Соединение таблиц – операция JOIN и ее виды
Говоря про соединение таблиц в SQL, обычно подразумевают один из видов операции JOIN. Не стоит путать с объединением таблиц через операцию UNION. В этой статье я постараюсь простыми словами рассказать именно про соединение, чтобы после ее прочтения Вы могли использовать джойны в работе и не допускать грубых ошибок.
Соединение – это операция, когда таблицы сравниваются между собой построчно и появляется возможность вывода столбцов из всех таблиц, участвующих в соединении.
Придумаем 2 таблицы, на которых будем тренироваться.
Таблица «Сотрудники», содержит поля:
- id – идентификатор сотрудника
- Имя
- Отдел – идентификатор отдела, в котором работает сотрудник
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | 1 |
| 2 | Федор | 2 |
| 3 | Алексей | NULL |
| 4 | Светлана | 2 |
Таблица «Отделы», содержит поля:
- id – идентификатор отдела
- Наименование
| id | Наименование |
|---|---|
| 1 | Кухня |
| 2 | Бар |
| 3 | Администрация |
Давайте уже быстрее что-нибудь покодим.
INNER JOIN
Самый простой вид соединения INNER JOIN – внутреннее соединение. Этот вид джойна выведет только те строки, если условие соединения выполняется (является истинным, т.е. TRUE). В запросах необязательно прописывать INNER – если написать только JOIN, то СУБД по умолчанию выполнить именно внутреннее соединение.
Давайте соединим таблицы из нашего примера, чтобы ответить на вопрос, в каких отделах работают сотрудники (читайте комментарии в запросе для понимания синтаксиса).
SELECT -- Перечисляем столбцы, которые хотим вывести Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел -- выводим наименование отдела и переименовываем столбец через as FROM -- таблицы для соединения перечисляем в предложении from Сотрудники -- обратите внимание, что мы не указали вид соединения, поэтому выполнится внутренний (inner) джойн JOIN Отделы -- условия соединения прописываются после ON -- условий может быть несколько, записанных через and, or и т.п. ON Сотрудники.Отдел = Отделы.id
Получим следующий результат:
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 4 | Светлана | Бар |
Из результатов пропал сотрудник Алексей (id = 3), потому что условие «Сотрудники.Отдел = Отделы.id» не будет истинно для этой сроки из таблицы «Сотрудники» с каждой строкой из таблицы «Отделы». По той же логике в результате нет отдела «Администрация». Попробую это визуализировать (зеленные линии – условие TRUE, иначе линия красная):
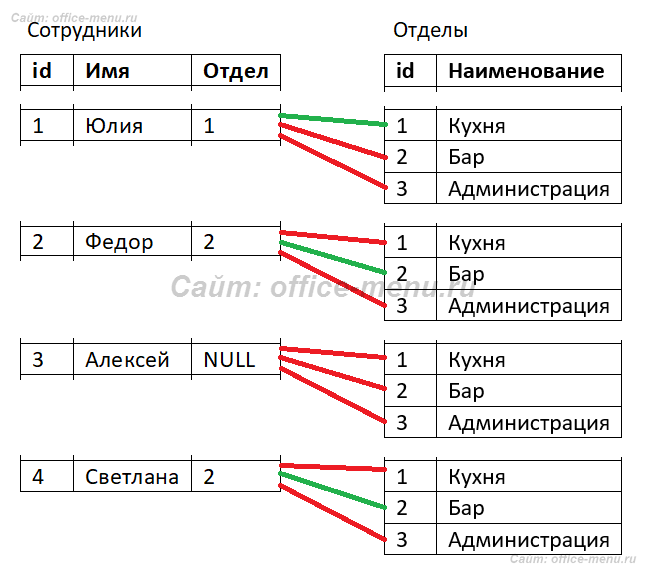
Если не углубляться в то, как внутреннее соединение работает под капотом СУБД, то происходит примерно следующее:
- Каждая строка из одной таблицы сравнивается с каждой строкой из другой таблицы
- Строка возвращается, если условие сравнения является истинным
Если для одной или нескольких срок из левой таблицы (в рассмотренном примере левой таблицей является «Сотрудники», а правой «Отделы») истинным условием соединения будут являться одна или несколько срок из правой таблицы, то строки умножат друг друга (повторятся). В нашем примере так произошло для отдела с поэтому строка из таблицы «Отделы» повторилась дважды для Федора и Светланы.
Перемножение таблиц проще ощутить на таком примере, где условие соединения будет всегда возвращать TRUE, например 1=1:
SELECT * FROM Сотрудники JOIN Отделы ON 1=1
В результате получится 12 строк (4 сотрудника * 3 отдела), где для каждого сотрудника подтянется каждый отдел.
Также хочу сразу отметить, что в соединении может участвовать сколько угодно таблиц, можно таблицу соединить даже саму с собой (в аналитических задачах это не редкость). Какая из таблиц будет правой или левой не имеется значения для INNER JOIN (для внешних соединений типа LEFT JOIN или RIGHT JOIN это важно. Читайте далее). Пример соединения 4-х таблиц:
SELECT * FROM Table_1 JOIN Table_2 ON Table_1.Column_1 = Table_2.Column_1 JOIN Table_3 ON Table_1.Column_1 = Table_3.Column_1 AND Table_2.Column_1 = Table_3.Column_1 JOIN Table_1 AS Tbl_1 -- Задаем алиас для таблицы, чтобы избежать неоднозначности -- Если в Table_1.Column_1 хранится порядковый номер какого-то объекта, -- то так можно присоединить следующий по порядку объект ON Table_1.Column_1 = Tbl_1.Column_1 + 1
Как видите, все просто, прописываем новый джойн после завершения условий предыдущего соединения. Обратите внимание, что для Table_3 указано несколько условий соединения с двумя разными таблицами, а также Table_1 соединяется сама с собой по условию с использованием сложения.
Строки, которые выведутся запросом, должны совпасть по всем условиям. Например:
- Строка из Table_1 соединилась со строкой из Table_2 по условию первого JOIN. Давайте назовем ее «объединенной строкой» из двух таблиц;
- Объединенная строка успешно соединилась с Table_3 по условию второго JOIN и теперь состоит из трех таблиц;
- Для объединенной строки не нашлось строки из Table_1 по условию третьего JOIN, поэтому она не выводится вообще.
На этом про внутреннее соединение и логику соединения таблиц в SQL – всё. Если остались неясности, то спрашивайте в комментариях.
Далее рассмотрим отличия остальных видов джойнов.
LEFT JOIN и RIGHT JOIN
Левое и правое соединения еще называют внешними. Главное их отличие от внутреннего соединения в том, что строка из левой (для LEFT JOIN) или из правой таблицы (для RIGHT JOIN) попадет в результаты в любом случае. Давайте до конца определимся с тем, какая таблица левая, а какая правая.
Левая таблица та, которая идет перед написанием ключевых слов [LEFT | RIGHT| INNER] JOIN, правая таблица – после них:
SELECT * FROM Левая_таблица AS lt LEFT JOIN Правая_таблица AS rt ON lt.c = rt.c
Теперь изменим наш SQL-запрос из самого первого примера так, чтобы ответить на вопрос «В каких отделах работают сотрудники, а также показать тех, кто не распределен ни в один отдел?»:
SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Сотрудники LEFT JOIN Отделы -- добавляем только left ON Сотрудники.Отдел = Отделы.id
Результат запроса будет следующим:
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 3 | Алексей | NULL |
| 4 | Светлана | Бар |
Как видите, запрос вернул все строки из левой таблицы «Сотрудники», дополнив их значениями из правой таблицы «Отделы». А вот строка для отдела «Администрация» не показана, т.к. для нее не нашлось совпадений слева.
Это мы рассмотрели пример для левого внешнего соединения. Для RIGHT JOIN будет все тоже самое, только вернутся все строки из таблицы «Отделы»:
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 4 | Светлана | Бар |
| NULL | NULL | Администрация |
Алексей «потерялся», Администрация «нашлась».
Вопрос для Вас. Что надо изменить в последнем приведенном SQL-запросе, чтобы результат остался тем же, но вместо LEFT JOIN, использовался RIGHT JOIN?
Ответ. Нужно поменять таблицы местами:
SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Отделы RIGHT JOIN Сотрудники ON Сотрудники.Отдел = Отделы.id
В одном запросе можно применять и внутренние соединения, и внешние одновременно, главное соблюдать порядок таблиц, чтобы не потерять часть записей (строк).
FULL JOIN
Еще один вид соединения, который осталось рассмотреть – полное внешнее соединение.
Этот вид джойна вернет все строки из всех таблиц, участвующих в соединении, соединив между собой те, которые подошли под условие ON.
Давайте посмотрим всех сотрудников и все отделы из наших тестовых таблиц:
SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Сотрудники FULL JOIN Отделы ON Сотрудники.Отдел = Отделы.id
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 3 | Алексей | NULL |
| 4 | Светлана | Бар |
| NULL | NULL | Администрация |
Теперь мы видим все, даже Алексея без отдела и Администрацию без сотрудников.
Вместо заключения
Помните о порядке выполнения соединений и порядке таблиц, если используете несколько соединений и используете внешние соединения. Можно выполнять LEFT JOIN для сохранения всех строк из самой первой таблицы, а последним внутренним соединением потерять часть данных. На маленьких таблицах косяк заметить легко, на огромных очень тяжело, поэтому будьте внимательны.
Рассмотрим последний пример и введем еще одну таблицу «Банки», в которой обслуживаются наши придуманные сотрудники:
| id | Наименование |
|---|---|
| 1 | Банк №1 |
| 2 | Лучший банк |
| 3 | Банк Лидер |
В таблицу «Сотрудники» добавим столбец «Банк»:
| id | Имя | Отдел | Банк |
|---|---|---|---|
| 1 | Юлия | 1 | 2 |
| 2 | Федор | 2 | 2 |
| 3 | Алексей | NULL | 3 |
| 4 | Светлана | 2 | 4 |
Теперь выполним такой запрос:
SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел, Банки.Наименование AS Банк FROM Сотрудники LEFT JOIN Отделы ON Сотрудники.Отдел = Отделы.id INNER JOIN Банки ON Сотрудники.Банк = Банки.id
В результате потеряли информацию о Светлане, т.к. для нее не нашлось банка с (такое происходит из-за неправильной проектировки БД):
| id | Имя | Отдел | Банк |
|---|---|---|---|
| 1 | Юлия | Кухня | Лучший банк |
| 2 | Федор | Бар | Лучший банк |
| 3 | Алексей | NULL | Банк Лидер |
Хочу обратить внимание на то, что любое сравнение с неизвестным значением никогда не будет истинным (даже NULL = NULL). Эту грубую ошибку часто допускают начинающие специалисты. Подробнее читайте в статье про значение NULL в SQL.
Пройдите мой тест на знание основ SQL. В нем есть задания на соединения таблиц, которые помогут закрепить материал.
Дополнить Ваше понимание соединений в SQL могут схемы, изображенные с помощью кругов Эйлера. В интернете много примеров в виде картинок.
Если какие нюансы джойнов остались не раскрытыми, или что-то описано не совсем понятно, что-то надо дополнить, то пишите в комментариях. Буду только рад вопросам и предложениям.
Привожу простыню запросов, чтобы Вы могли попрактиковаться на легких примерах, рассмотренных в статье:
-- Создаем CTE для таблиц из примеров WITH Сотрудники AS( SELECT 1 AS id, 'Юлия' AS Имя, 1 AS Отдел, 2 AS Банк UNION ALL SELECT 2, 'Федор', 2, 2 UNION ALL SELECT 3, 'Алексей', NULL, 3 UNION ALL SELECT 4, 'Светлана', 2, 4 ), Отделы AS( SELECT 1 AS id, 'Кухня' AS Наименование UNION ALL SELECT 2, 'Бар' UNION ALL SELECT 3, 'Администрация' ), Банки AS( SELECT 1 AS id, 'Банк №1' AS Наименование UNION ALL SELECT 2, 'Лучший банк' UNION ALL SELECT 3, 'Банк Лидер' ) -- Если надо выполнить другие запросы, то сначала закоментируй это запрос с помощью /**/, -- а нужный запрос расскоментируй или напиши свой. -- Это пример внутреннего соединения SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Сотрудники JOIN Отделы ON Сотрудники.Отдел = Отделы.id /* -- Пример левого джойна SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Сотрудники LEFT JOIN Отделы ON Сотрудники.Отдел = Отделы.id */ /* -- Результат этого запроса будет аналогичен результату запроса выше, хотя соединение отличается SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Отделы RIGHT JOIN Сотрудники ON Сотрудники.Отдел = Отделы.id */ /* -- Правое соединение SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Сотрудники RIGHT JOIN Отделы ON Сотрудники.Отдел = Отделы.id */ /* -- Пример с использованием разных видов JOIN SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Отделы RIGHT JOIN Сотрудники ON Сотрудники.Отдел = Отделы.id LEFT JOIN Банки ON Банки.id = Сотрудники.Банк */ /* -- Полное внешние соединение SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Сотрудники FULL JOIN Отделы ON Сотрудники.Отдел = Отделы.id */ /* -- Пример с потерей строки из-за последнего внутреннего соединения SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел, Банки.Наименование AS Банк FROM Сотрудники LEFT JOIN Отделы ON Сотрудники.Отдел = Отделы.id INNER JOIN Банки ON Сотрудники.Банк = Банки.id */ /* -- Запрос с условием, которое всегда будет True SELECT * FROM Сотрудники JOIN Отделы ON 1=1 */
- Объединение таблиц – UNION
- Соединение таблиц – операция JOIN и ее виды
- Тест на знание основ SQL
Если материалы office-menu.ru Вам помогли, то поддержите, пожалуйста, проект, чтобы я мог развивать его дальше.
Введение в соединения
Соединение (JOIN) — одна из самых важных операций, выполняемых реляционными системами управления базами данных (РСУБД). РСУБД используют соединения для того, чтобы сопоставить строки одной таблицы строкам другой таблицы. Например, соединения можно использовать для сопоставления продаж — клиентам или книг — авторам. Без соединений, имелись бы раздельные списки продаж и клиентов или книг и авторов, но невозможно было бы определить, какие клиенты что купили, или какой из авторов был заказан.
Можно соединить две таблицы явно, перечислив обе таблицы в предложении FROM запроса. Также можно соединить две таблицы, используя для этого всё разнообразие подзапросов. Наконец, SQL Server во время оптимизации может добавить соединение в план запроса, преследуя свои цели.
Это первая из серии статей, которые я планирую посвятить соединениям. Эту статью я собираюсь посвятить азам соединений, описав назначение логических операторов соединениё, поддерживаемых SQL Server. Вот они:
- Inner join
- Outer join
- Cross join
- Cross apply
- Semi-join
- Anti-semi-join
Для иллюстрации каждого соединения я буду использовать простую схему и набор данных:
create table Customers (Cust_Id int, Cust_Name varchar(10)) insert Customers values (1, 'Craig') insert Customers values (2, 'John Doe') insert Customers values (3, 'Jane Doe') create table Sales (Cust_Id int, Item varchar(10)) insert Sales values (2, 'Camera') insert Sales values (3, 'Computer') insert Sales values (3, 'Monitor') insert Sales values (4, 'Printer')Внутренние соединения
Внутренние соединения — самый распространённый тип соединений. Внутреннее соединение просто находит пары строк, которые соединяются и удовлетворяют предикату соединения. Например, показанный ниже запрос использует предикат соединения «S.Cust_Id = C.Cust_Id», позволяющий найти все продажи и сведения о клиенте с одинаковыми значениями Cust_Id:
select * from Sales S inner join Customers C on S.Cust_Id = C.Cust_Id Cust_Id Item Cust_Id Cust_Name ----------- ---------- ----------- ---------- 2 Camera 2 John Doe 3 Computer 3 Jane Doe 3 Monitor 3 Jane DoeПримечания:
Cust_Id = 3 купил два наименования, поэтому он фигурирует в двух строках результирующего набора.
Cust_Id = 1 не купил ничто и потому не появляется в результате.
Для Cust_Id = 4 тоже был продан товар, но поскольку в таблице нет такого клиента, сведения о такой продаже не появились в результате.
Внутренние соединения полностью коммутативны. «A inner join B» и «B inner join A» эквивалентны.
Внешние соединения
Предположим, что мы хотели бы увидеть список всех продаж; даже тех, которые не имеют соответствующих им записей о клиенте. Можно составить запрос с внешним соединением, которое покажет все строки в одной или обеих соединяемых таблицах, даже если не будет существовать соответствующих предикату соединения строку. Например:
select * from Sales S left outer join Customers C on S.Cust_Id = C.Cust_Id Cust_Id Item Cust_Id Cust_Name ----------- ---------- ----------- ---------- 2 Camera 2 John Doe 3 Computer 3 Jane Doe 3 Monitor 3 Jane Doe 4 Printer NULL NULLОбратите внимание, что сервер возвращает вместо данных о клиенте значение NULL, поскольку для проданного товара ‘Printer’ нет соответствующей записи клиента. Обратите внимание на последнюю строку, у которой отсутствующие значения заполнены значением NULL.
Используя полное внешнее соединение, можно найти всех клиентов (независимо от того, покупали ли они что-нибудь), и все продажи (независимо от того, сопоставлен ли им имеющийся клиент):
select * from Sales S full outer join Customers C on S.Cust_Id = C.Cust_Id Cust_Id Item Cust_Id Cust_Name ----------- ---------- ----------- ---------- 2 Camera 2 John Doe 3 Computer 3 Jane Doe 3 Monitor 3 Jane Doe 4 Printer NULL NULL NULL NULL 1 CraigСледующая таблица показывает, строки какой из соединяемых таблиц попадут в результирующий набор (у оставшейся таблицы возможны замены NULL), она охватывает все типы внешних соединений:
A left outer join B
A right outer join B
A full outer join B
Все строки A и B
Полные внешние соединения коммутативны. Кроме того, «A left outer join B » и «B right outer join A» является эквивалентным.
Перекрестные соединения
Перекрестное соединение выполняет полное Декартово произведение двух таблиц. То есть это соответствие каждой строки одной таблицы — каждой строке другой таблицы. Для перекрестного соединения нельзя определить предикат соединения, используя для этого предложение ON, хотя для достижения практически того же результата, что и с внутренним соединением, можно использовать предложение WHERE.
Перекрестные соединения используются довольно редко. Никогда не стоит пересекать две большие таблицы, поскольку это задействует очень дорогие операции и получится очень большой результирующий набор.
select * from Sales S cross join Customers C Cust_Id Item Cust_Id Cust_Name ----------- ---------- ----------- ---------- 2 Camera 1 Craig 3 Computer 1 Craig 3 Monitor 1 Craig 4 Printer 1 Craig 2 Camera 2 John Doe 3 Computer 2 John Doe 3 Monitor 2 John Doe 4 Printer 2 John Doe 2 Camera 3 Jane Doe 3 Computer 3 Jane Doe 3 Monitor 3 Jane Doe 4 Printer 3 Jane DoeCROSS APPLY
В SQL Server 2005 мы добавили оператор CROSS APPLY, с помощью которого можно соединять таблицу с возвращающей табличное значение функцией (table valued function — TVF), причём TVF будет иметь параметр, который будет изменяться для каждой строки. Например, представленный ниже запрос возвратит тот же результат, что и показанное ранее внутреннее соединение, но с использованием TVF и CROSS APPLY:
create function dbo.fn_Sales(@Cust_Id int) returns @Sales table (Item varchar(10)) as begin insert @Sales select Item from Sales where Cust_Id = @Cust_Id return end select * from Customers cross apply dbo.fn_Sales(Cust_Id) Cust_Id Cust_Name Item ----------- ---------- ---------- 2 John Doe Camera 3 Jane Doe Computer 3 Jane Doe MonitorТакже можно использовать внешнее обращение — OUTER APPLY, позволяющее нам найти всех клиентов независимо от того, купили ли они что-нибудь или нет. Это будет похоже на внешнее соединение.
select * from Customers outer apply dbo.fn_Sales(Cust_Id) Cust_Id Cust_Name Item ----------- ---------- ---------- 1 Craig NULL 2 John Doe Camera 3 Jane Doe Computer 3 Jane Doe MonitorПолусоединение и анти-полусоединение
Полусоединение — semi-join возвращает строки только одной из соединяемых таблиц, без выполнения соединения полностью. Анти-полусоединение возвращает те строки таблицы, которые не годятся для соединения с другой таблицей; т.е. они в обычном внешнем соединении выдавали бы NULL.
В отличие от других операторов соединений, не существует явного синтаксиса для указания исполнения полусоединения, но SQL Server, в целом ряде случаев, использует в плане исполнения именно полусоединения. Например, полусоединение может использоваться в плане подзапроса с EXISTS:
select * from Customers C where exists ( select * from Sales S where S.Cust_Id = C.Cust_Id ) Cust_Id Cust_Name ----------- ---------- 2 John Doe 3 Jane DoeВ отличие от предыдущих примеров, полусоединение возвращает только данные о клиентах.
В плане запроса видно, что SQL Server действительно использует полусоединение:
|—Nested Loops(Left Semi Join, WHERE:([S].[Cust_Id]=[C].[Cust_Id]))
|—Table Scan(OBJECT:([Customers] AS [C]))
|—Table Scan(OBJECT:([Sales] AS [S]))
Существуют левые и правые полусоединения. Левое полусоединение возвращает строки левой (первой) таблицы, которые соответствуют строкам из правой (второй) таблицы, в то время как правое полусоединение возвращает строки из правой таблицы, которые соответствуют строкам из левой таблицы.
Подобным образом может использоваться анти-полусоединение для обработки подзапроса с NOT EXISTS.
Дополнение
Во всех представленных в статье примерах использовались предикаты соединения, который сравнивали, являются ли оба столбца каждой из соединяемых таблицы равными. Такой тип предикатов соединений принято называть «соединением по эквивалентности». Другие предикаты соединений (например, неравенства) тоже возможны, но соединения по эквивалентности распространены наиболее широко. В SQL Server заложено много альтернативных вариантов оптимизации соединений по эквивалентности и оптимизации соединений с более сложными предикатами.
SQL Server более гибок в выборе порядка соединения и его алгоритма при оптимизации внутренних соединений, чем при оптимизации внешних соединений и CROSS APPLY. Таким образом, если взять два запроса, которые отличаются только тем, что один использует исключительно внутренние соединения, а другой использует внешние соединения и/или CROSS APPLY, SQL Server сможет найти лучший план исполнения для запроса, который использует только внутренние соединения.
- sql server
- операторы в плане запроса
- SQL
- Microsoft SQL Server
8 способов объединения (JOIN) таблиц в SQL. Часть 1

Можно смело сказать, что операция объединения (JOIN) является наиболее мощной функциональной особенностью языка SQL. Эта операция — предмет зависти для всех нереляционных СУБД, поскольку ее концепция очень проста, но при этом широко применима в случаях, когда нужно объединить два набора данных.
Простыми словами, объединение двух таблиц заключается в объединении каждой строки первой таблицы с каждой строкой второй таблицы, для которых истинно значение некоторого предиката. Иллюстрация из мастер-класса по SQL демонстрирует эту концепцию:

Обратите также внимание на следующую статью, посвященную использованию диаграмм Венна (Venn diagram) для объяснения операции JOIN.
На рисунке выше представлена схема операции внутреннего объединения (INNER JOIN) в сравнении с различными операциями внешнего объединения (OUTER JOIN), но это далеко не все возможные варианты. Далее мы рассмотрим каждый из них в отдельности.
Обратите внимание, когда в данной статье мы говорим «X следует перед Y», имеется в виду, что «X логически следует перед Y». То есть, оптимизатор СУБД может выполнить Y раньше, чем X, в целях обеспечения более высокой производительности при неизменном результате. Подробнее о синтаксическом и логическом порядке операций вы моете прочитать в следующей статье.
Итак, давайте последовательно рассмотрим все типы объединений!
Перекрестное объединение (CROSS JOIN)
CROSS JOIN является базовым вариантом объединения и представляет собой декартово произведение (Cartesian product). Эта операция просто объединяет каждую строку первой таблицы с каждой строкой второй таблицы. Лучший пример, иллюстрирующий декартово произведение, представлен в Википедии. В этом примере мы получаем колоду карт, выполнив «перекрестное объединение» таблицы достоинств и таблицы мастей.

В реальных сценариях операция CROSS JOIN может быть очень полезна при создании отчетов. Например, мы можем сгенерировать набор дат (например, дни в месяце) (days) и выполнить перекрестное объединение со всеми отделами (departments), имеющимися в базе данных. В результате мы получим полную таблицу день/отдел. Используя синтаксис PostgreSQL:
SELECT * -- This just generates all the days in January 2017 FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day) -- Here, we're combining all days with all departments CROSS JOIN departments
Представим себе, что мы имеем следующие данные:
+--------+ +------------+ | day | | department | +--------+ +------------+ | Jan 01 | | Dept 1 | | Jan 02 | | Dept 2 | | . | | Dept 3 | | Jan 30 | +------------+ | Jan 31 | +--------+
Результат операции CROSS JOIN будет выглядеть следующим образом:
+--------+------------+ | day | department | +--------+------------+ | Jan 01 | Dept 1 | | Jan 01 | Dept 2 | | Jan 01 | Dept 3 | | Jan 02 | Dept 1 | | Jan 02 | Dept 2 | | Jan 02 | Dept 3 | | . | . | | Jan 31 | Dept 1 | | Jan 31 | Dept 2 | | Jan 31 | Dept 3 | +--------+------------+
Теперь для каждой комбинации день/отдел мы можем вычислить дневную выручку для данного отдела или другие аналогичные показатели.
Свойства
Как мы уже сказали, операция CROSS JOIN представляет собой декартово произведение. Соответственно, в математической нотации для описания данной операции используется знак умножения: A × B, или в нашем случае days × departments.
Как и в случае «обычного» арифметического умножения, если одна из двух таблиц пустая (имеет нулевой размер), результат также будет пустым. Это абсолютно логично. Если мы объединим 31 день и 0 отделов, мы получим 0 комбинаций день/отдел. Аналогично, если мы объединим пустой диапазон дат с любым количеством отделов, мы также получим 0 комбинаций день/отдел. Другими словами:
size(result) = size(days) * size(departments)
Альтернативный синтаксис
До того, как синтаксис операции JOIN был стандартизирован ANSI, чтобы реализовать CROSS JOIN, программисты просто использовали список разделенных запятыми таблиц в предложении FROM. Рассмотренный выше запрос эквивалентен следующему:
SELECT * FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day), departments
В общем случае для выполнения перекрестного объединения настоятельно рекомендуется использовать ключевые слова CROSS JOIN вместо альтернативного синтаксиса. Благодаря этому, другой программист сможет легко понять назначение данного фрагмента кода! Кроме того, использование альтернативного синтаксиса на основе списка разделенных запятыми таблиц чревато появлением ошибок, например, может произойти ненамеренное перекрестное объединение. Нам же не нужны такие проблемы!
Внутреннее объединение (INNER JOIN) или тета-объединение (THETA JOIN)
Развивая идею предыдущей операции CROSS JOIN, операция INNER JOIN (или просто JOIN, иногда также THETA JOIN) позволяет выполнять фильтрацию результата декартова произведения на основе некоторого предиката. Как правило, мы помещаем этот предикат в предложение ON. Таким образом, запрос принимает следующий вид:
SELECT * -- Same as before FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day) -- Now, exclude all days/departments combinations for -- days before the department was created JOIN departments AS d ON day >= d.created_at
В большинстве СУБД ключевое слово INNER является необязательным, поэтому мы просто не указываем его.
Операция INNER JOIN позволяет нам использовать произвольные предикаты в предложении ON, что опять же очень удобно при создании отчетов. Аналогично CROSS JOIN мы объединяем все дни со всеми отделами, но потом оставляем только те комбинации день/отдел, для которых данный отдел уже существовал в данный день.
Используем те же исходные данные:
+--------+ +------------+------------+ | day | | department | created_at | +--------+ +------------+------------+ | Jan 01 | | Dept 1 | Jan 10 | | Jan 02 | | Dept 2 | Jan 11 | | . | | Dept 3 | Jan 12 | | Jan 30 | +------------+------------+ | Jan 31 | +--------+
Получим следующий результат:
+--------+------------+ | day | department | +--------+------------+ | Jan 10 | Dept 1 | | Jan 11 | Dept 1 | | Jan 11 | Dept 2 | | Jan 12 | Dept 1 | | Jan 12 | Dept 2 | | Jan 12 | Dept 3 | | Jan 13 | Dept 1 | | Jan 13 | Dept 2 | | Jan 13 | Dept 3 | | . | . | | Jan 31 | Dept 1 | | Jan 31 | Dept 2 | | Jan 31 | Dept 3 | +--------+------------+
Результат операции содержит данные, начиная с 10 января. Более ранние даты были отфильтрованы.
Свойства
Операция INNER JOIN представляет собой операцию CROSS JOIN с фильтрацией. Это означает, что если одна из таблиц пустая, то результат также гарантированно будет пустым. По причине наличия предиката, результат операции INNER JOIN может быть меньшего объема, чем результат операции CROSS JOIN. Другими словами:
size(result)Альтернативный синтаксис
Несмотря на то, что предложение ON является обязательным для операции INNER JOIN, мы не обязаны указывать в нем предикат (хотя это крайне желательно в целях улучшения читаемости). Рассмотренный выше запрос эквивалентен следующему:
SELECT * FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day) -- You can always JOIN .. ON true (or 1 = 1 in other DBs) -- to turn an syntactic INNER JOIN into a semantic CROSS JOIN JOIN departments AS d ON true -- . and then turn the CROSS JOIN back into an INNER JOIN -- by putting the JOIN predicate in the WHERE clause: WHERE day >= d.created_atБезусловно, это просто запутывание кода, но ведь у нас могут быть свои причины, не так ли? Сделав еще один шаг, мы можем написать следующий запрос, который также является эквивалентным, поскольку большинство оптимизаторов способны распознать равнозначность и выполнить INNER JOIN:
SELECT * FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day) -- Now, this is really a syntactic CROSS JOIN CROSS JOIN departments AS d WHERE day >= d.created_atКак мы уже говорили, CROSS JOIN это лишь удобный синтаксис для списка разделенных запятыми таблиц. Во фрагменте кода, представленном ниже, мы также используем предложение WHERE, чтобы сформировать запрос, которым программисты часто пользовались до того, как синтаксис JOIN был стандартизирован:
SELECT * FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day), departments AS d WHERE day >= d.created_atВсе эти варианты альтернативного синтаксиса выполняют одну и ту же задачу, как правило, без потери производительности. Однако очевидно, что все они значительно хуже читаются по сравнению со стандартным синтаксисом INNER JOIN.
Объединение на основе равенства (EQUI JOIN)
Иногда в литературе встречается термин EQUI JOIN. На самом деле, «EQUI» не является ключевым словом SQL, а просто обозначает специальный вариант записи особого случая операции INNER JOIN.
Следует отметить, что не совсем правомерно называть EQUI JOIN особым случаем, поскольку эту операцию мы выполняем чаще всего в SQL и OLTP приложениях, когда просто объединяем таблицы на основе отношения первичного/внешнего ключа. Например:
SELECT * FROM actor AS a JOIN film_actor AS fa ON a.actor_id = fa.actor_id JOIN film AS f ON f.film_id = fa.film_idПредставленный выше запрос извлекает всех актеров и фильмы, в которых они снимались. В нем присутствуют две операции INNER JOIN. Первая из них объединяет таблицу актеров actor и соответствующие записи из таблицы film_actor, содержащей информацию об отношениях фильм/актер (поскольку каждый актер может играть во множестве фильмов, а в каждом фильме может играть множество актеров). Вторая операция INNER JOIN выполняет объединение с таблицей film, содержащей информацию о фильмах.
Свойства
Данная операция имеет те же свойства, что и «обычная» операция INNER JOIN. То есть EQUI JOIN также является декартовым произведением (CROSS JOIN) с отфильтрованным результатом. В частности, в нашем случае результат содержит только те комбинации актер/фильм, для которых данный актер действительно играл в данном фильме. Таким образом, мы снова имеем соотношение:
size(result)Объем результата может быть равен полному декартову произведению таблиц actor и film только в том случае, если каждый актер играл в каждом фильме, что маловероятно.
Альтернативный синтаксис: USING
Опять же, мы могли бы записать операцию EQUI JOIN, используя CROSS JOIN или список разделенных запятыми таблиц, но это уже не интересно. Значительно больший интерес представляют два варианта альтернативного синтаксиса, представленные ниже, один из которых является очень полезным.
SELECT * FROM actor JOIN film_actor USING (actor_id) JOIN film USING (film_id)Предложение USING заменяет предложение ON и позволяет указать набор столбцов, которые должны присутствовать в обеих объединяемых таблицах. Если наша база данных была хорошо спроектирована (как, например, база данных Sakila), то есть, если каждый внешний ключ имеет такое же имя, как и соответствующий первичный ключ (например, actor.actor_id = film_actor.actor_id), тогда мы можем использовать предложение USING для реализации операции EQUI JOIN, как минимум, в следующих СУБД:
- Derby
- Firebird
- HSQLDB
- Ingres
- MariaDB
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Vertica
Следующие СУБД, к сожалению, не поддерживают данный синтаксис:
- Access
- Cubrid
- DB2
- H2
- HANA
- Informix
- SQL Server
- Sybase ASE
- Sybase SQL Anywhere
Запрос с предложением USING (почти) идентичен запросу с предложением ON, однако значительно более удобен для написания и восприятия. Мы сказали «почти», потому что согласно спецификации некоторых СУБД (и стандарту SQL) столбец, используемый в предложении USING, не должен иметь квалификатор. Например:
SELECT f.title, -- Ordinary column, can be qualified f.film_id, -- USING column, shouldn't be qualified film_id -- USING column, correct / non-ambiguous here FROM actor AS a JOIN film_actor AS fa USING (actor_id) JOIN film AS f USING (film_id)
Безусловно, этот синтаксис также имеет свои ограничения. Иногда в таблице может быть внешний ключ, имя которого не соответствует первичному ключу. Например:
CREATE TABLE film ( .. language_id BIGINT REFERENCES language, original_language_id BIGINT REFERENCES language, )
Если мы хотим выполнить объединение по original_language_id, нам придется использовать предложение ON.
Альтернативный синтаксис: Естественное объединение (NATURAL JOIN)
Более экстремальным и значительно менее полезным вариантом синтаксиса операции EQUI JOIN является синтаксис на основе предложения NATURAL JOIN. Рассмотренный выше синтаксис на основе USING можно «улучшить», заменив USING на NATURAL JOIN следующим образом:
SELECT * FROM actor NATURAL JOIN film_actor NATURAL JOIN film
Обратите внимание, в этом запросе нет необходимости указывать какие-либо критерии объединения, поскольку предложение NATURAL JOIN автоматически определяет столбцы, имеющие одинаковые имена в обеих объединяемых таблица, и помещает их в «скрытое» предложение USING. Если первичные и внешние ключи имеют одинаковые имена, этот подход может показаться полезным, однако это не так.
В базе данных Sakila, каждая таблица имеет столбец last_update, который автоматически используется предложением NATURAL JOIN. Таким образом, запрос NATURAL JOIN эквивалентен следующему запросу, который, конечно же, не имеет никакого смысла:
SELECT * FROM actor JOIN film_actor USING (actor_id, last_update) JOIN film USING (film_id, last_update)
Итак, сразу же забудьте о NATURAL JOIN и никогда не используйте этот вариант (за исключением очень редких случаев, таких как объединение диагностических представлений Oracle, например, v$sql NATURAL JOIN v$sql_plan, в целях специализированной аналитики).
Внешнее объединение (OUTER JOIN)
Мы рассмотрели операцию INNER JOIN, возвращающую только те комбинации строк левой/правой таблицы, для которых значение предиката в предложении ON является истинным.
Операция OUTER JOIN позволяет нам включить в результат строки одной таблицы, для которых не были найдены соответствующие строки в другой таблице.
Левое внешнее объединение (LEFT OUTER JOIN)
Давайте вернемся к примеру с датами и отделами:
SELECT * FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day) LEFT JOIN departments AS d ON day >= d.created_at
Ключевое слово «OUTER» является необязательным, поэтому мы его не указываем.
Этот запрос отличается от подобного запроса INNER JOIN лишь тем, что всегда будет возвращать хотя бы одну строку для каждого дня, даже если в данный день еще не существовало ни одного отдела. В частности, в нашем примере все отделы были созданы не ранее 10 января, но запрос все равно вернет строки, соответствующие 1–9 января.
+--------+ +------------+------------+ | day | | department | created_at | +--------+ +------------+------------+ | Jan 01 | | Dept 1 | Jan 10 | | Jan 02 | | Dept 2 | Jan 11 | | . | | Dept 3 | Jan 12 | | Jan 30 | +------------+------------+ | Jan 31 | +--------+
Кроме строк, которые мы получили бы с помощью запроса INNER JOIN, в результате запроса LEFT OUTER JOIN также присутствуют строки, соответствующие 1–9 января, с пустыми (NULL) значениями отделов:
+--------+------------+ | day | department | +--------+------------+ | Jan 01 | | -- Extra rows with no match here | Jan 02 | | -- Extra rows with no match here | . | | -- Extra rows with no match here | Jan 09 | | -- Extra rows with no match here | Jan 10 | Dept 1 | | Jan 11 | Dept 1 | | Jan 11 | Dept 2 | | Jan 12 | Dept 1 | | Jan 12 | Dept 2 | | Jan 12 | Dept 3 | | Jan 13 | Dept 1 | | Jan 13 | Dept 2 | | Jan 13 | Dept 3 | | . | . | | Jan 31 | Dept 1 | | Jan 31 | Dept 2 | | Jan 31 | Dept 3 | +--------+------------+
Как видите, каждый день хотя бы один раз присутствует в результате запроса. LEFT OUTER JOIN выполняет данную операцию для левой таблицы, то есть возвращает все строки левой таблицы.
Формально, операцию LEFT OUTER JOIN можно выразить операцией INNER JOIN с предложением UNION:
-- Convenient syntax: SELECT * FROM a LEFT JOIN b ON -- Cumbersome, equivalent syntax: SELECT a.*, b.* FROM a JOIN b ON UNION ALL SELECT a.*, NULL, NULL, . NULL FROM a WHERE NOT EXISTS ( SELECT * FROM b WHERE )
Мы обсудим NOT EXISTS далее в этой статье, когда будем рассматривать операцию SEMI JOIN.
Правое внешнее объединение (RIGHT OUTER JOIN)
Операция RIGHT OUTER JOIN выполняет ту же задачу, что и LEFT OUTER JOIN, но для правой таблицы, то есть возвращает в результате все строки правой таблицы. Немного модифицируем наши данные, добавив пару отделов:
+--------+ +------------+------------+ | day | | department | created_at | +--------+ +------------+------------+ | Jan 01 | | Dept 1 | Jan 10 | | Jan 02 | | Dept 2 | Jan 11 | | . | | Dept 3 | Jan 12 | | Jan 30 | | Dept 4 | Apr 01 | | Jan 31 | | Dept 5 | Apr 02 | +--------+ +------------+------------+
Новые отделы 4 и 5 не попали бы в результат запроса INNER JOIN, поскольку были созданы после 31 января. Однако эти отделы появятся в результате запроса RIGHT OUTER JOIN, поскольку эта операция возвращает все строки правой таблицы.
Выполним следующий запрос:
SELECT * FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day) RIGHT JOIN departments AS d ON day >= d.created_at
Получим следующий результат:
+--------+------------+ | day | department | +--------+------------+ | Jan 10 | Dept 1 | | Jan 11 | Dept 1 | | Jan 11 | Dept 2 | | Jan 12 | Dept 1 | | Jan 12 | Dept 2 | | Jan 12 | Dept 3 | | Jan 13 | Dept 1 | | Jan 13 | Dept 2 | | Jan 13 | Dept 3 | | . | . | | Jan 31 | Dept 1 | | Jan 31 | Dept 2 | | Jan 31 | Dept 3 | | | Dept 4 | -- Extra rows with no match here | | Dept 5 | -- Extra rows with no match here +--------+------------+
В большинстве случаев (я еще не сталкивался с ситуацией, для которой это утверждение не верно), выражение LEFT OUTER JOIN можно преобразовать в эквивалентное выражение RIGHT OUTER JOIN, и наоборот. Поскольку RIGHT OUTER JOIN обеспечивает меньшее удобство восприятия, большинство программистов используют только LEFT OUTER JOIN.
Полное внешнее объединение (FULL OUTER JOIN)
Существует также операция FULL OUTER JOIN, которая возвращает в результате все строки как левой, так и правой таблицы. Для нашего примера это означает, что каждый день и каждый отдел хотя бы один раз появляются в результате запроса.
Используем те же данные:
+--------+ +------------+------------+ | day | | department | created_at | +--------+ +------------+------------+ | Jan 01 | | Dept 1 | Jan 10 | | Jan 02 | | Dept 2 | Jan 11 | | . | | Dept 3 | Jan 12 | | Jan 30 | | Dept 4 | Apr 01 | | Jan 31 | | Dept 5 | Apr 02 | +--------+ +------------+------------+
Выполним следующий запрос:
SELECT * FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day) FULL JOIN departments AS d ON day >= d.created_at
Получим следующий результат:
+--------+------------+ | day | department | +--------+------------+ | Jan 01 | | -- row from the left table | Jan 02 | | -- row from the left table | . | | -- row from the left table | Jan 09 | | -- row from the left table | Jan 10 | Dept 1 | | Jan 11 | Dept 1 | | Jan 11 | Dept 2 | | Jan 12 | Dept 1 | | Jan 12 | Dept 2 | | Jan 12 | Dept 3 | | Jan 13 | Dept 1 | | Jan 13 | Dept 2 | | Jan 13 | Dept 3 | | . | . | | Jan 31 | Dept 1 | | Jan 31 | Dept 2 | | Jan 31 | Dept 3 | | | Dept 4 | -- row from the right table | | Dept 5 | -- row from the right table +--------+------------+
Формально, операцию FULL OUTER JOIN можно выразить операцией INNER JOIN с предложением UNION:
-- Convenient syntax: SELECT * FROM a FULL JOIN b ON -- Cumbersome, equivalent syntax: SELECT a.*, b.* FROM a JOIN b ON -- LEFT JOIN part UNION ALL SELECT a.*, NULL, NULL, . NULL FROM a WHERE NOT EXISTS ( SELECT * FROM b WHERE ) -- RIGHT JOIN part UNION ALL SELECT NULL, NULL, . NULL, b.* FROM b WHERE NOT EXISTS ( SELECT * FROM a WHERE )
Альтернативный синтаксис: Внешнее объединение на основе равенства (EQUI OUTER JOIN)
Рассмотренные выше операции опять же представляют собой объединения типа «декартово произведение с фильтрацией». Однако более распространенным является подход EQUI OUTER JOIN, в рамках которого мы выполняем объединение на основе отношения первичного/внешнего ключа. Используем для примера базу данных Sakila. Некоторые актеры не снялись ни в одном фильме. Мы можем извлечь их следующим образом:
SELECT * FROM actor LEFT JOIN film_actor USING (actor_id) LEFT JOIN film USING (film_id)
В результате этого запроса каждый актер будет присутствовать хотя бы один раз, независимо от того, принимал ли он участие в каком-либо фильме. Если мы также хотим извлечь все фильмы, в которых не снимался ни один из данных актеров, мы можем применить FULL OUTER JOIN:
SELECT * FROM actor FULL JOIN film_actor USING (actor_id) FULL JOIN film USING (film_id)
Безусловно, в качестве альтернативы можно было бы использовать NATURAL LEFT JOIN, NATURAL RIGHT JOIN, NATURAL FULL JOIN, но, как мы уже говорили ранее, в таком случае в объединении автоматически был бы учтен столбец last_update, присутствующий во всех таблицах базы данных Sakila (т.е. USING (…, last_update)), что лишает операцию всякого смысла.
Альтернативный синтаксис: Внешнее объединение (OUTER JOIN) в стиле Oracle и SQL Server
До введения стандартного синтаксиса СУБД Oracle и SQL Server поддерживали операцию внешнего объединения в следующем виде:
-- Oracle SELECT * FROM actor a, film_actor fa, film f WHERE a.actor_id = fa.actor_id(+) AND fa.film_id = f.film_id(+) -- SQL Server SELECT * FROM actor a, film_actor fa, film f WHERE a.actor_id *= fa.actor_id AND fa.film_id *= f.film_id
Можно смело сказать, что этот синтаксис является устаревшим.
Разработчики SQL Server поступили правильно, вначале объявив этот синтаксис нежелательным, и в дальнейшем отказавшись от него. Oracle по-прежнему поддерживает его для обратной совместимости.
Нет никаких аргументов в пользу данного альтернативного синтаксиса. Используйте вместо него стандартный синтаксис ANSI.
Внешнее объединение с разделением (PARTITIONED OUTER JOIN)
Эта операция поддерживается только Oracle. На самом деле, просто удивительно, что другие СУБД до сих пор не реализовали ее. Помните операцию CROSS JOIN, которую мы использовали, чтобы получить все комбинации день/отдел? Так вот, иногда мы хотим получить следующий результат: все комбинации, а также, если выполняется условие, поместить в данную строку соответствующее значение.
Эту операцию трудно объяснить словами. Намного легче сделать это на примере. Ниже представлен запрос, использующий синтаксис Oracle:
WITH -- Using CONNECT BY to generate all dates in January days(day) AS ( SELECT DATE '2017-01-01' + LEVEL - 1 FROM dual CONNECT BY LEVEL = created_at
Предложение PARTITION BY используется в различных контекстах для решения различных задач (например, для реализации оконных функций (window function)). В нашем случае PARTITION BY означает, что мы «разделяем» наши данные по значениям столбца departments.department, создавая таким образом «подгруппу» для каждого отдела. Затем каждая «подгруппа» получает копию всех дней, независимо от того, выполняется ли условие предиката (в отличие от обычной операции LEFT OUTER JOIN, в результате которой, часть дней имели пустые значения отделов). Представленный выше запрос даст следующий результат:
+--------+------------+------------+ | day | department | created_at | +--------+------------+------------+ | Jan 01 | Dept 1 | | -- Didn't match, but still get row | Jan 02 | Dept 1 | | -- Didn't match, but still get row | . | Dept 1 | | -- Didn't match, but still get row | Jan 09 | Dept 1 | | -- Didn't match, but still get row | Jan 10 | Dept 1 | Jan 10 | -- Matches, so get join result | Jan 11 | Dept 1 | Jan 10 | -- Matches, so get join result | Jan 12 | Dept 1 | Jan 10 | -- Matches, so get join result | . | Dept 1 | Jan 10 | -- Matches, so get join result | Jan 31 | Dept 1 | Jan 10 | -- Matches, so get join result | Jan 01 | Dept 2 | | -- Didn't match, but still get row | Jan 02 | Dept 2 | | -- Didn't match, but still get row | . | Dept 2 | | -- Didn't match, but still get row | Jan 09 | Dept 2 | | -- Didn't match, but still get row | Jan 10 | Dept 2 | | -- Didn't match, but still get row | Jan 11 | Dept 2 | Jan 11 | -- Matches, so get join result | Jan 12 | Dept 2 | Jan 11 | -- Matches, so get join result | . | Dept 2 | Jan 11 | -- Matches, so get join result | Jan 31 | Dept 2 | Jan 11 | -- Matches, so get join result | Jan 01 | Dept 3 | | -- Didn't match, but still get row | Jan 02 | Dept 3 | | -- Didn't match, but still get row | . | Dept 3 | | -- Didn't match, but still get row | Jan 09 | Dept 3 | | -- Didn't match, but still get row | Jan 10 | Dept 3 | | -- Didn't match, but still get row | Jan 11 | Dept 3 | | -- Didn't match, but still get row | Jan 12 | Dept 3 | Jan 12 | -- Matches, so get join result | . | Dept 3 | Jan 12 | -- Matches, so get join result | Jan 31 | Dept 3 | Jan 12 | -- Matches, so get join result | Jan 01 | Dept 4 | | -- Didn't match, but still get row | Jan 02 | Dept 4 | | -- Didn't match, but still get row | . | Dept 4 | | -- Didn't match, but still get row | Jan 31 | Dept 4 | | -- Didn't match, but still get row | Jan 01 | Dept 5 | | -- Didn't match, but still get row | Jan 02 | Dept 5 | | -- Didn't match, but still get row | . | Dept 5 | | -- Didn't match, but still get row | Jan 31 | Dept 5 | | -- Didn't match, but still get row +--------+------------+------------+
Как видите, мы имеем 5 «подгрупп», соответствующих 5 отделам. Каждая «подгруппа» объединяет данный отдел с каждым днем, но в отличие от CROSS JOIN, мы получаем результат LEFT OUTER JOIN .. ON .. в том случае, когда выполняется условие предиката. Это действительно полезная функциональность для создания отчетов в Oracle!
Соединения (JOINS) — Основы реляционных баз данных
Реляционная модель подразумевает связь между данными разных отношений посредством внешних ключей. С практической точки зрения это можно сформулировать так — зная первичный ключ одной сущности, мы можем извлечь связанные с ней данные из другой сущности.
В простых ситуациях данные извлекаются так:
-- Извлекаем все топики пользователя с style="color: #000000;font-weight: bold">SELECT * FROM topics WHERE user_id = 3; Но есть множество ситуаций, где простой выборкой не обойтись. Для этого нужна операция JOIN , которую мы изучим в этом уроке.
JOIN
Для примера попробуем найти всех пользователей Хекслета, которые ни разу не создавали топики. На текущий момент мы знаем ровно один способ выполнить эту задачу. Нужно выполнить два шага:
-
Извлечь из базы всех пользователей, которые создали хотя бы один топик:
SELECT DISTINCT user_id FROM topics; SELECT * FROM users WHERE id NOT IN(список идентификаторов, полученный предыдущим запросом>); Задача будет решена, но есть одна проблема. Идентификаторов может быть очень много. Гонять такое количество записей из базы в код и обратно — не самая разумная идея.
INNER JOIN
Теперь рассмотрим следующую задачу — найти записи о пользователях в одной таблице, для которых нет записей о топиках в другой таблице.
Реляционная алгебра позволяет выполнить эту операцию с помощью соединения JOIN , используя ровно один запрос. Начнем знакомство с JOIN на таком примере:
-- В выборке участвуют не все поля только для того, чтобы уместить -- ее на экран, а вообще здесь можно использовать `*` SELECT first_name, title FROM users JOIN topics ON users.id = topics.user_id LIMIT 5; first_name | title ------------+------------------------------ Sean | beatae voluptatem commodi Wyatt | tempora accusamus nostrum Oleta | eaque fugiat consequatur Brandon | aut exercitationem expedita Domenica | voluptatem soluta similique Результатом такого запроса станет выборка, в которую попали поля обеих таблиц. Здесь соединяются две таблицы: users и topics по условию users.id = topics.user_id . Это важное условие для правильной работы.
В нашем примере отношения связаны внешним ключом: соответственно, при объединении этих таблиц нужно явно указать, как мы их соединяем. Общий синтаксис выглядит так:
На самом деле общая форма сложнее, потому что объединять можно произвольное число таблиц. Другими словами, условий соединения может быть много.
JOIN — это сокращенная версия соединения INNER JOIN , то есть внутреннего соединения.
В эту выборку попадают только те записи, для которых есть соответствие в другой таблице. Причем, если у одного пользователя пять топиков, то в выборке окажутся все пять строк. Такой запрос имеет смысл делать на странице вывода топиков, что позволит к каждому топику сразу же вывести нужную информацию и о самом пользователе.
Запросы с соединениями порождают одну небольшую проблему. В примере выше часть SELECT содержит только те поля, имена которых уникальны среди всех полей обеих таблиц. Соответственно, при выборке не возникает неоднозначностей.
Если выполнить этот же запрос со звездочкой, то в выборку попадут поля, у которых одинаковые названия, что создаст сложности при анализе данных уже в коде приложения. А при выполнении запроса с указанием дублирующихся полей вообще возникнет ошибка:
SELECT id FROM users JOIN topics ON users.id = topics.user_id LIMIT 5; ERROR: column reference "id" is ambiguous LINE 1: SELECT id FROM users JOIN topics ON users.id = topics.user_i. В таких случаях спасают псевдонимы и возможность указывать таблицу для каждого поля:
SELECT users.id AS user_id, topics.id AS topic_id FROM users JOIN topics ON users.id = topics.user_id LIMIT 5; user_id | topic_id ---------+---------- 9 | 1 33 | 2 43 | 3 49 | 4 10 | 5 (5 rows) LEFT JOIN
Пока мы все еще не можем решить нашу исходную задачу. Для этого понадобится операция левого соединения LEFT JOIN :
LEFT JOIN берет все данные из одной таблицы и присоединяет к ним данные из другой, если они присутствуют. Если нет, то заполняет их NULL . Чисто технически этот запрос отличается только тем, что добавляется слово LEFT :
SELECT first_name, title FROM users LEFT JOIN topics ON users.id = topics.user_id LIMIT 5; first_name | title ------------+------------------------------ Sean | beatae voluptatem commodi Wyatt | tempora accusamus nostrum Mia | Royal | Enos | et eos dicta LEFT JOIN полезен, когда нам нужно работать со всеми данными одной таблицы и связанными с ними записями, если они есть. Если их нет, то ничего страшного, мы все равно хотим получить данные из первой таблицы.
Этот запрос все еще не возвращает нам то, что мы хотели изначально — записи о пользователях, которые не оставили ни одного топика на Хекслете. Чтобы закончить решение, нужно добавить в выборку условие WHERE :
SELECT COUNT(*) FROM users LEFT JOIN topics ON users.id = topics.user_id WHERE title IS NULL; count ------- 59 (1 row) Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Наши выпускники работают в компаниях: