11 фишек для извлечения и сохранения данных с сайтов

В закладки

БЕЗ скриптов, макросов, регулярных выражений и командной строки.
Эта статья пригодится студентам, которые хотят скачать все картинки с сайта разом, чтобы потом одним движением вставить их в Power Point и сразу получить готовую презентацию. Владельцам электронных библиотек, которые собирают новые книги по ресурсам конкурентов. Просто людям, которые хотят сохранить интересный сайт/страницу в соцсети, опасаясь, что те могут скоро исчезнуть, а также менеджерам, собирающим базы контактов для рассылок.
Есть три основные цели извлечения/сохранения данных с сайта на свой компьютер:
- Чтобы не пропали;
- Чтобы использовать чужие картинки, видео, музыку, книги в своих проектах (от школьной презентации до полноценного веб-сайта);
- Чтобы искать на сайте информацию средствами Spotlight, когда Google не справляется (к примеру поиск изображений по exif-данным или музыки по исполнителю).
Ситуации, когда неожиданно понадобится автоматизированно сохранить какую-ту информацию с сайта, могут случиться с каждым и надо быть к ним готовым. Если вы умеете писать скрипты для работы с утилитами wget/curl, то можете смело закрывать эту статью. А если нет, то сейчас вы узнаете о самых простых приемах сохранения/извлечения данных с сайтов.
1. Скачиваем сайт целиком для просмотра оффлайн
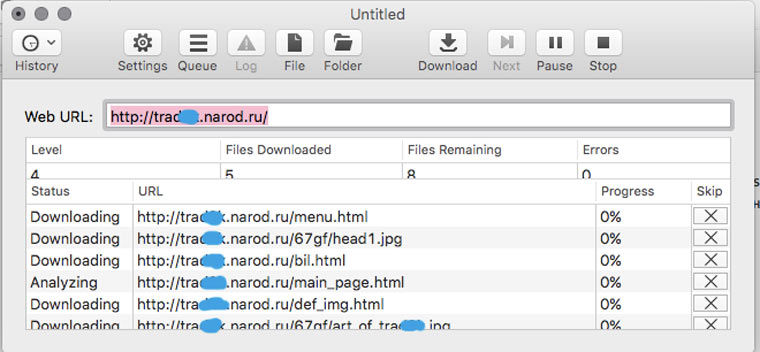
В OS X это можно сделать с помощью приложения HTTrack Website Copier, которая настраивается схожим образом.
Пользоваться Site Sucker очень просто. Открываем программу, выбираем пункт меню File -> New, указываем URL сайта, нажимаем кнопку Download и дожидаемся окончания скачивания.
Чтобы посмотреть сайт надо нажать на кнопку Folder, найти в ней файл index.html (главную страницу) и открыть его в браузере. SiteSucker скачивает только те данные, которые доступны по протоколу HTTP. Если вас интересуют исходники сайта (к примеру, PHP-скрипты), то для этого вам нужно в открытую попросить у его разработчика FTP-доступ.
2. Прикидываем сколько на сайте страниц
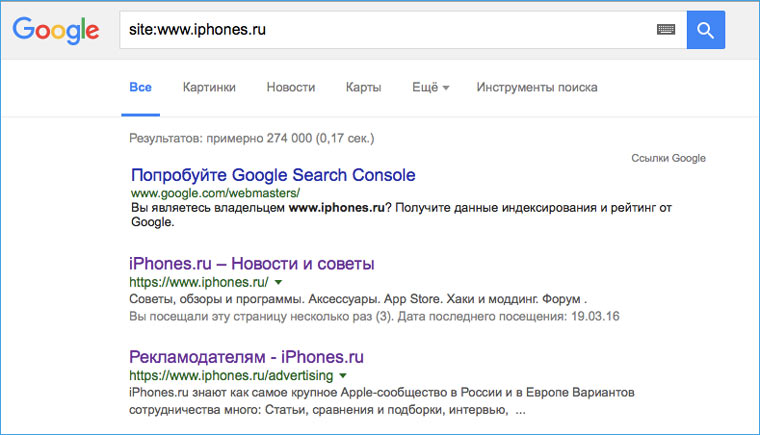
Перед тем как браться за скачивание сайта, необходимо приблизительно оценить его размер (не затянется ли процесс на долгие часы). Это можно сделать с помощью Google. Открываем поисковик и набираем команду site: адрес искомого сайта. После этого нам будет известно количество проиндексированных страниц. Эта цифра не соответствуют точному количеству страниц сайта, но она указывает на его порядок (сотни? тысячи? сотни тысяч?).
3. Устанавливаем ограничения на скачивание страниц сайта
![]()
Если вы обнаружили, что на сайте тысячи страниц, то можно ограничить число уровней глубины скачивания. К примеру, скачивать только те страницы, на которые есть ссылка с главной (уровень 2). Также можно ограничить размер загружаемых файлов, на случай, если владелец хранит на своем ресурсе tiff-файлы по 200 Мб и дистрибутивы Linux (и такое случается).
Сделать это можно в Settings -> Limits.
4. Скачиваем с сайта файлы определенного типа
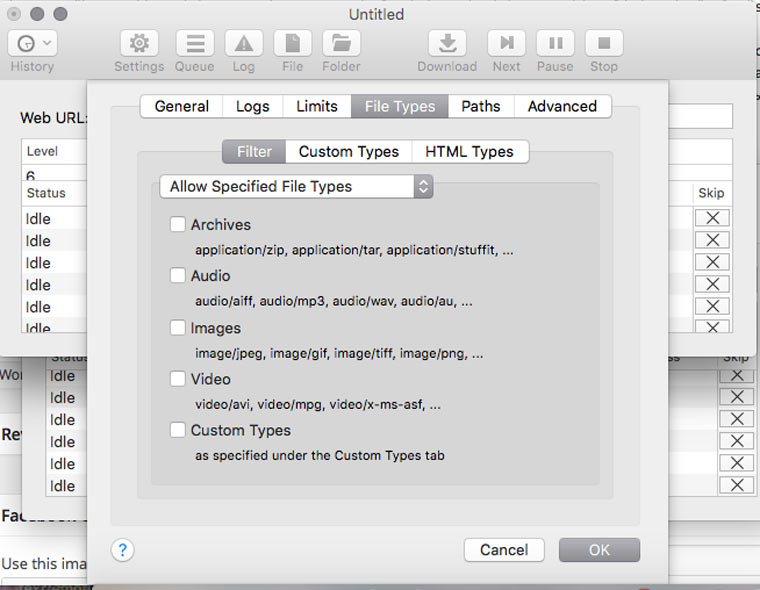
В Settings -> File Types -> Filters можно указать какие типы файлов разрешено скачивать, либо какие типы файлов запрещено скачивать (Allow Specified Filetypes/Disallow Specifies Filetypes). Таким образом можно извлечь все картинки с сайта (либо наоборот игнорировать их, чтобы места на диске не занимали), а также видео, аудио, архивы и десятки других типов файлов (они доступны в блоке Custom Types) от документов MS Word до скриптов на Perl.
5. Скачиваем только определенные папки
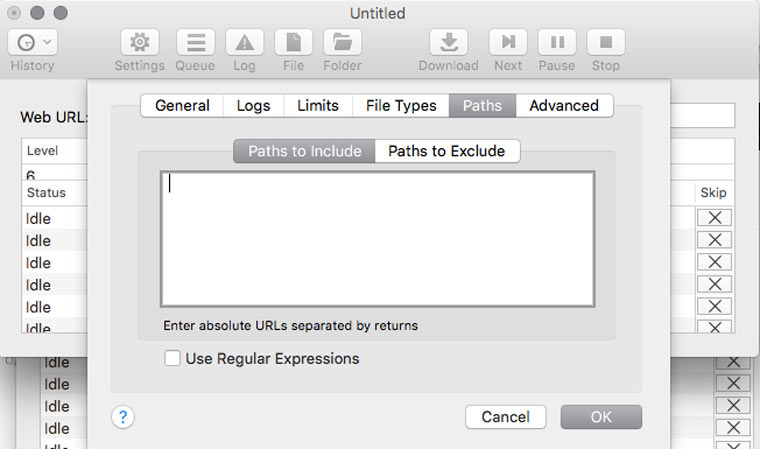
Если на сайте есть книги, чертежи, карты и прочие уникальные и полезные материалы, то они, как правило, лежат в отдельном каталоге (его можно отследить через адресную строку браузера) и можно настроить SiteSucker так, чтобы скачивать только его. Это делается в Settings -> Paths -> Paths to Include. А если вы хотите наоборот, запретить скачивание каких-то папок, то их адреса надо указать в блоке Paths to Exclude
6. Решаем вопрос с кодировкой
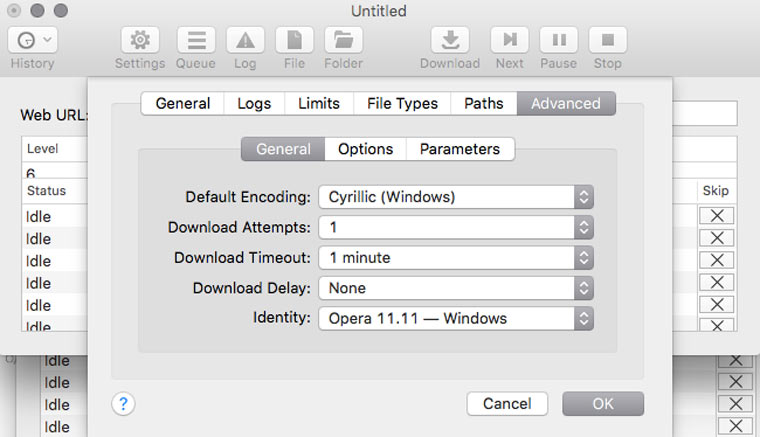
Если вы обнаружили, что скачанные страницы вместо текста содержат кракозябры, там можно попробовать решить эту проблему, поменяв кодировку в Settings -> Advanced -> General. Если неполадки возникли с русским сайтом, то скорее всего нужно указать кодировку Cyrillic Windows. Если это не сработает, то попробуйте найти искомую кодировку с помощью декодера Лебедева (в него надо вставлять текст с отображающихся криво веб-страниц).
7. Делаем снимок веб-страницы

Сделать снимок экрана умеет каждый. А знаете ли как сделать снимок веб-страницы целиком? Один из способов — зайти на web-capture.net и ввести там ссылку на нужный сайт. Не торопитесь, для сложных страниц время создания снимка может занимать несколько десятков секунд. Еще это можно провернуть в Google Chrome, а также в других браузерах с помощью дополнения iMacros.
Это может пригодиться для сравнения разных версий дизайна сайта, запечатления на память длинных эпичных перепалок в комментариях или в качестве альтернативы способу сохранения сайтов, описанного в предыдущих шести пунктах.
8. Сохраняем картинки только с определенной страницы
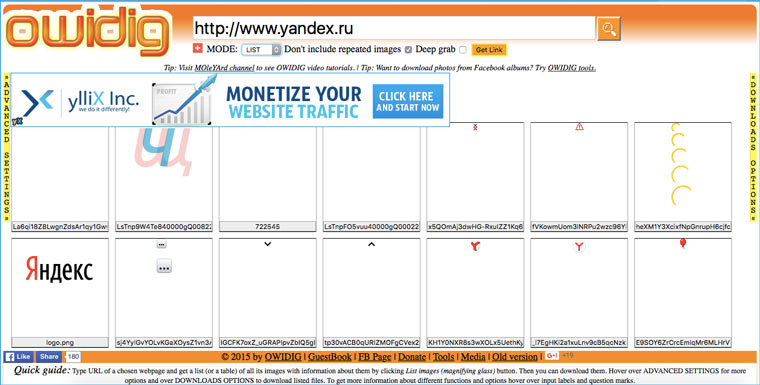
Идем на owdig.com, указываем нужную ссылку, ждем когда отобразятся все картинки и кликаем на оранжевую полоску справа, чтобы скачать их в архиве.
9. Извлекаем HEX-коды цветов с веб-сайта
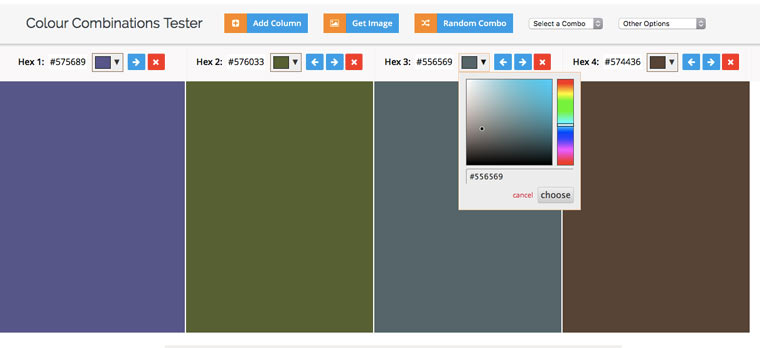
Идем на colorcombos.com и набираем адрес искомой страницы и получаем полный список цветов, которые использованы на ней.
10. Извлекаем из текста адреса электронной почты

Предположим, что вам надо сделать рассылку по сотрудникам компании, а их email-адреса есть только на странице корпоративного сайта и копировать их оттуда в ручную займет лишние 20-30 минут. В такой ситуации на помощь приходит сервис emailx.discoveryvip.com. Просто вставьте туда текст и через секунду вы получите список всех адресов электронной почты, которые в нем найдены.
11. Извлекаем из текста номера телефонов
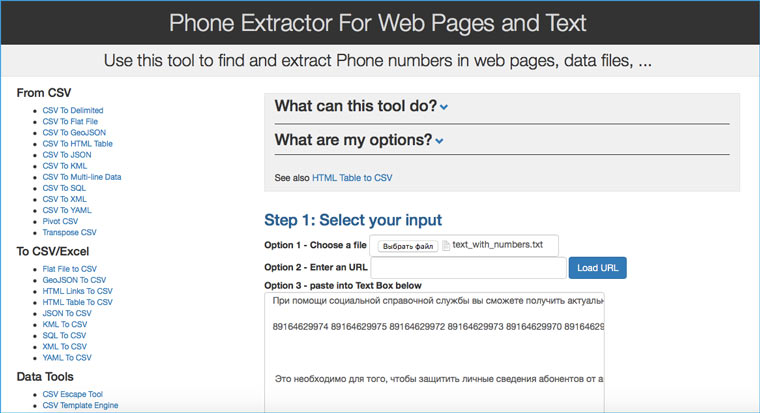
Идем на convertcsv.com/phone-extractor.htm, копируем в форму текст/html-код, содержащий номера телефонов и нажимаем на кнопку Extract.
А если надо отфильтровать в тексте заголовки, даты и прочую информацию, то к вам на помощь придут регулярные выражения и Sublime Text.
Есть и другие способы извлечения данных с сайтов. Можно попросить какую-ту информацию непосредственно у владельца ресурса, cохранять части веб-страниц с помощью iMacros и парсить сайты с помощью Google Apps Script. Еще можно пойти традиционным путем и написать для парсинга bash-скрипт, но статей об этом на iPhones.ru пока нет.
(4 голосов, общий рейтинг: 4.50 из 5)
�� Хочешь ещё? Читай больше в Telegram
�� Ищешь ответ на вопрос? Приходи на Форум
БЕЗ скриптов, макросов, регулярных выражений и командной строки. Эта статья пригодится студентам, которые хотят скачать все картинки с сайта разом, чтобы потом одним движением вставить их в Power Point и сразу получить готовую презентацию. Владельцам электронных библиотек, которые собирают новые книги по ресурсам конкурентов. Просто людям, которые хотят сохранить интересный сайт/страницу в соцсети, опасаясь, что.
Как сохранить данные с сайта в csv-файл
Всем привет. У меня очень тупой вопрос. Сразу скажу, что я не программист. Мне хотелось бы иметь скрипт, который берёт данные архива тиражей лотереи Гослото 5 из 36 с официального сайта (то есть выпавшие номера шаров) https://www.stoloto.ru/5x36plus/archive и записывает их в csv-файл. Как это можно сделать?
Отслеживать
задан 2 ноя 2017 в 17:49
Mihaylow28 Mihaylow28
11 2 2 бронзовых знака
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Выполните в консоли браузера на вкладке с этим сайтом скрипт
$('.container.cleared:not(".sorted") > b') .map(function() < return this.innerText; >) .toArray() .reduce(function(acc, current, position) < acc += position % 6 ? ',' : '\n'; return acc += current; >, ''); и затем, то, что выведется в результате сохраните на компьютере в файле с расширением «.csv».
Это будет самым простым для вас вариантом, не требующим установки специальных утилит и т.д.
Парсинг нетабличных данных с сайтов
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data — From internet) , вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ) и нажать ОК: 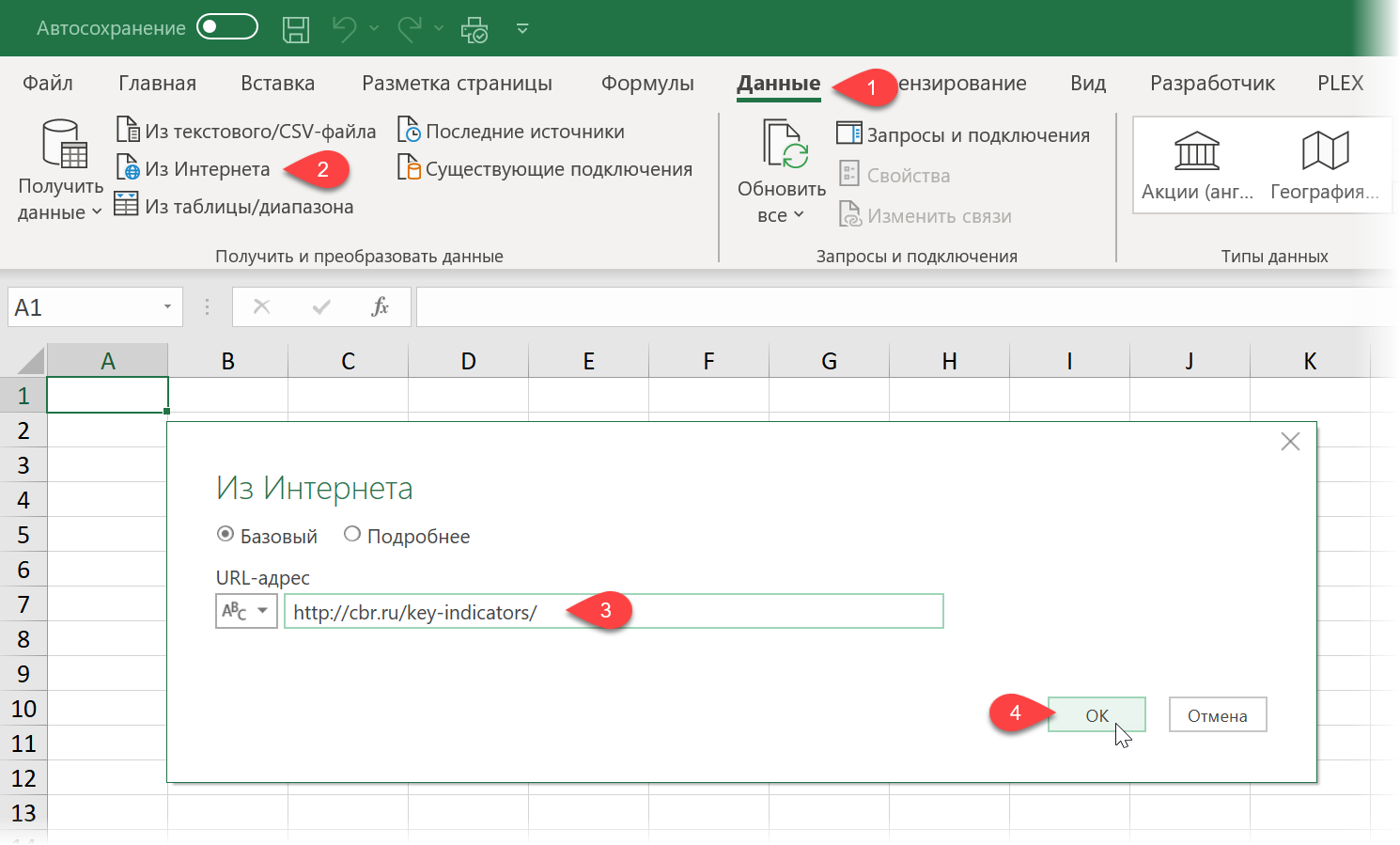
Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора: 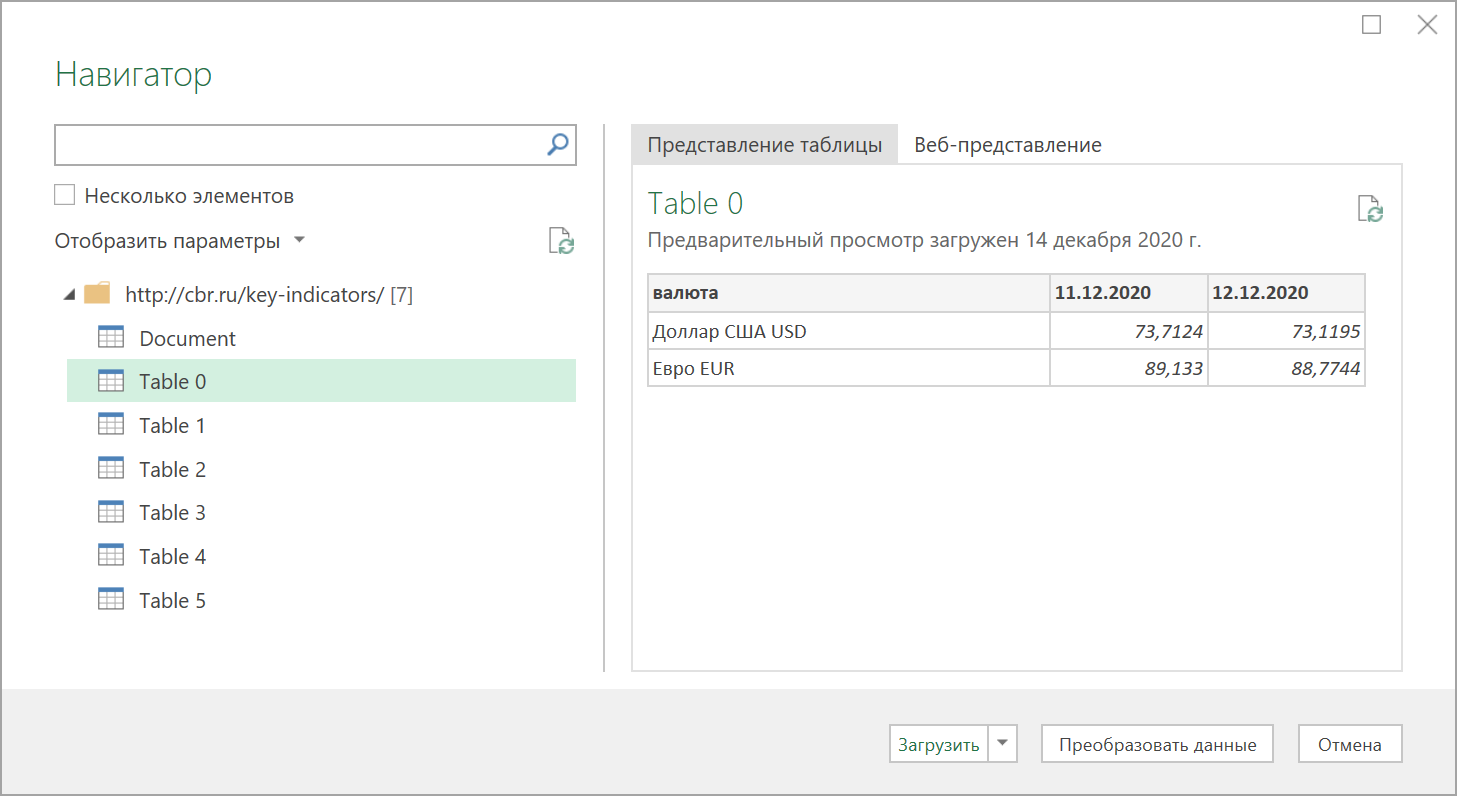
Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные) или сразу на лист Excel (кнопка Загрузить).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию — считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query «не видит» таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2. или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом , а её аналог — вложенные друг в друга теги-контейнеры . Это весьма распространённая техника при вёрстке веб-сайтов, но, к сожалению, Power Query пока не умеет распознавать такую разметку и загружать такие данные в Excel. Тем не менее, есть способ обойти это ограничение 😉
В качестве тренировки, давайте попробуем загрузить цены и описания товаров с маркетплейса Wildberries — например, книг из раздела Детективы: 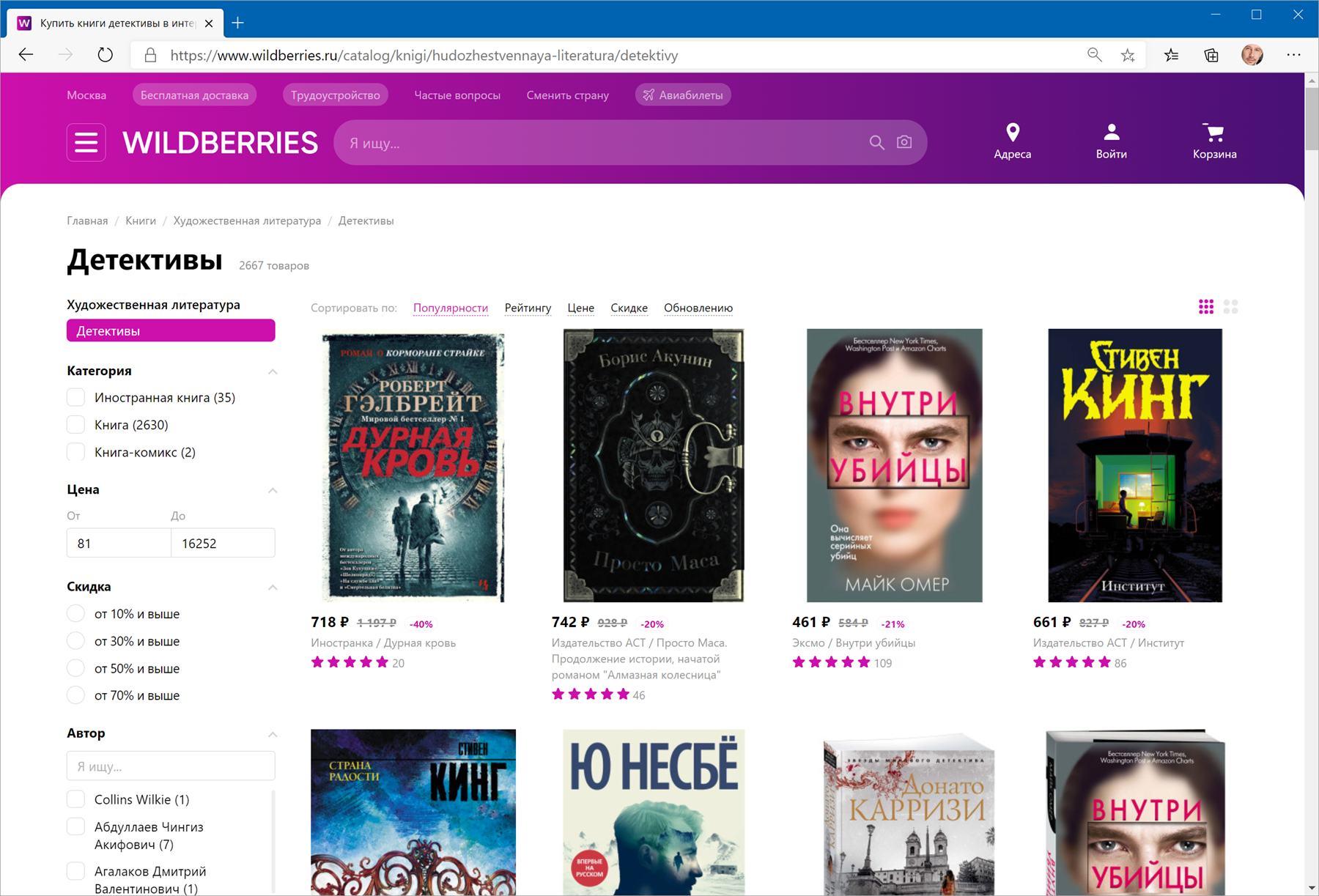
Загружаем HTML-код вместо веб-страницы
Сначала используем всё тот же подход — выбираем команду Из интернета на вкладке Данные (Data — From internet) и вводим адрес нужной нам страницы: https://www.wildberries.ru/catalog/knigi/hudozhestvennaya-literatura/detektivy После нажатия на ОК появится окно Навигатора, где мы уже не увидим никаких полезных таблиц, кроме непонятной Document: 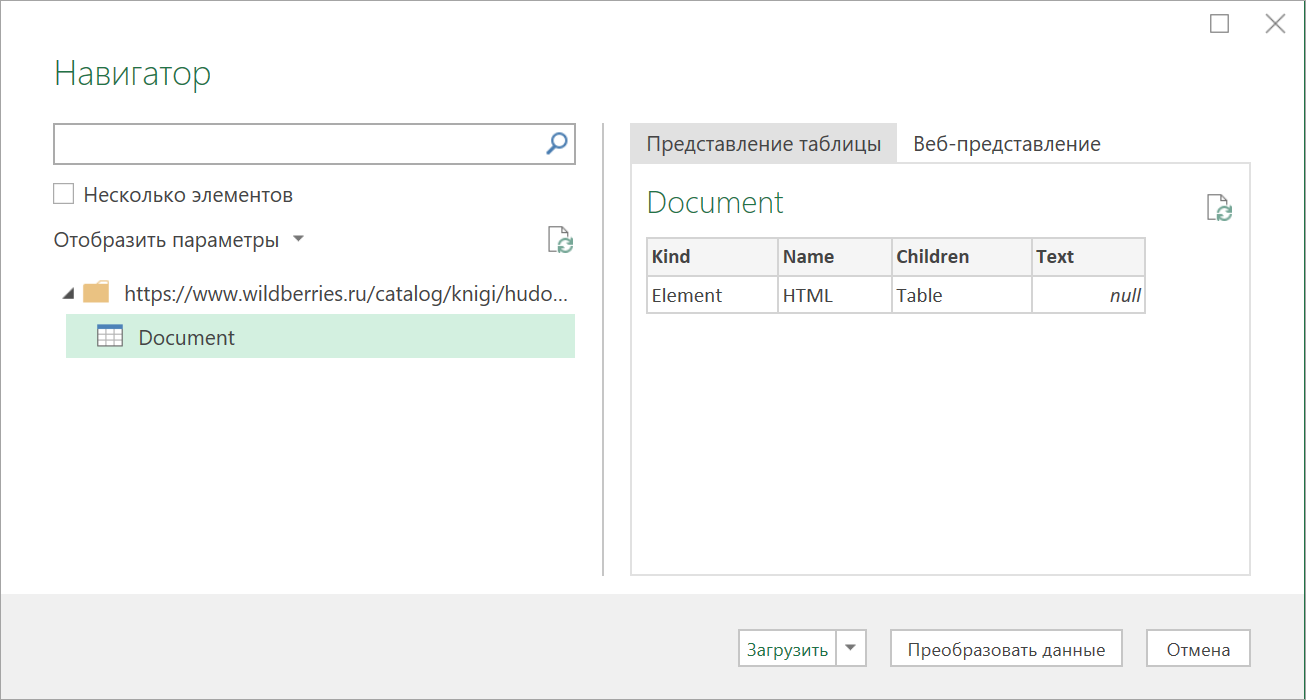
Дальше начинается самое интересное. Жмём на кнопку Преобразовать данные (Transform Data) , чтобы всё-таки загрузить содержимое таблицы Document в редактор запросов Power Query. В открывшемся окне удаляем шаг Навигация (Navigation) красным крестом: 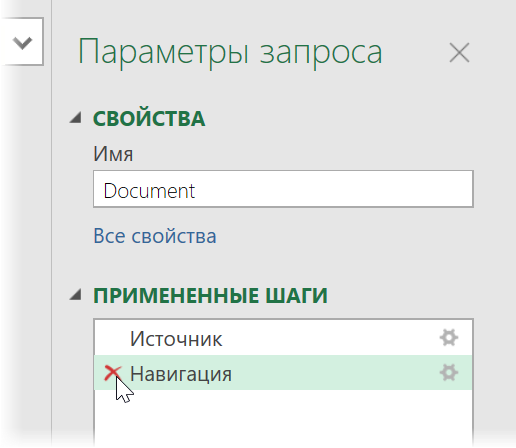
. и затем щёлкаем по значку шестерёнки справа от шага Источник (Source) , чтобы открыть его параметры: 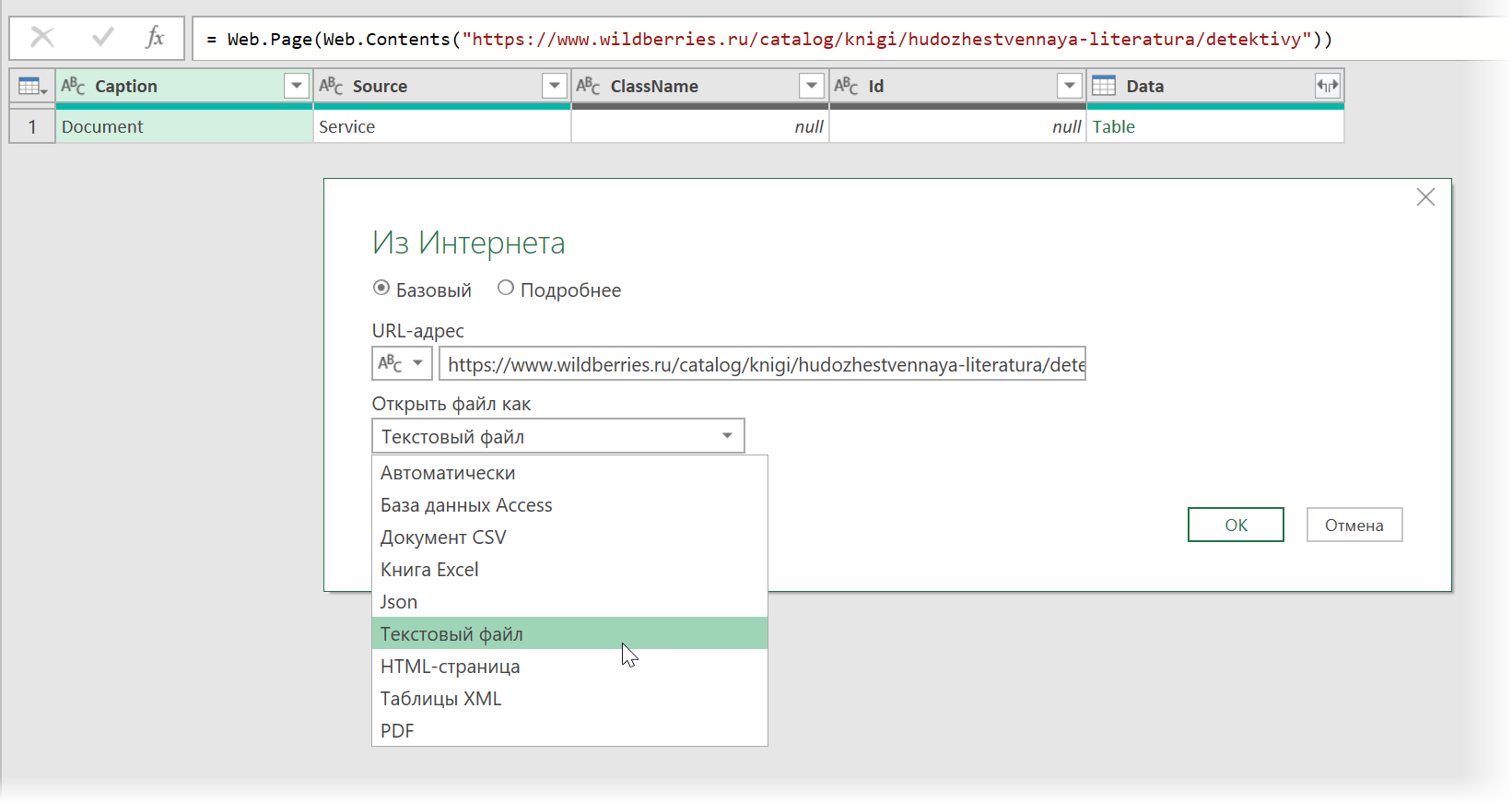
В выпадающием списке Открыть файл как (Open file as) вместо выбранной там по-умолчанию HTML-страницы выбираем Текстовый файл (Text file) . Это заставит Power Query интерпретировать загружаемые данные не как веб-страницу, а как простой текст, т.е. Power Query не будет пытаться распознавать HTML-теги и их атрибуты, ссылки, картинки, таблицы, а просто обработает исходный код страницы как текст.
После нажатия на ОК мы этот HTML-код как раз и увидим (он может быть весьма объемным — не пугайтесь): 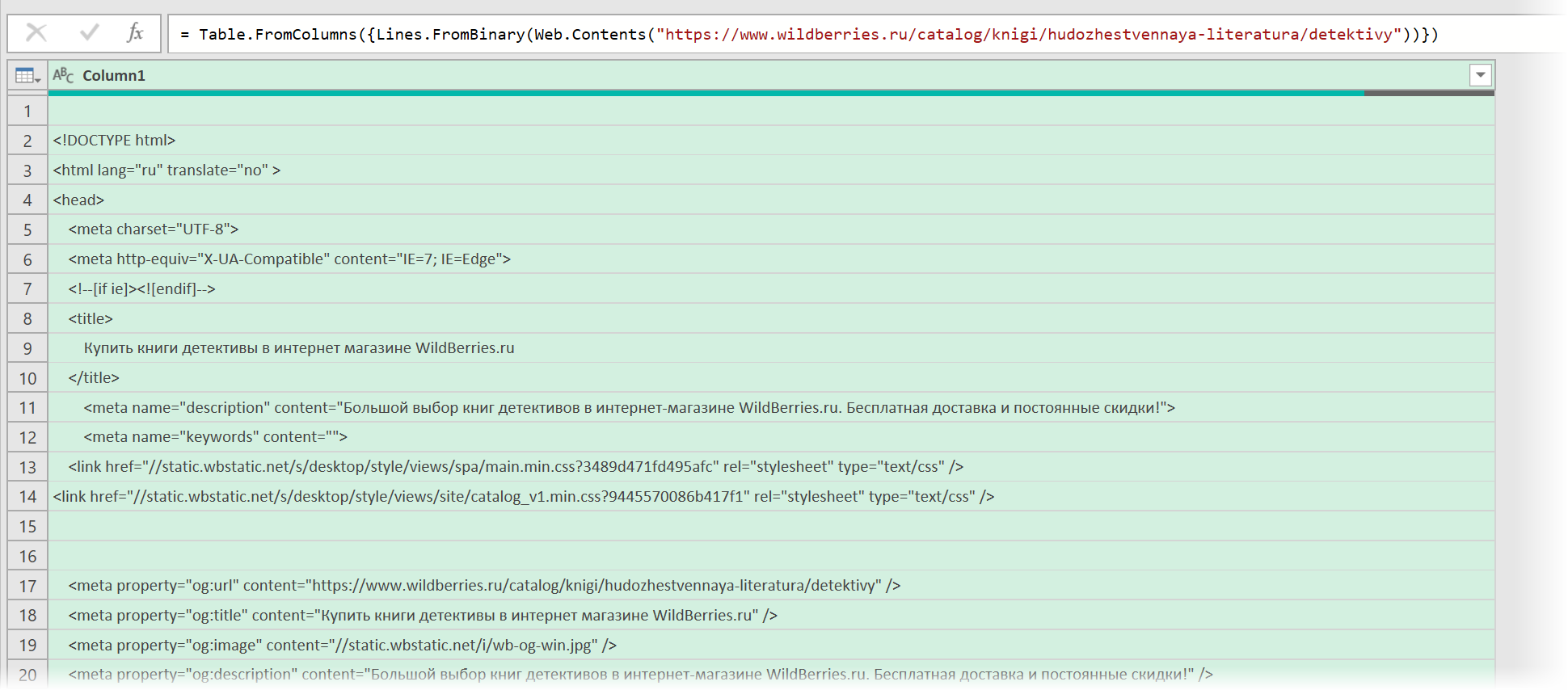
Ищем за что зацепиться
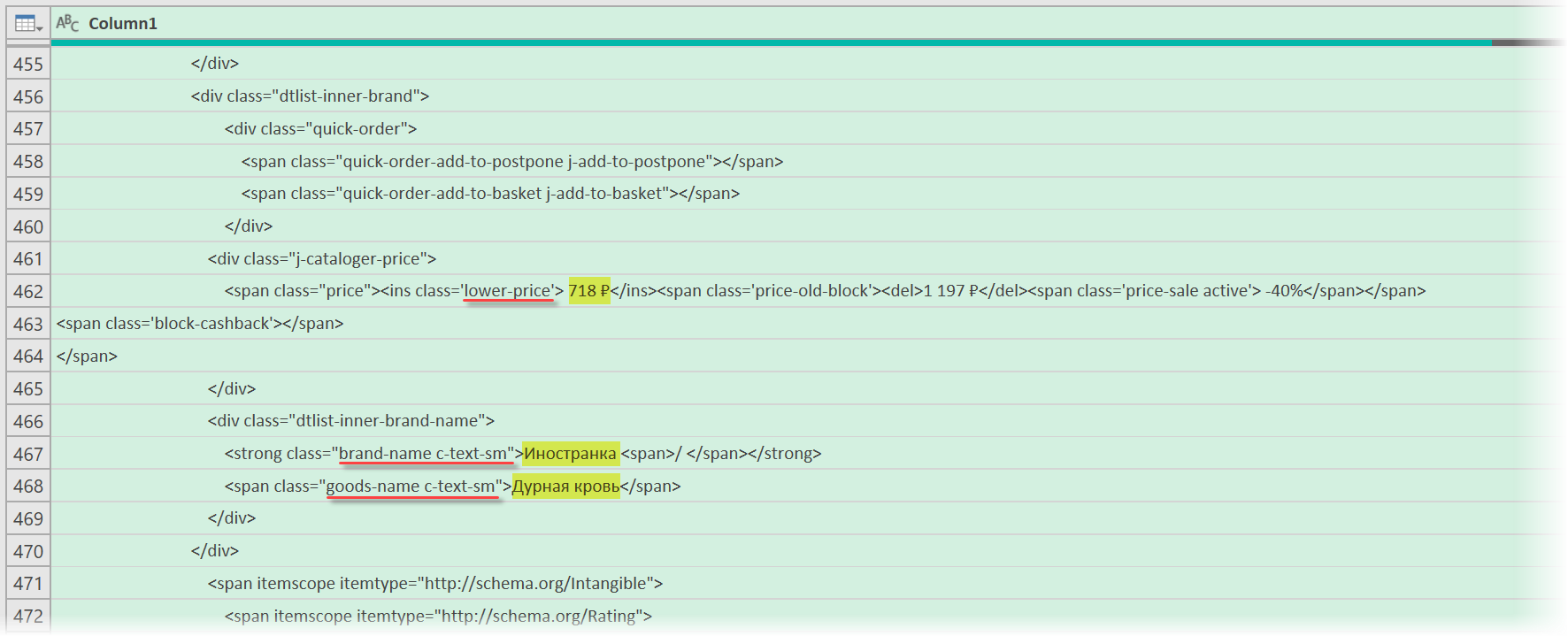
Теперь нужно понять на какие теги, атрибуты или метки в коде мы можем ориентироваться, чтобы извлечь из этой кучи текста нужные нам данные о товарах. Само-собой, тут всё зависит от конкретного сайта и веб-программиста, который его писал и вам придётся уже импровизировать. В случае с Wildberries, промотав этот код вниз до товаров, можно легко нащупать простую логику:
- Строчки с ценами всегда содержат метку lower-price
- Строчки с названием бренда — всегда с меткой brand-name c-text-sm
- Название товара можно найти по метке goods-name c-text-sm
Иногда процесс поиска можно существенно упростить, если воспользоваться инструментами отладки кода, которые сейчас есть в любом современном браузере. Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:
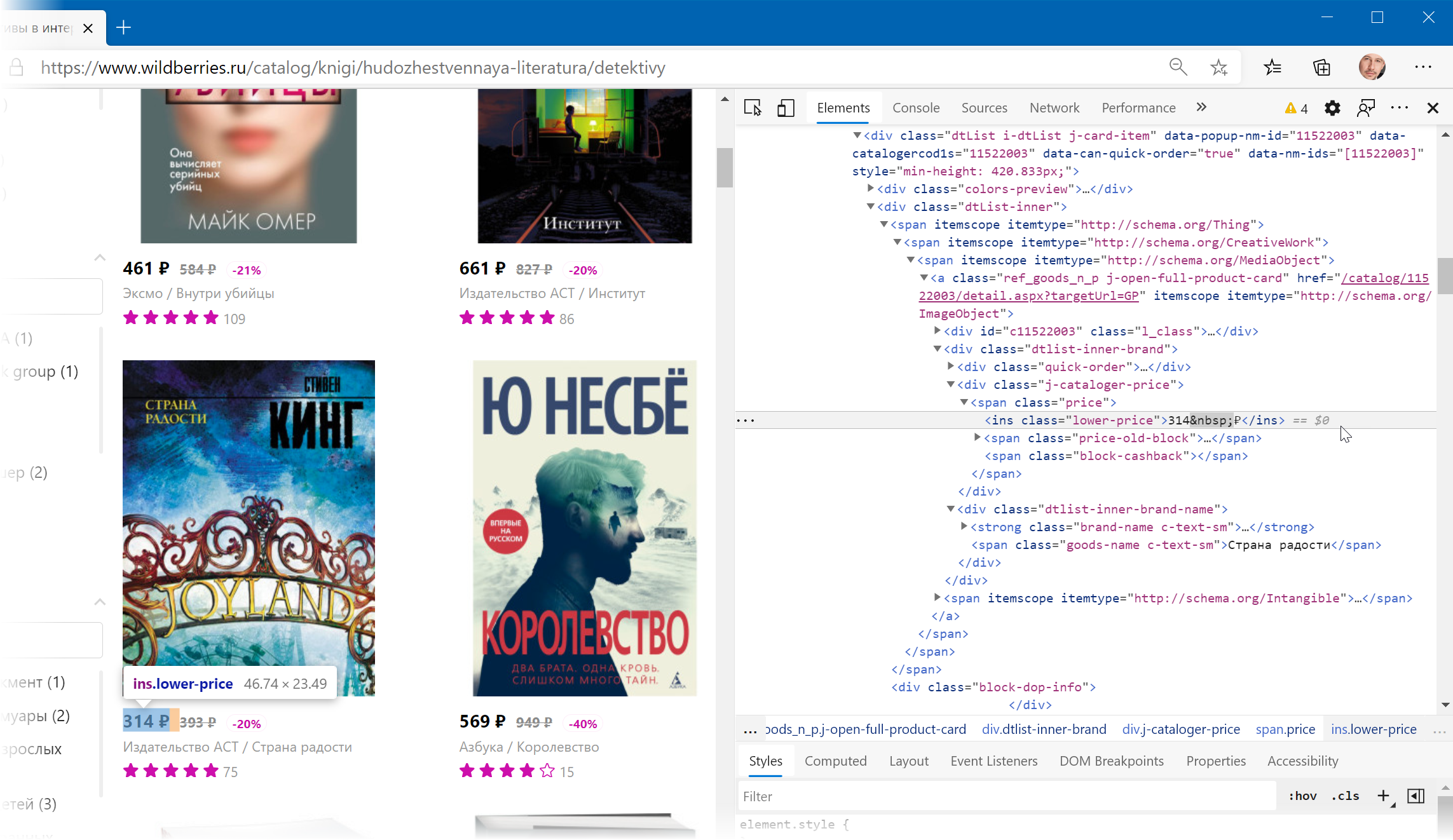
Фильтруем нужные данные
Теперь совершенно стандартным образом давайте отфильтруем в коде страницы нужные нам строки по обнаруженным меткам. Для этого выбираем в окне Power Query в фильтре [1] опцию Текстовые фильтры — Содержит (Text filters — Contains) , переключаемся в режим Подробнее (Advanced) [ 2] и вводим наши критерии:
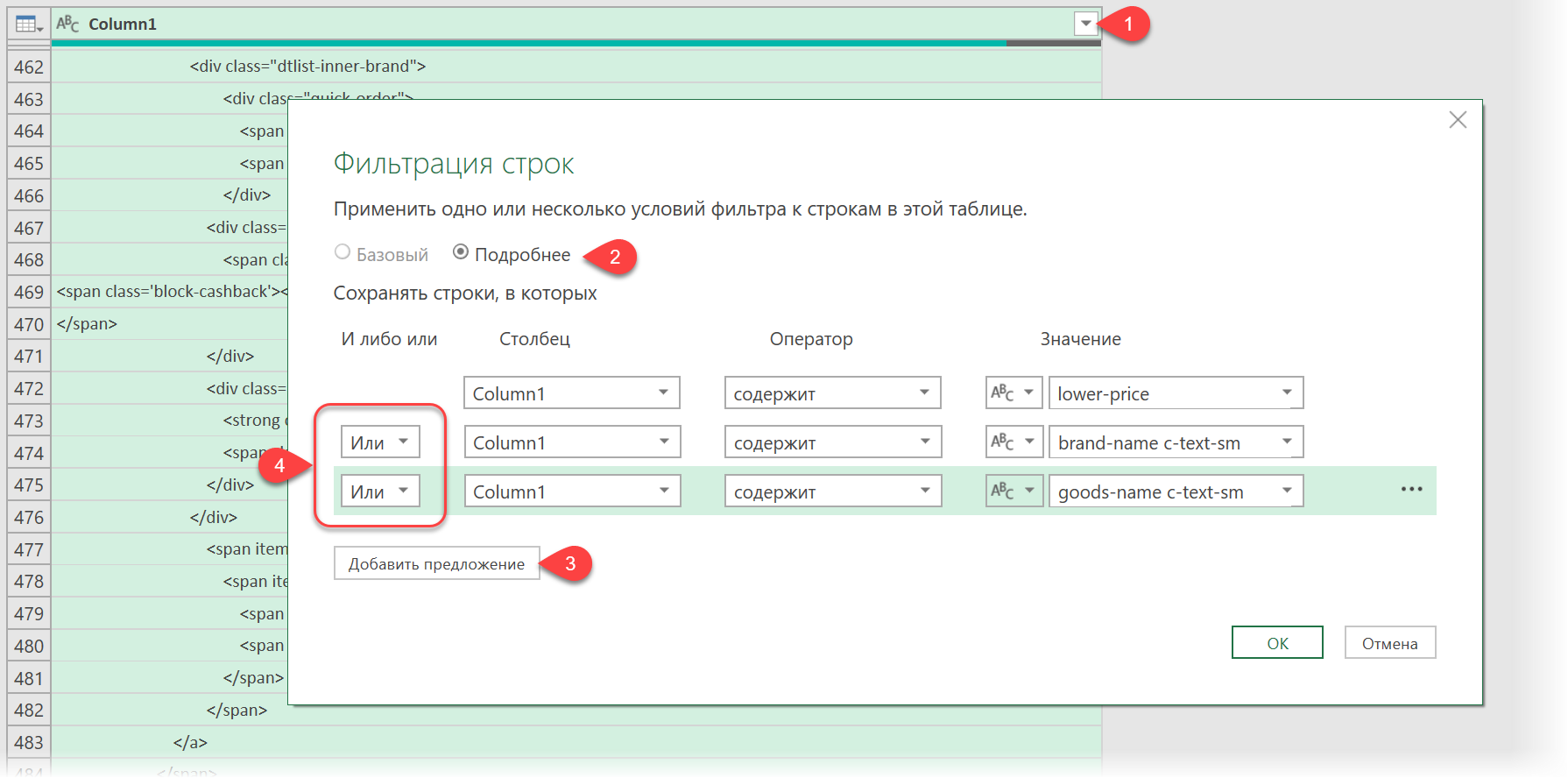
Добавление условий выполняется кнопкой со смешным названием Добавить предложение [ 3] . И не забудьте для всех условий выставить логическую связку Или (OR) вместо И (And) в выпадающих списках слева [4] — иначе фильтрация просто не сработает.
После нажатия на ОК на экране останутся только строки с нужной нам информацией:
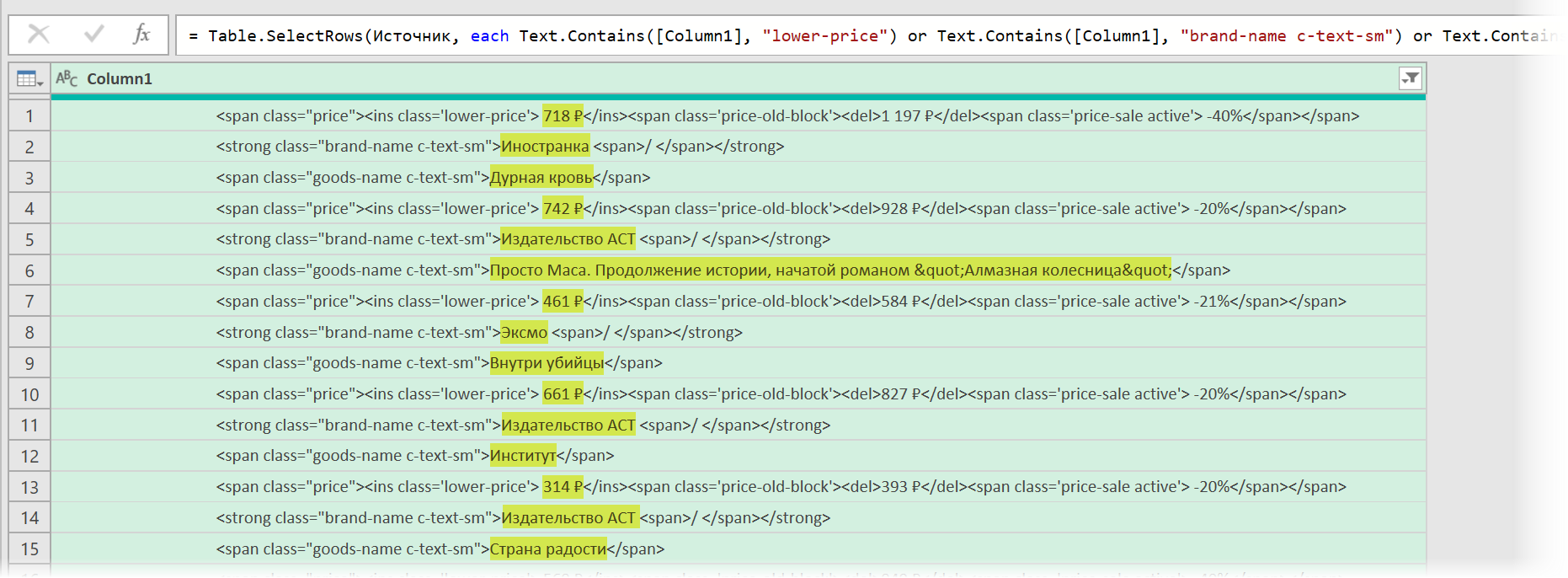
Чистим мусор
Останется почистить всё это от мусора любым подходящим и удобным лично вам способом (их много). Например, так:
- Удалить заменой на пустоту начальный тег: через команду Главная — Замена значений (Home — Replace values) .
- Разделить получившийся столбец по первому разделителю » > » слева командой Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter) и затем ещё раз разделить получившийся столбец по первому вхождению разделителя » < " слева, чтобы отделить полезные данные от тегов:
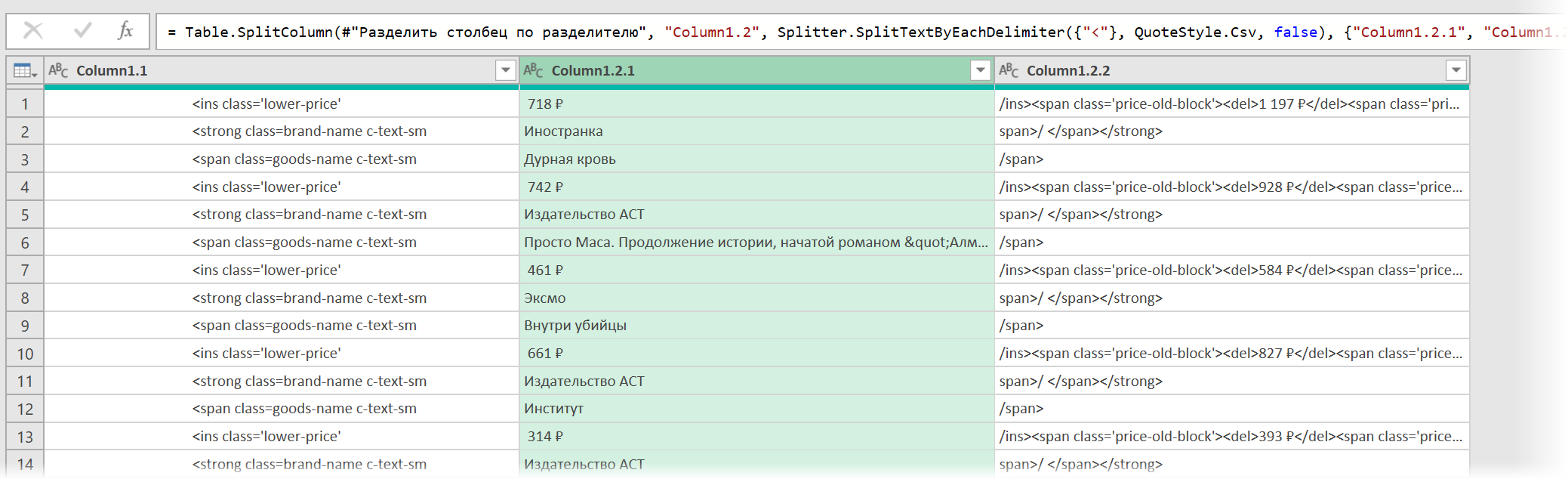
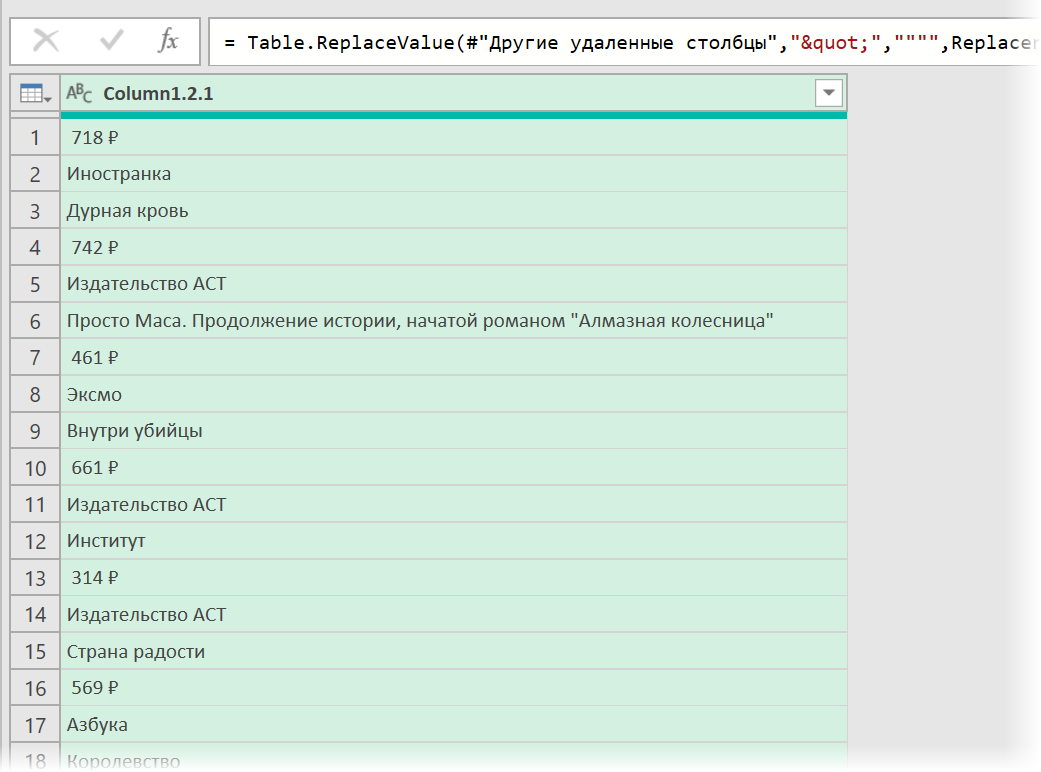
Разбираем блоки по столбцам
Если присмотреться, то информация о каждом отдельном товаре в получившемся списке сгруппирована в блоки по три ячейки. Само-собой, нам было бы гораздо удобнее работать с этой таблицей, если бы эти блоки превратились в отдельные столбцы: цена, бренд (издательство) и наименование.
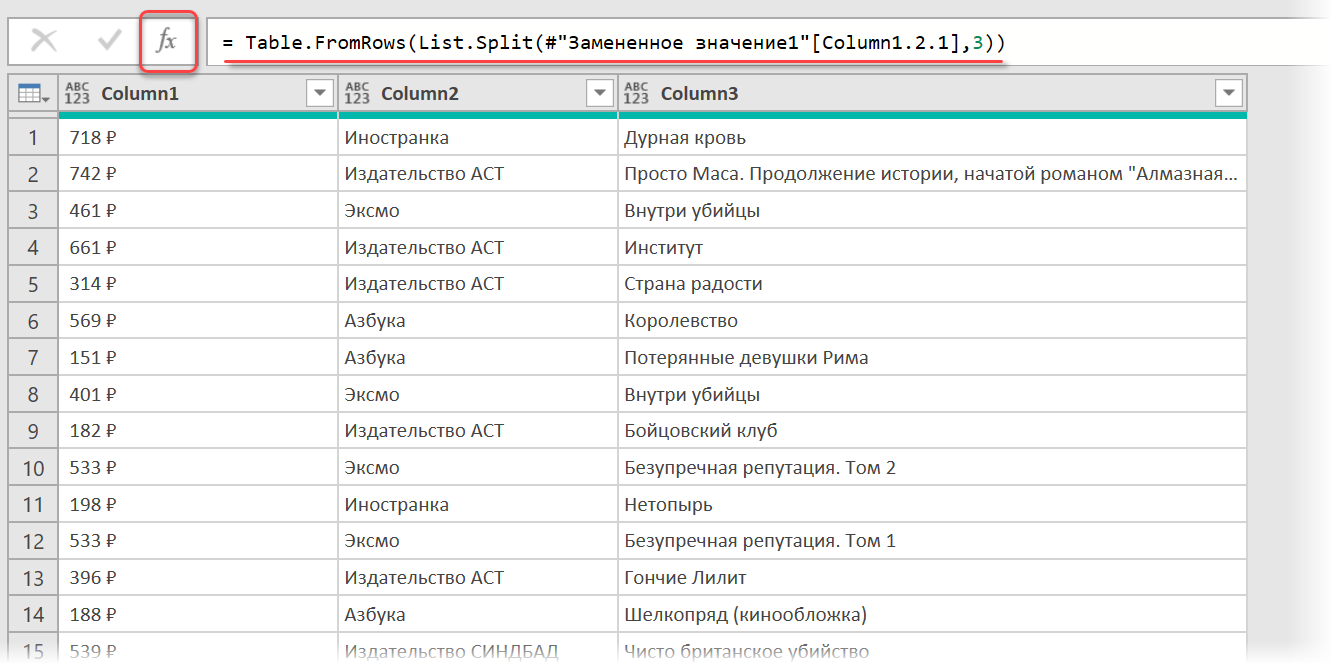
Выполнить такое преобразование можно очень легко — с помощью, буквально, одной строчки кода на встроенном в Power Query языке М. Для этого щёлкаем по кнопке fx в строке формул (если у вас её не видно, то включите её на вкладке Просмотр (View) ) и вводим следующую конструкцию:
= Table.FromRows(List.Split( #»Замененное значение1″ [Column1.2.1] , 3 ))
Здесь функция List.Split разбивает столбец с именем Column1.2.1 из нашей таблицы с предыдущего шага #»Замененное значение1″ на кусочки по 3 ячейки, а потом функция Table.FromRows конвертирует получившиеся вложенные списки обратно в таблицу — уже из трёх столбцов:
Ну, а дальше уже дело техники — настроить числовые форматы столбцов, переименовать их и разместить в нужном порядке. И выгрузить получившуюся красоту обратно на лист Excel командой Главная — Закрыть и загрузить (Home — Close & Load. )
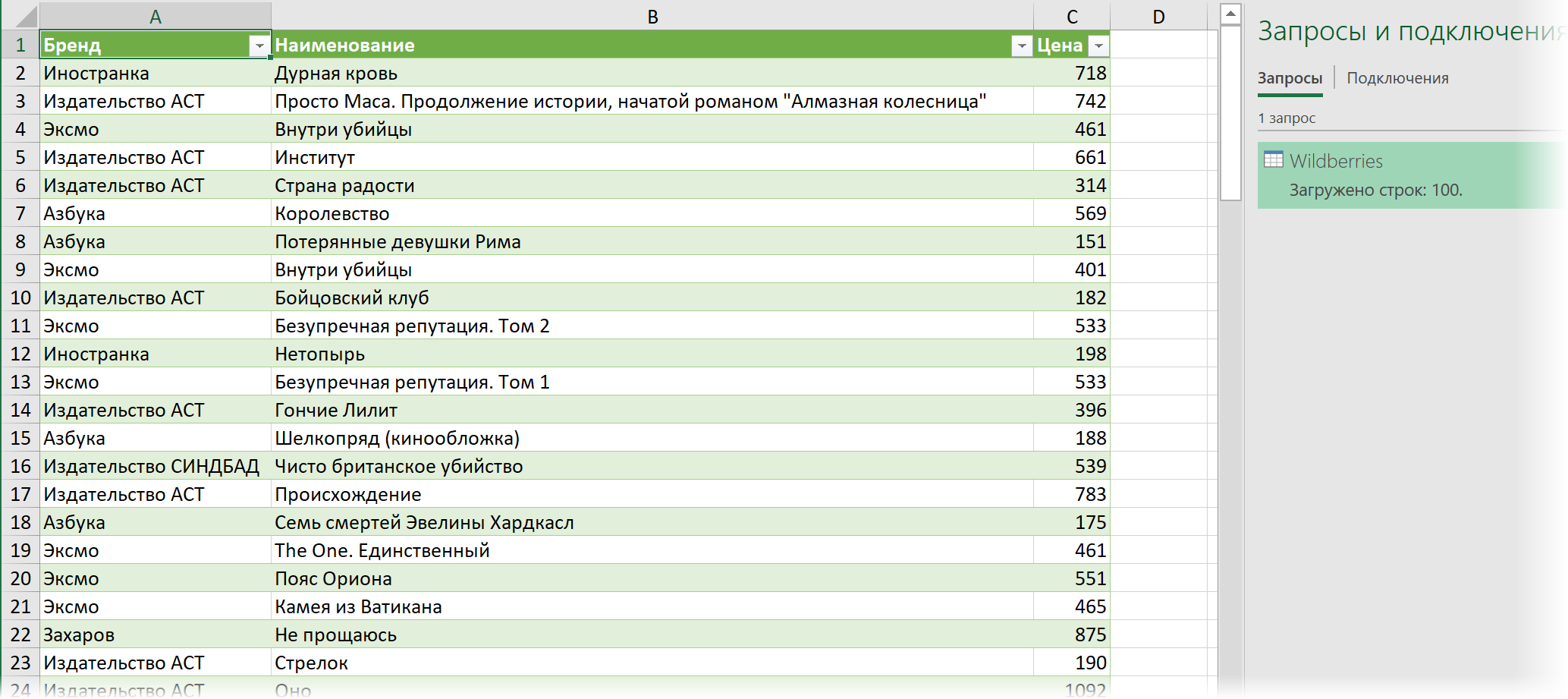
Вот и все хитрости 🙂
Ссылки по теме
- Импорт курса биткойна с сайта через Power Query
- Парсинг текста регулярными выражениями (RegExp) в Power Query
- Параметризация путей к данным в Power Query
Как сохранить данные с сайта в файл
Сообщения: 175
Благодарности: 15
| Конфигурация компьютера |  |
| Процессор: AMD Athlon II X4 635 | |
| Материнская плата: GA MA770-UD3 | |
| Память: 2X Corsair XMS2 CM2X2048-8500C5C | |
| HDD: WDC WD3200JS-00PDB0 + WDC WD2500JS-55NCB1 + 1 Тб Caviar Black WD1001FALS | |
| Видеокарта: Sapphire HD 5870 @ 900/1300MHz | |
| Звук: Integrated Realtek ALC888/1200 @ ATI SB700 — High Definition Audio | |
| Блок питания: CoolerMaster RP-500-PCAP (500W) | |
| CD/DVD: ATAPI DVD DC 16X8X5 ATA | |
| Монитор: Samsung SyncMaster 913v | |
| ОС: Windows 7 x64 Professional |
как вариант — взять ХТМЛ сайта и прогнать его через JS где на выходе создается необходимая таблица. затем импорт данных в ексель, если надо. ну, скрипт придется писать самому.
алгоритм что-то типо:
elements = element.getElementsByTagName(tagName);
for (i=0;i
ну и тут закидывать подходящие по фильтру ссылки в массив, после чего посещать каждую из них через XMLHttpRequest и обрабатывать полученные response по такому же принципу как отбирали ссылки
>
>