роль СХД ( KOM-AD01-FS03 )
В сервер установлен двух-портовый адаптер FC 4Gb HP QLogic QLE2462 Dual-Port PCI-Express HBA (407621-001 FC1242SR AE312-60001) (каждый порт используется для подключения к одному из хостов виртуализации). Адресация FC-портов World Wide Port Name (WWPN):
— HBA Port0 WWPN: 50:01:43:80:02:00:c2:04
— HBA Port1 WWPN: 50:01:43:80:02:00:c2:06
В дисковую корзину сервера установлено 8 дисков:
— 2 диска SAS SFF 72GB 15K в RAID1 — под ОС Debian GNU/Linux 9.3 и ПО SCST
— 6 дисков SAS SFF 146GB 15K в RAID1+0 — под кластерные диски, которые будут презентованы хостам виртуализации
2) Хост виртуализации 1 ( KOM-AD01-VM01 )
В сервер установлен одно-портовый адаптер FC 4Gb HP FC2142SR (A8002A) Single-Port PCI-Express HBA (Emulex LPE1150 FC1120005-04C). Адрес HBA Port0 WWPN: 10:00:00:00:c9:6f:2c:e4
В дисковой корзине 2 диска SAS SFF 72GB 15K в RAID1 — под ОС Windows Server 2012 R2
3) Хост виртуализации 2 ( KOM-AD01-VM02 )
В сервер установлен двух-портовый адаптер FC 4Gb HP FC2242SR (A8003A) Dual-Port PCI-Express HBA (Emulex LPE11002 FC1110406-01 Rev.C). Для подключения к серверу KOM-AD01-FS03 используется только один порт. Адрес HBA Port0 WWPN: 10:00:00:00:c9:78:25:16
В дисковой корзине 2 диска SAS SFF 72GB 15K в RAID1 — под ОС Windows Server 2012 R2
Схема подключения оптических адаптеров в нашем примере весьма проста и представляет собой прямое подключение по типу Host-to-Host оптическими патч-кордами multimode 50/125 с коннекторами LC-LC:
В данной заметке мы не будем уделять внимания процедуре построения кластера Hyper-V, как таковой, а сделаем упор на описании процесса настройки FC Target на базе SCST и продемонстрируем дальнейшую возможность использования созданного нами дискового массива в качестве общего тома в кластере Windows Failover Cluster.
Подготовка сервера под роль СХД
Конфигурация выделенного сервера под роль СХД подразумевает ряд действий, которые нам нужно будет последовательно выполнить в дальнейшем. Готовя старый сервер под любую новую задачу, всегда стоит начать с базовой проверки состояния оборудования и обновления всех доступных на данный момент времени прошивок firmware, например, как это было описано ранее в начале заметки Установка CentOS Linux 7.2 на сервер HP ProLiant DL360 G5 с поддержкой драйвера контроллера HP Smart Array P400i .
Если говорить о базовой установке современной версии ОС Debian Linux на аппаратную платформу HP ProLiant DL380 Gen5, то ранее уже было опубликован ряд соответствующих заметок:
- Особенность установки Debian Linux Stretch с подключением firmware из non-free репозиториев (на примере bnx2)
- Установка HPE System Management Tools на сервер с ОС Debian Linux Stretch , а также HP Array Configuration Utility (ACU) для управления устаревшими контроллерами HP Smart Array
Таким образом мы предполагаем, что на сервер KOM-AD01-FS03 уже установлена ОС Debian GNU/Linux 9.3 и утилиты управления HP.
Получаем Firmware для FC HBA QLogic
По умолчанию в Debian нет поддержки firmware QLogic, так как этот тип ПО относится к категории non-free, поэтому установленный в сервер оптический адаптер FC HBA QLogic, который требуется нам для дальнейшей организации FC Target, просто так не заработает. В процессе загрузки системы драйвер, обеспечивающий работу HBA QLogic (модуль ядра qla2xxx), выдаст нам сообщение о невозможности загрузки микрокода HBA » Direct firmware load for ql2400_fw.bin failed with error -2 «:
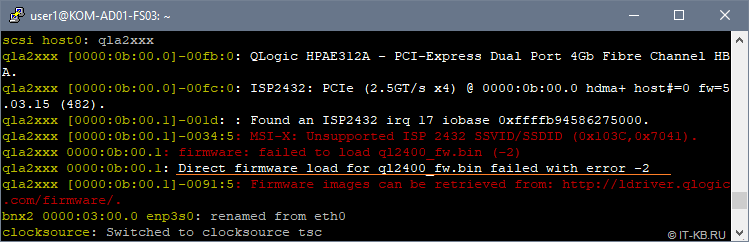
В целом картина по обнаружению и загрузке устройств qla2xxx в нашем случае выглядит так:
# dmesg -t | grep -i qla qla2xxx . QLogic Fibre Channel HBA Driver: 8.07.00.38-k. qla2xxx . Found an ISP2432 irq 16 iobase 0xffffb94586265000. qla2xxx . MSI-X: Unsupported ISP 2432 SSVID/SSDID (0x103C,0x7041). qla2xxx . firmware: failed to load ql2400_fw.bin (-2) qla2xxx . Firmware images can be retrieved from: http://ldriver.qlogic.com/firmware/. scsi host0: qla2xxx qla2xxx . QLogic HPAE312A - PCI-Express Dual Port 4Gb Fibre Channel HBA. qla2xxx . ISP2432: PCIe (2.5GT/s x4) @ 0000:0b:00.0 hdma+ host#=0 fw=5.03.15 (482). qla2xxx . Found an ISP2432 irq 17 iobase 0xffffb94586275000. qla2xxx . MSI-X: Unsupported ISP 2432 SSVID/SSDID (0x103C,0x7041). qla2xxx . firmware: failed to load ql2400_fw.bin (-2) qla2xxx . Direct firmware load for ql2400_fw.bin failed with error -2 qla2xxx . Firmware images can be retrieved from: http://ldriver.qlogic.com/firmware/. scsi host5: qla2xxx qla2xxx . QLogic HPAE312A - PCI-Express Dual Port 4Gb Fibre Channel HBA. qla2xxx . ISP2432: PCIe (2.5GT/s x4) @ 0000:0b:00.1 hdma+ host#=5 fw=5.03.15 (482). qla2xxx . Cable is unplugged. qla2xxx . Cable is unplugged.
Для работы с контроллером HBA QLogic встроенный в Linux драйвер qla2xxx будет пытаться использовать микрокод из каталога /lib/firmware . Поэтому нам нужно обеспечить наличие в этом каталоге совместимой с драйвером версии firmware.
Получить микрокод firmware можно из двух разных мест:
- c сайта QLogic http://ldriver.qlogic.com/firmware/ , скачав соответствующие bin-файлы (в нашем случае, как минимум, требуется файл ql2400_fw.bin) и разместив эти файлы в каталоге /lib/firmware/
- из репозиториев Debian, подключив репозитории non-free и установив пакет qlogic-firmware.
Можно обнаружить то, что микрокод ql2400_fw.bin, доступный на сайте QLogic, судя по описанию CURRENT_VERSIONS имеет версию 7.03.00, в то время, как версия в репозиториях Debian Stretch, судя по описанию к пакету firmware-qlogic , — 8.03.00. Тут может возникнуть соблазн использовать более новую версию прошивки из репозиториев Debian. Однако, нужно учитывать то, что между используемым нами микрокодом HBA и драйвером должна быть обеспечена полная совместимость.
Здесь стоит отдельно остановится на том, почему мы будем использовать описанную далее конфигурацию, в которой вместо поставляемого в составе Debian драйвера qla2xxx будет использоваться предлагаемый разработчиками SCST драйвер qla2x00t. Ведь, казалось бы, использование микрокода, устанавливаемого из пакетов и драйвер, поставляемый в составе Linux, несколько упрощают процедура настройки. Однако, здесь есть несколько «НО».
Во первых такая конфигурация не будет считаться правильной с точки зрения разработчиков SCST, так как свое ПО они разрабатывают именно под свою версию драйвера qla2x00t. Драйвер qla2x00t, который, как я понял, является «форкнутым» несколько лет назад и отлаженным разработчиками SCST драйвером qla2xxx. В ходе изучения этого вопроса, где-то в мейл-листе SCST мне даже попадалась на глаза дискуссия на эту тему, но к сожалению не сохранил ссылку.
Во вторых, использование драйвера qla2x00t, предполагает использование совместимой с ним версии микрокода QLogic. Мои эксперименты показали то, что текущая версия драйвера qla2x00t не приводит к адекватной работе FC Target при условии использования микрокода, поставляемого в пакете firmware-qlogic из репозиториев Debian. Именно поэтому нужно использовать тот микрокод, который доступен на сайте QLogic .
Таким образом, в нашей конфигурации для обеспечения работы FC HBA QLogic под задачу FC Target будет использоваться микрокод с сайта QLogic и драйвер от SCST (qla2x00t).
Скачаем микрокод в каталог /lib/firmware и вызовем процедуру переcборки загружаемого образа initial ramdisk (initrd):
# cd /lib/firmware # wget http://ldriver.qlogic.com/firmware/ql2500_fw.bin # wget http://ldriver.qlogic.com/firmware/ql2400_fw.bin # wget http://ldriver.qlogic.com/firmware/ql2322_fw.bin # wget http://ldriver.qlogic.com/firmware/ql2300_fw.bin # wget http://ldriver.qlogic.com/firmware/ql2200_fw.bin # wget http://ldriver.qlogic.com/firmware/ql2100_fw.bin # update-initramfs -u # reboot
После этого выполним перезагрузку сервера и после загрузки системы снова посмотрим в лог загрузки через утилиту dmesg и убедимся в том, что микрокод HBA успешно загружен в процессе запуска системы

Далее перейдём к отключению встроенного в Linux драйвера qla2xxx.
Отключаем стандартный драйвер qla2xxx
Отключаем стандартный модуль ядра Linux с драйвером qla2xxx, исключаем этот модуль из загрузочного образа initrd и отправляем сервер в перезагрузку:
# rmmod qla2xxx # echo blacklist qla2xxx >/etc/modprobe.d/blacklist-qla2xxx.conf # update-initramfs -u # reboot

После перезагрузки убеждаемся в том, что отключенный ранее модуль действительно не загружен и его сообщений не было в процессе загрузки системы
# lsmod | grep qla # dmesg | grep qla

Как видим, вывод отсутствует, то есть стандартный драйвер qla2xxx успешно отключен и больше не используется.
Получаем исходные коды ядра Linux и SCST
Устанавливаем пакеты, необходимые для сборки и исходные коды используемой у нас версии ядра Linux:
# apt-get install -y linux-headers-$(uname -r) fakeroot kernel-wedge build-essential makedumpfile libncurses5 libncurses5-dev lsscsi patch subversion bc devscripts
Выходим в непривилегированное окружение стандартного пользователя Linux, где будем заниматься правкой и сборкой исходных кодов. Создаём в домашнем каталоге текущего пользователя подкаталог, в котором будем работать с исходниками, например ~/Build , переходим в него и выполняем загрузку исходного кода используемого у нас ядра Linux:
$ mkdir ~/Build $ cd ~/Build $ apt-get source linux-source-4.9
Сюда же, в каталог ~/Build выполняем загрузку исходных кодов актуальной версии SCST:
$ cd ~/Build $ svn co https://svn.code.sf.net/p/scst/svn/trunk scst
Кстати, в моём случае svn не захотел использовать переменные окружения текущего пользователя, описывающие параметры прокси в файле ~/.profile , поэтому на время пришлось открыть машине прямой доступ в интернет.
Посмотрим, что в конечном итоге получилось в нашем сборочном каталоге:
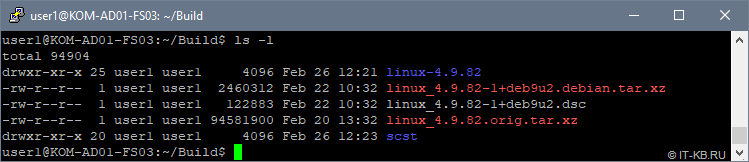
Накладываем патчи SCST на исходные коды ядра Linux
Давайте заглянем в исходные коды SCST и посмотрим то, какие патчи там имеются для ядра Linux используемой у нас 4-ой версии:
$ find ~/Build/scst -name *4.*.patch

Как видим, для нашей версии ядра Linux 4.9 имеется патч nolockdep-4.9.patch , который мы и будем накладывать на исходные коды ядра Linux.
Переходим в каталог с файлами исходных кодов ядра Linux и накладываем патч:
$ cd ~/Build/linux-4.9.82/ $ patch -p1 ~/Build/scst/scst/kernel/nolockdep-4.9.patch
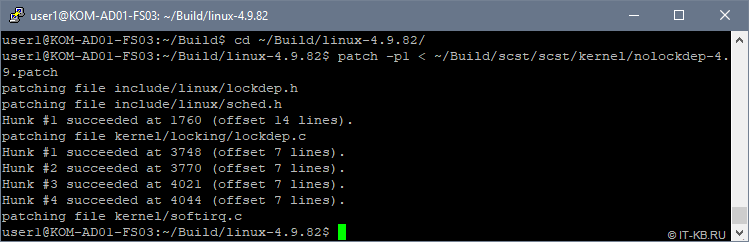
Меняем в исходных кодах ядра драйвер qla2xxx на драйвер от SCST — qla2x00t
Заменяем драйвер в исходниках ядра Linux на тот, что в предлагается в исходниках SCST. Для этого сначала переименуем каталог с оригинальными исходниками драйвера, поставляемыми вместе с исходниками ядра Linux. Затем слинкуем каталог с исходниками драйвера из поставки SCST на имя каталога, которое ранее использовалось исходниками оригинального драйвера
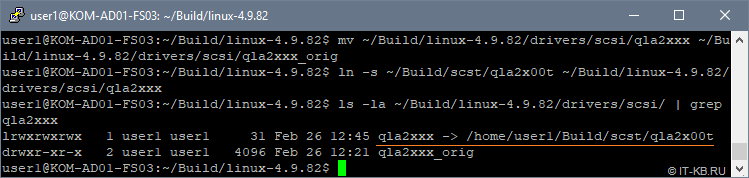
$ mv ~/Build/linux-4.9.82/drivers/scsi/qla2xxx ~/Build/linux-4.9.82/drivers/scsi/qla2xxx_orig $ ln -s ~/Build/scst/qla2x00t ~/Build/linux-4.9.82/drivers/scsi/qla2xxx
Проверим, что получилось:
$ ls -la ~/Build/linux-4.9.82/drivers/scsi/ | grep qla2xxx
Выполняем конфигурацию ядра Linux
Если по какой-то причине Вы собираете 32-битное ядро, то обратите внимание на рекомендации, данные в пункте 11 статьи How to Configure the FC QLogic Target Driver for 22xx/23xx/24xx/25xx/26xx Adapters .
В каталоге с пропатченными исходными кодами ядра запускаем режим конфигурирования параметров ядра
$ cd ~/Build/linux-4.9.82/ $ make menuconfig
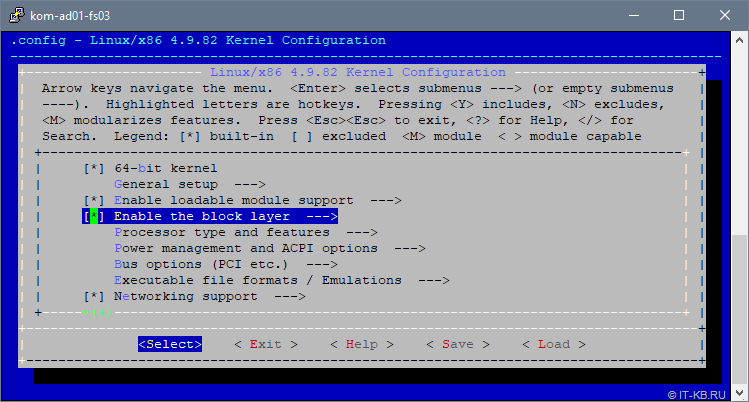
Конфигурация пары описанных далее параметров подсмотрена в статье Linux Fibre Channel SCSI Target using SCST . На самом деле она не является обязательной, но предлагается в качестве дополнительного тюнинга для предположительного улучшения показателей производительности работы Linux с блочными устройствами.
В открывшемся интерактивном режиме настройки параметров ядра перейдём в пункт «Enable the block layer«
В списке опций выберем «IO Schedulers» и удостоверимся в том, что в качестве планировщика по умолчанию «Default I/O Scheduler» выбран вариант «CFQ«:
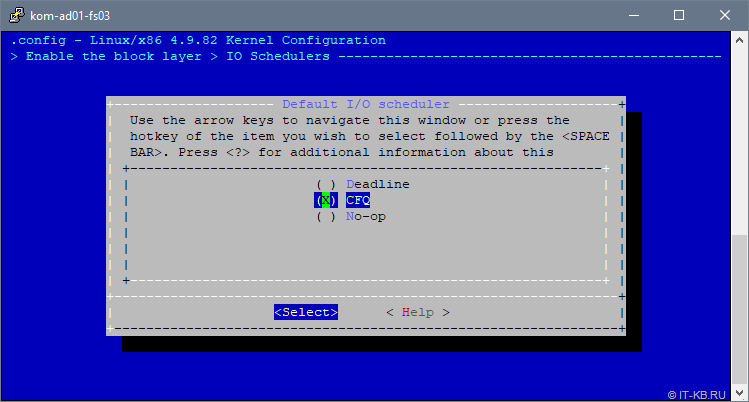
Подробнее про разные типы планировщиков, в том числе и про CFQ, на русском языке можно прочитать, например здесь . А в заметке Linux I/O Scheduler. Выбираем оптимальный можно найти нехитрый скрипт, для проведения экспериментов по самостоятельному выявлению оптимального планировщика.
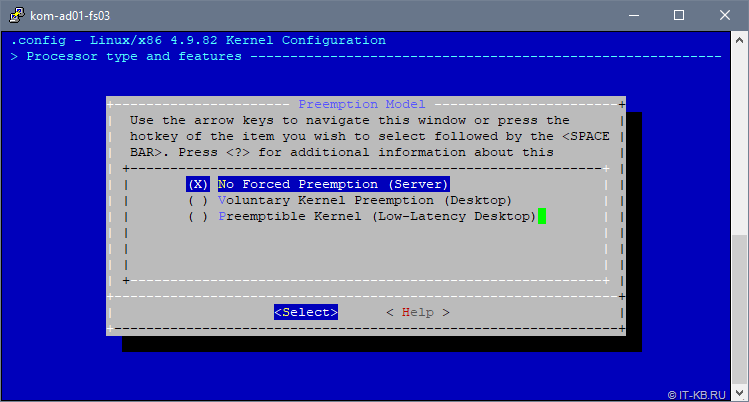
Далее переходим в пункт «Processor type and features» и выбираем опцию «Preemption Model«. Переключаем опцию в значение «No Forced Preemption (Server)»:
Для понимания сути этой опции приведу цитату :
No Forced Preemption (Server) - Это традиционная для Linux модель с приоритетным прерыванием обслуживания (preemption model), она обеспечивает хорошее время отклика (latency), но не дает никаких гарантий, и при её применении возможны случайные длительные задержки. Выбирайте эту опцию, если Вы собираете ядро для сервера или для научных/вычислительных систем, или если Вы хотите увеличить «сырую» вычислительную мощность ядра.
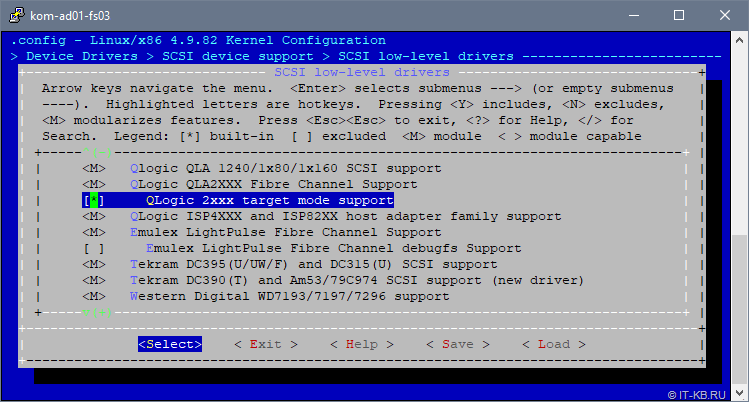
Далее с верхнего уровня переходим последовательно в пункты «Device Drivers» > «SCSI device support» > «SCSI low level drivers» и убеждаемся в том, что для драйвера QLA2XXX присутствует и включена built-in опция «QLogic 2xxx target mode support«
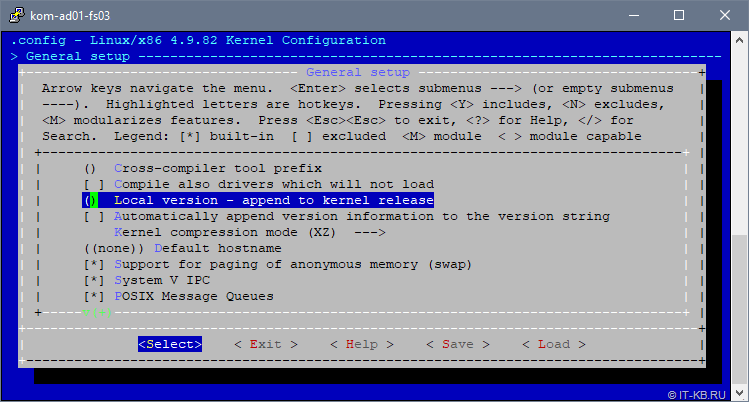
Затем переходим в раздел настроек «General setup» и выбираем пункт «Local version – append to kernel release«, чтобы добавить в имя ядра строку, идентифицирующую наше кастомизированное ядро:
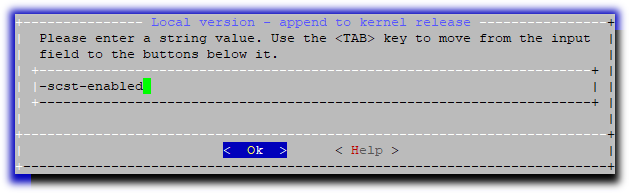
Введём понятный нам постфикс, который будет добавлен к имени ядра при сборке, например «-scst-enabled «
При выходе из интерактивного режима конфигурирования ядра ответим утвердительно на вопрос о сохранении:
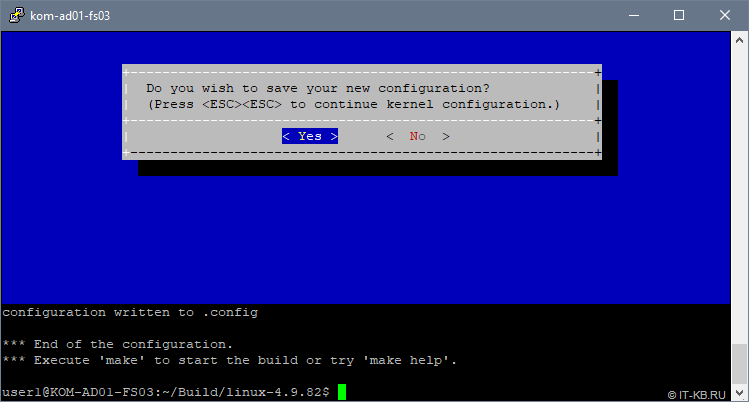
Собираем и устанавливаем ядро Linux
Находясь в текущем каталоге (напоминаю, что мы работаем в каталоге с пропатченными исходными кодами ядра, параметры которого только что были настроены) запускаем процесс компиляции ядра и сборки deb-пакетов:
$ cd ~/Build/linux-4.9.82/ $ make deb-pkg clean
Процесс может занять длительное время, в зависимости от проворности процессора. По окончании процесса мы получим несколько deb-пакетов в каталоге верхнего уровня, относительно каталога компиляции:
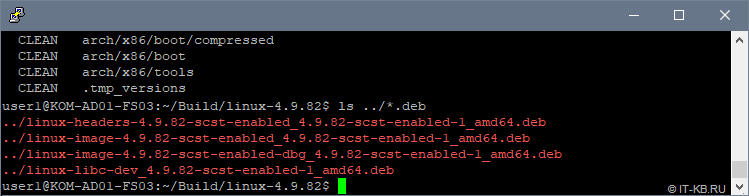
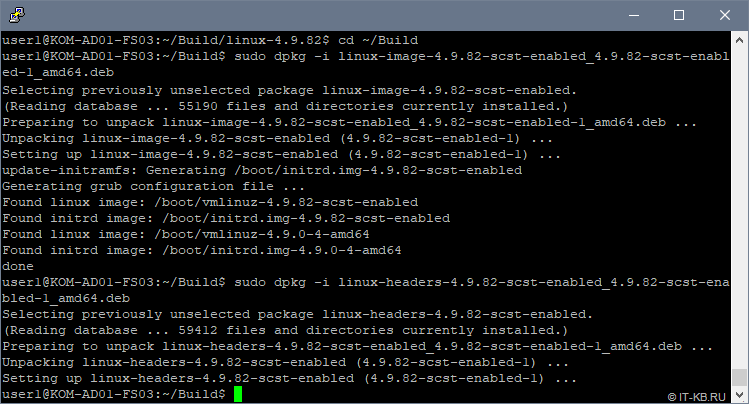
Устанавливаем пакеты нашего кастомизированного ядра Linux:
$ cd ~/Build $ sudo dpkg -i linux-image-4.9.82-scst-enabled_4.9.82-scst-enabled-1_amd64.deb $ sudo dpkg -i linux-headers-4.9.82-scst-enabled_4.9.82-scst-enabled-1_amd64.deb
В ходе установки автоматически будет обновлён загрузочный образ initrd
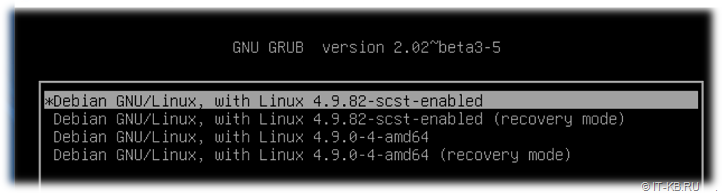
После этого выполняем перезагрузку сервера. В процессе загрузки системы, если заглянем в текущий список ядер в загрузчике GRUB, то увидим, что по умолчанию для загрузки системы используется наше кастомизированное ядро
Для того, чтобы собранное нами кастомизированное ядро Linux не обновилось в дальнейшем в процессе обновления всех пакетов системы (не было заменено в загрузчике новой версией ядра из пакета linux-image-amd64), настроим исключение для менеджера пакетов apt.
# dpkg --get-selections | grep -E "linux-(image|headers)" # apt-mark hold linux-image-amd64
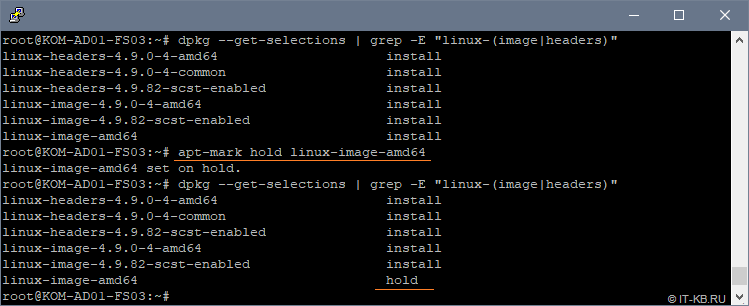
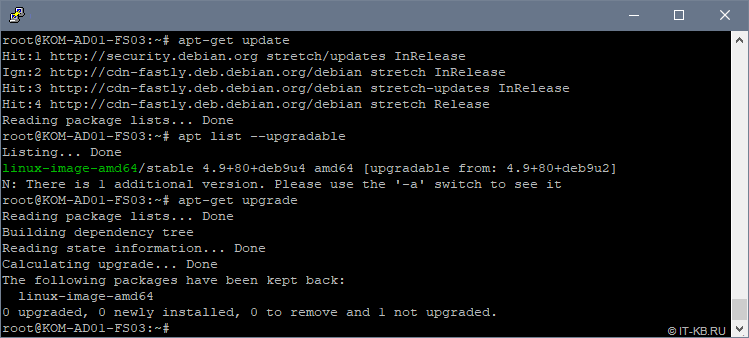
Теперь давайте попробуем выполнить обновление кеша менеджера пакетов и убедимся в том, что не смотря на то, что новая версия пакета linux-image-amd64 в репозиториях присутствует, при установке обновлений данный пакет не устанавливается, так как ранее мы его пометили в hold:
# apt-get update # apt list --upgradable # apt-get upgrade
С ядром закончили, переходим к сборке SCST.
Компилируем и устанавливаем SCST
Переходим в каталог с исходными кодами SCST, компилируем и устанавливаем SCST:
$ cd ~/Build/scst/ $ make 2release $ sudo BUILD_2X_MODULE=y CONFIG_SCSI_QLA_FC=y CONFIG_SCSI_QLA2XXX_TARGET=y make all install
После окончания компиляции и установки убедимся в том, что нужные нам для работы модули ядра присутствуют в системе:
$ ls -l /lib/modules/`uname -r`/extra/ $ ls -l /lib/modules/`uname -r`/extra/dev_handlers
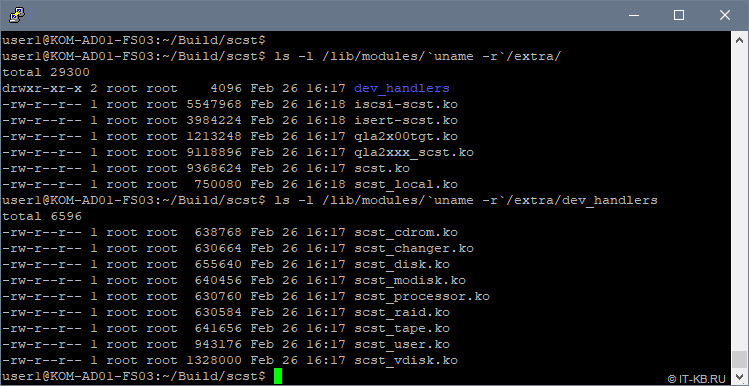
Убедимся в том, что для нужных нам модулей ядра, при попытке их загрузки не возникает никаких ошибок:
$ sudo modprobe scst $ sudo modprobe qla2x00tgt $ sudo modprobe qla2xxx_scst $ sudo modprobe scst_vdisk $ sudo modprobe scst_user $ sudo modprobe scst_disk

Если при попытке загрузки модулей возникает ошибка типа » modprobe: FATAL: Module qla2x00tgt not found in directory /lib/modules/4.9.82-scst-enabled «, но соответствующий ko-файл при этом в каталоге присутствует, попробуйте выполнить обновление зависимостей модулей командой:
$ sudo depmod --all
Убедившись в том, что все нужные нам модули загружаются без ошибок, настраиваем их автоматическую загрузку при старте системы, дописав названия модулей в конец конфигурационного файла /etc/modules
$ cat /etc/modules # /etc/modules: kernel modules to load at boot time. # # This file contains the names of kernel modules that should be loaded # at boot time, one per line. Lines beginning with "#" are ignored. # scst qla2xxx_scst qla2x00tgt scst_vdisk scst_user scst_disk
Перезагрузим систему, чтобы убедиться в том, что в процессе загрузки модули SCST загружаются успешно. Проверим это в выводе команды dmesg
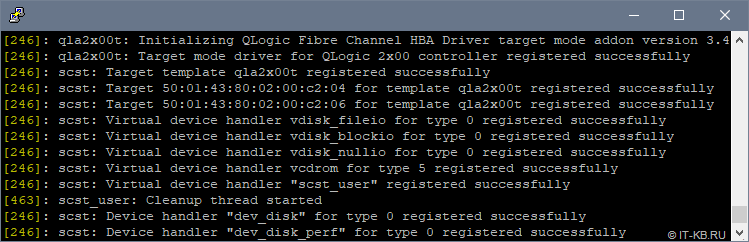
Далее мы рассмотрим пример настройки и загрузки рабочей конфигурации SCST, но прежде нам потребуется собрать и установить утилиту управления scstadmin.
Компилируем и устанавливаем SCSTAdmin
Снова входим в режим непривелегированного пользователя, переходим в наш каталог с исходными файлами scst в подкаталог ../scstadmin и даём последовательно команды компиляции и установки:
$ cd ~/Build/scst/scstadmin/ $ make $ sudo make install
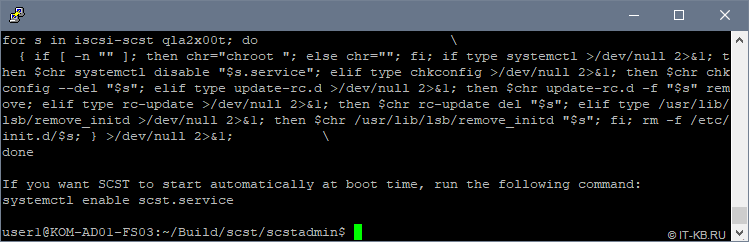
Последуем совету, который будет выдан нам в процессе установки, и включим автоматическую загрузку службы scst.service при старте системы:
$ sudo systemctl enable scst.service

Теперь давайте спросим у scstadmin, какие типы HANDLER и TARGET_DRIVER нам доступны для настройки нашей конфигурации:
# scstadmin -list_handler # scstadmin -list_driver
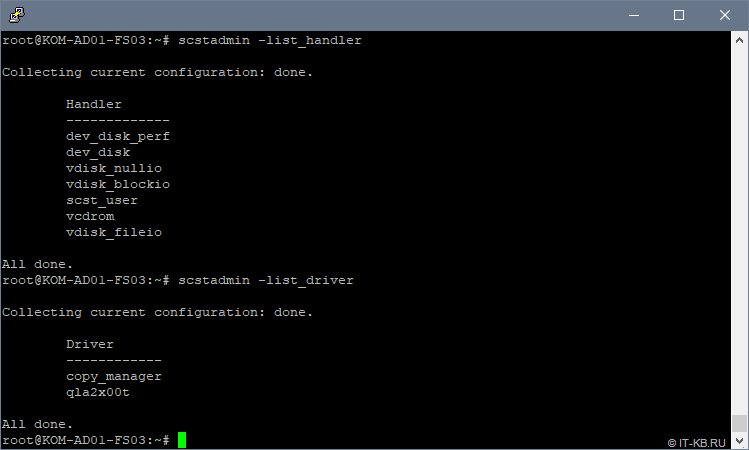
Как видим, в списке поддерживаемых scstadmin драйверов есть интересующий нас драйвер qla2x00t.
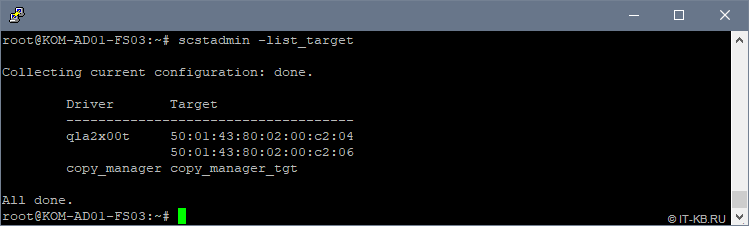
Посмотрим информацию о доступных TARGET , которыми мы можем оперировать в конфигурации:
# scstadmin -list_target
Теперь можно переходить к настройке конфигурации SCST, но перед этим нужно определиться с дисковыми ресурсами, которые мы будем транслировать с нашего Linux-сервера на хосты виртуализации через FC Target.
Настраиваем дисковые ресурсы Linux-сервера
Для построения кластера высоко-доступных виртуальных машин Hyper-V нам, как минимум, потребуется один выделенный диск под том CSV, на котором будут размещаться виртуальные машины. Дополнительно нам не помешает иметь ещё один кластерный диск для роли диска-свидетеля, который нужен для организации кластерного кворума Windows Failover Cluster.
На имеющейся в нашем распоряжении конфигурации из 6 дисков в утилите управления HPE SSA, об установке которой мы говорили ранее , создан массив Smart Array ( Array B ). В этом массиве созданы 2 логических диска:
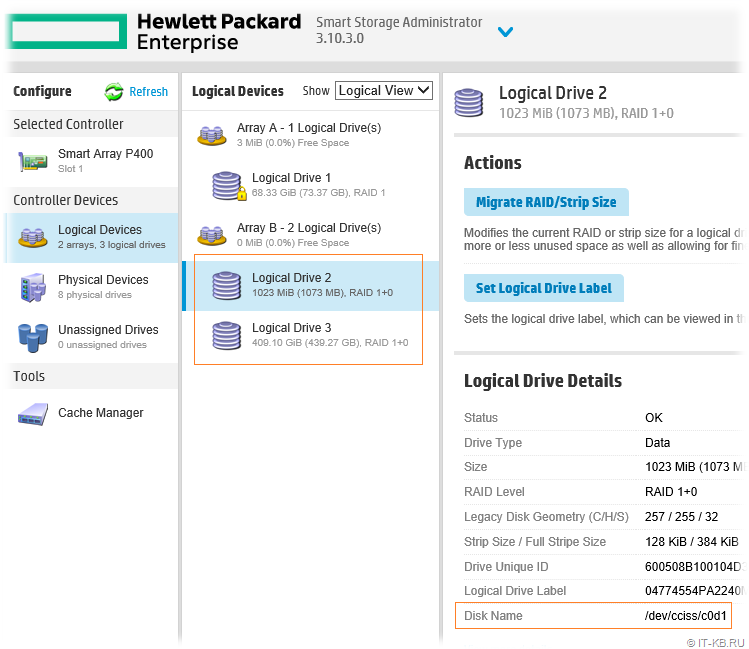
Логический диск » Logical Drive 2 » размером в 1GB определён в нашей Linux-системе, как блочное устройство /dev/cciss/c0d1 . Этот диск будет использоваться в качестве диска-свидетеля. Есть мнение, что при построении кластеров Windows Failover Cluster в качестве диска-свидетеля правильней выбирать диск не связанный напрямую с диском, который будет использоваться под кластеризуемые сервисы, как например, в нашем случае — под размещение ВМ. Ну или по крайней мере эти диски лучше иметь из разных RAID массивов. Но в моём случае конфигурация весьма ограниченная, поэтому используется такая вот упрощённая схема.
Логический диск » Logical Drive 3 «, которому выдана вся оставшаяся ёмкость дискового массива, определён в Linux, как блочное устройство /dev/cciss/c0d2 . Этот диск будет использоваться в качестве диска для хранения ВМ. В последствии данный диск будет преобразован в CSV
Настраиваем конфигурацию SCST
По умолчанию основная служба scst.service будет загружаться без использования какой-либо конфигурации. Поэтому нам потребуется создать основной конфигурационный файл scst.conf , описать в нём нужную нам конфигурацию FC Target и обеспечить его автоматическую загрузку при старте системы.
Создадим отсутствующий по умолчанию файл scst.conf :
# nano /etc/scst.conf
Наполним его содержимым примерно следующего характера (основную информацию относительно написания конфигурационного файла можно посмотреть в man scst.conf):
HANDLER vdisk_fileio < # # HP Smart-Array P400 Controller - Array B - Logical Drive 2 # DEVICE FS03-P400-B-LD2 < filename /dev/cciss/c0d1 > # # HP Smart-Array P400 Controller - Array B - Logical Drive 3 # DEVICE FS03-P400-B-LD3 < filename /dev/cciss/c0d2 >> TARGET_DRIVER qla2x00t < # # HBA HP QLogic QLE2462 - Port 0 # TARGET 50:01:43:80:02:00:c2:04 < enabled 1 # # Access for host KOM-AD01-VM02 # GROUP Host-VM02 < LUN 0 FS03-P400-B-LD2 LUN 1 FS03-P400-B-LD3 INITIATOR 10:00:00:00:c9:78:25:16 >> # # HBA HP QLogic QLE2462 - Port 1 # TARGET 50:01:43:80:02:00:c2:06 < enabled 1 # # Access for host KOM-AD01-VM01 # GROUP Host-VM01 < LUN 0 FS03-P400-B-LD2 LUN 1 FS03-P400-B-LD3 INITIATOR 10:00:00:00:c9:6f:2c:e4 >> >
В целом структура конфигурационного файла SCST очень наглядна и логична.
В нашем примере в разделе HANDLER описаны имеющиеся в нашем распоряжении блочные устройства, которые нужно транслировать на FC Target. Типы поддерживаемых устройств мы проверяли ранее командой scstadmin -list_handler . Каждое блочное устройство описывается в отдельной секции DEVICE . Имена дисковым устройствам SCST в нашем примере назначены таким образом, чтобы сразу было очевидно физическое месторасположение этих устройств.
В разделе TARGET_DRIVER описаны так называемые цели – Target. Типы поддерживаемых драйверов мы проверяли ранее командой scstadmin -list_driver . Каждый порт оптического контроллера, который мы хотим превратить в FC Target имеет отдельную секцию TARGET .
В свою очередь для каждой отдельной цели ( TARGET ) мы описываем группу GROUP , в которой определяем перечень устройств (из HANDLER \ DEVICE ) с номерами LUN и WWPN портов оптических адаптеров хостов, которым нужно предоставить доступ к данным LUN-ам через данный TARGET (WWPN портов со стороны FC Initiator).
Подготовив конфигурационный файл, заставим SCST перечитать конфигурацию:
# scstadmin -conf /etc/scst.conf
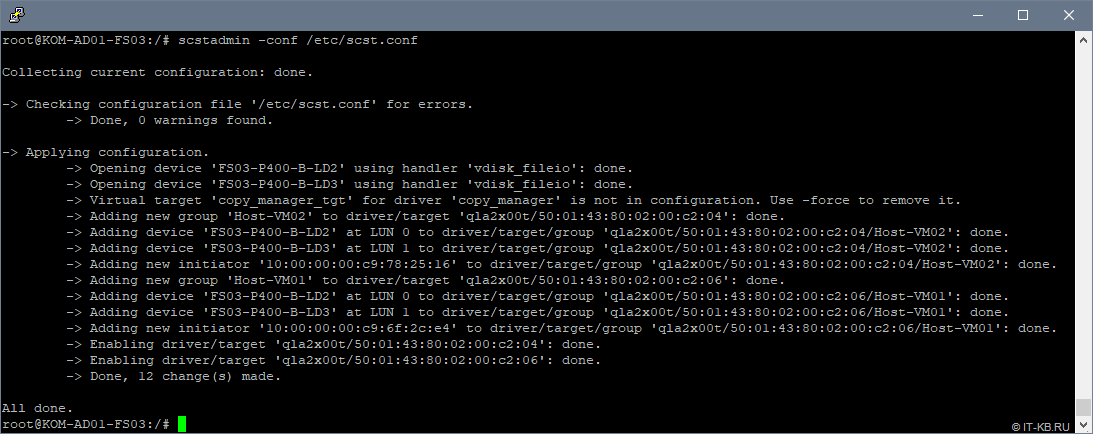
Если scstadmin отказывается загружать созданный нами вручную конфигурационный файл scst.conf , то вполне возможно, что где-то допущена синтаксическая ошибка. В таком случае правку конфигурации можно выполнять через набор встроенных команд в утилиту scstadmin (смотреть встроенную справку scstadmin —help )
В любом случае при попытке загрузки созданной нами конфигурации никаких ошибок быть не должно и соответствующие LUN-ы должны в этот момент стать доступны на стороне хостов виртуализации. Однако, прежде чем, переходить к использованию LUN-ов на стороне хостов Hyper-V нам нужно решить ещё одну задачу – обеспечить автоматическую загрузку созданной нами конфигурации в процессе загрузки Linux.
Настраиваем автоматическую загрузку конфигурации SCST
Создадим новую службу (systemd unit), например с именем scst-config.service, описав её конфигурацию в каталоге /etc/systemd/system :
# nano /etc/systemd/system/scst-config.service
Наполним файл содержимым:
[Unit] Description=SCST Configuration Service After=scst.service [Service] Type=oneshot RemainAfterExit=yes ExecStart=/usr/local/sbin/scstadmin -config /etc/scst.conf StandardOutput=journal [Install] WantedBy=multi-user.target
Включим автозагрузку службы при старте системы:
# systemctl enable scst-config.service
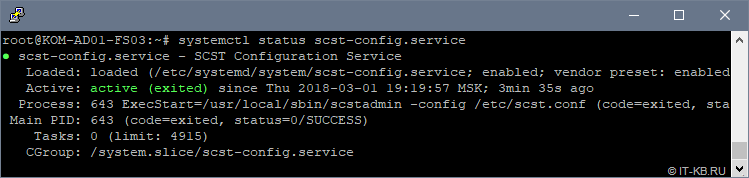
Перезагрузим сервер и убедимся в том, что наша служба успешно стартовала после загрузки ОС:
# systemctl status scst-config.service
Проверим лог, созданной нами службы scst-config.service, чтобы увидеть вывод утилиты scstadmin в процессе загрузки конфигурации из файла /etc/scst.conf :
# journalctl --unit scst-config.service --output cat
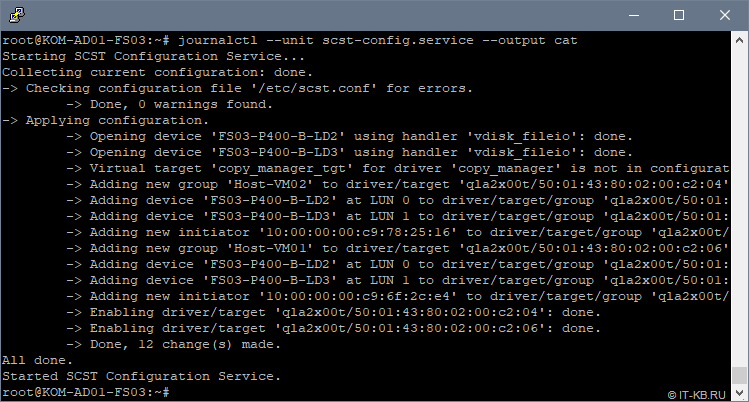
Как видим, конфигурация SCST загружена успешно и никаких ошибок и предупреждений в процессе загрузки нет.
Настроенная нами служба scst-config.service устроена таким образом, что её перезапуск равнозначен команде scstadmin -config /etc/scst.conf , то есть если нужно заставить SCST перечитать конфигурацию scst.conf, то для этого достаточно перезапустить службу:
# systemctl status scst-config.service
При этом остановка службы никак не повлияет на работу SCST.
Теперь можем переходить к инициализации транслируемых через FC Target дисковых устройств на хостах виртуализации.
Проверяем доступность LUN-ов на хостах виртуализации
На любом из хостов виртуализации откроем консоль Device Manager и удостоверимся в том, что в разделе Disk drives присутствуют созданные нами ранее в конфигурации SCST дисковые устройства. Затем перейдём в консоль управления дисками Disk Management и переведём соответствующие дисковые устройства в состояние Online:
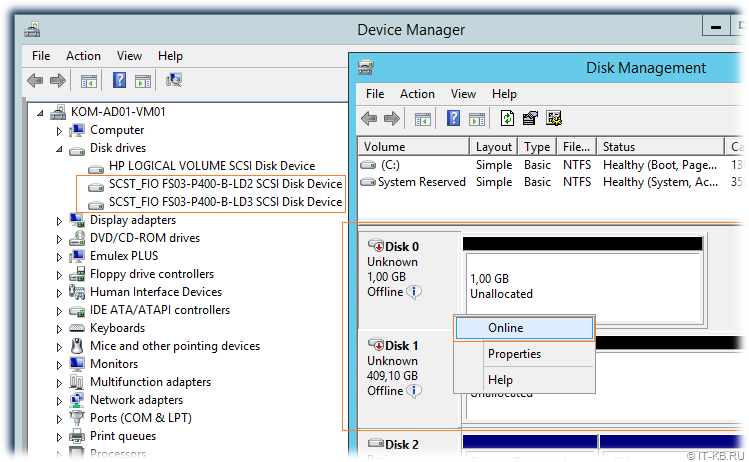
После того, как диски переведены в Online, выполняем инициализацию этих дисков (Initialize Disk), затем создаём на диске простой том NTFS (New Simple Volume…)
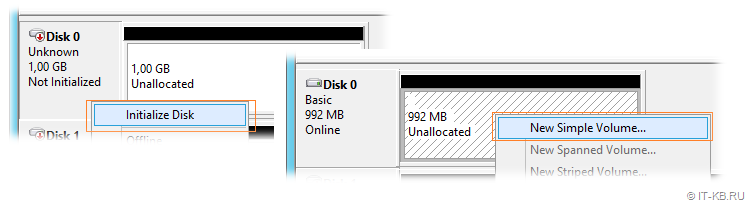
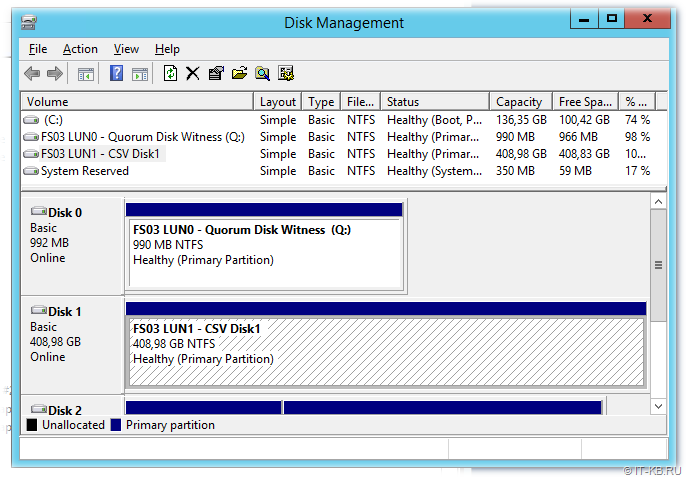
При форматировании первого диска, который будет использоваться в будущем кластере в качестве диска свидетеля, присвоим букву диска, например Q . Второму диску, который будет использоваться в кластере в качестве CSV для размещения виртуальных машин, при форматировании букву диска не присваиваем, так как в дальнейшем этот диск будет смонтирован в каталог C:\ClusterStorage на обоих узлах кластера.
В результате на первом хосте мы получим примерно следующую картину
Теперь подключимся ко второму хосту и убедимся в том, что там оба диска также доступны, но они при этом будут находится в состоянии Offline.
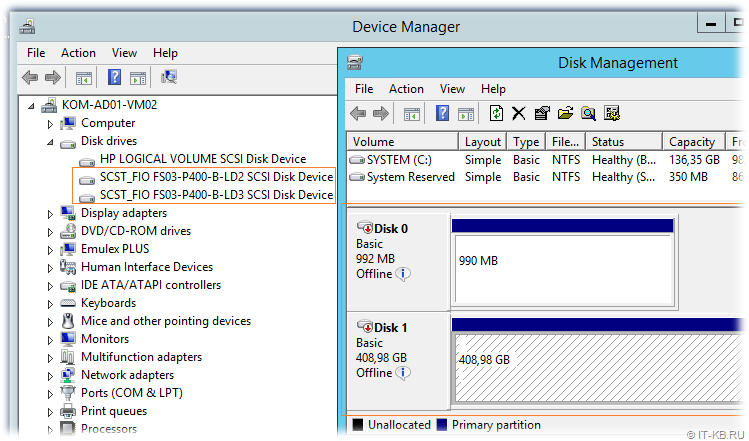
Как видим, диски доступны на обоих хостах виртуализации и подготовлены для того, чтобы использовать их для построения кластера Windows Failover Cluster.
Выполняем валидацию LUN-ов и создаём кластер Windows Failover Cluster
Сразу скажу, что мы не будем рассматривать все подготовительные процедуры, необходимые для создания кластера Windows Failover Cluster, а заострим внимание лишь на тех моментах, которые имеют непосредственное отношение к работе с дисковыми ресурсами, подключенными к хостам виртуализации с Linux-сервера c SCST.
Предполагаем, что на обоих хостах виртуализации у нас уже установлены компоненты Windows Failover Cluster и настроены выделенные сетевые адаптеры для меж-узлового обмена. Открываем на любом из хостов оснастку Failover Cluster Manager (Cluadmin.msc) и вызываем мастер проверки конфигурации кластера Validate a Configuration Wizard. Добавив в мастер оба наших хоста виртуализации, запускаем процедуру проверки конфигурации хостов на предмет возможности включения этих хостов в кластер.
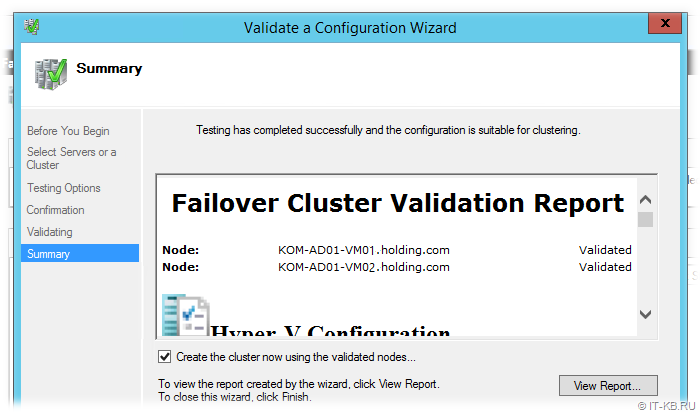
В результате мы должны удостовериться в том, что презентованные с Linux-хоста с SCST дисковые устройства успешно проходят все проверки. Детальную информацию о выполненных проверках можно посмотреть, пройдя по гиперссылкам в отчёте в разделе Storage
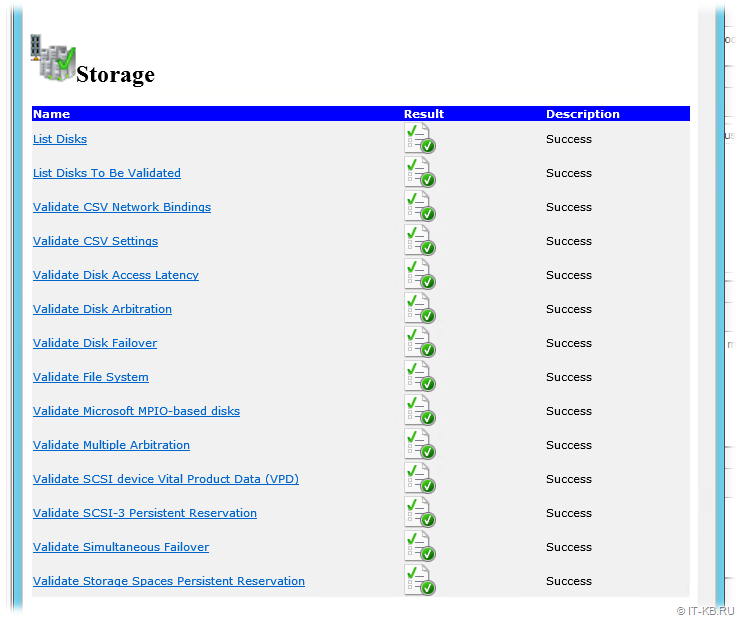
В общем-то уже на данном этапе мы видим, что поставленная цель превращения обычного сервера в СХД нами достигнута. Далее на базе проверенной конфигурации хостов создаём опорный кластер Windows Failover Cluster, преобразуем диск в CSV, а затем создаём в кластере высоко-доступную ВМ Hyper-V. После проверяем штатное перемещение ВМ между узлами кластера, а также проверяем обработку отказа узла в кластере.
Выводы
Итак, базовая кластерная конфигурация Hyper-V с подключённой по оптике дисковой ёмкостью собрана нами в простом бюджетном варианте с использованием свободно-распространяемого ПО SCST на базе современной версии Debian Linux на старом серверном оборудовании. Отдельно приобретаемые под эту задачу адаптеры HBA старых поколений FC 4G сейчас стоят довольно скромных денег. Хотите скоростей, пожалуйста, используйте на стороне сервера SCST и подключаемых к нему хостов более современные адаптеры HBA FC 8G или даже 16G
Если Linux-сервер c SCST подключать не напрямую к хостам, а к фабрикам FC SAN, то можно отдавать дисковую ёмкость бОльшему количеству хостов виртуализации, используя более широкие кластерные конфигурации Windows Failover Cluster.
Разумеется описанное решение имеет свои «узкие места».
Если сервер SCST собран без учёта избыточности аппаратных компонент, как, например, в нашем случае используется только один контроллер FC HBA QLogic, то выход из строя таких компонент может привести к недоступности всех виртуальных машин (дисковая ёмкость станет недоступна сразу всем хостам кластера). В качестве решения можно расширить конфигурацию на сервере SCST вторым контроллером, а на узлах использовать, двух-портовые HBA или пару одно-портовых HBA, чтобы можно было использовать multipath-подключение к дисковым ресурсам SCST, которое обработку отказа путей подключения.
Дополнительные источники информации:
- SCST Howto — How to Configure the FC QLogic Target Driver for 22xx/23xx/24xx/25xx/26xx Adapters
- thejimmahknows.com — Linux Fibre Channel SCSI Target using SCST
- debianforum.de — FC Target (SAN) unter Debian 8 / Jessie
- nandydandyoracle — SCST Debian Package Build from Source (Ubuntu 17.04)
- Хабрахабр — Бюджетное SAN-хранилище на LSI Syncro