Файлы базы данных Oracle
Предполагается, что вы инсталлировали базу данных, согласно документа.
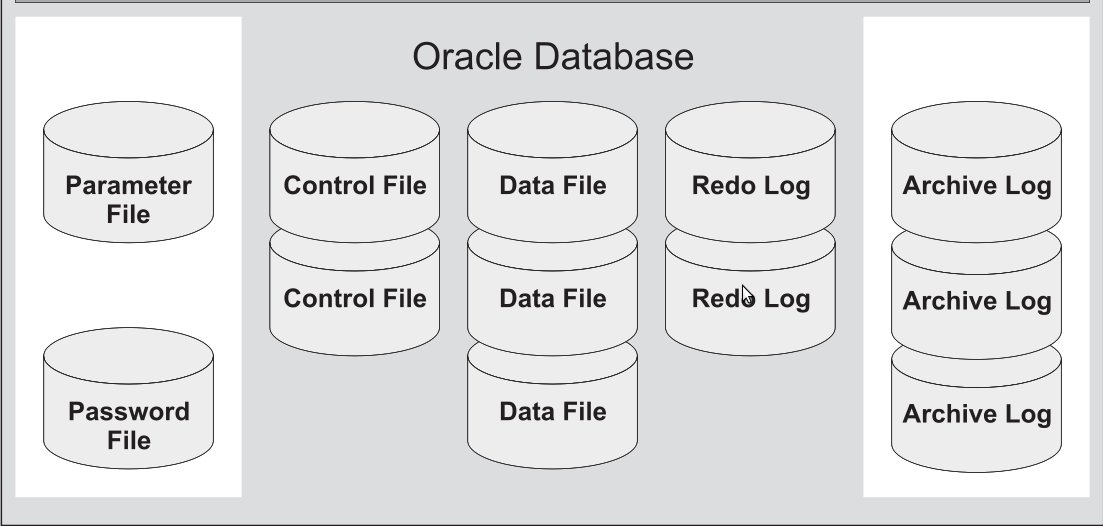
Обязательные файлы:
- Файлы данных (Data Files)
- Оперативные файлы журналов повтора (Online Redo Log Files)
- Управляющие файлы (Control Files)
- Файлы параметров pfile, spfie (Parameter Files)
Необязательные файлы:
- Архивные файлы журналов повтора (Archive Log Files) (необязательные в том смысле, что база может быть настроена для работы без данных файлов)
- Alert log и трассировочные файлы (trace file) (Alertlog — если нет необходимости в изучении данных по ошибкам, можно удалить. Трассировочные файлы по умолчанию не создаются. Чтобы создавались, нужно включать трассировку и потом не забыть отключить)
- Файлы паролей (Password File)(По умолчанию не используются. Нужно специально создавать специальными командами.)
Файлы данных (Data Files)
Все данные в базе данных Oracle сохраняются в файлах данных. Все таблицы, индексы, триггеры, последовательности, программы на PL/SQL, представления — все это находится в файлах данных. И хотя эти и другие объекты базы данных логически содержатся в табличных пространствах, в действительности они сохраняются в файлах на жестком диске компьютера.
В каждой базе данных Oracle имеется по крайней мере один файл данных (но обычно их бывает больше). Если вы создаете в Oracle таблицу и заполняете ее строками, Oracle помещает эту таблицу и строки в файл данных. Каждый файл данных может быть связан только с одной базой данных.
У каждого файла данных имеется специальный формат, внутренний для программного обеспечения Oracle. Важно отдавать себе отчет в том, что файл данных состоит из заголовка и совокупности блоков. Заголовок файла данных Oracle содержит несколько структур, в том числе и идентификатор базы данных, номер и имя файла, тип файла, SCN создания и состояния файла.
Данные в файлы вносятся исключительно средствами Oracle.
Следующий запрос, покажет, где находятся файлы данных.
SQL> set linesize 200; SQL> set pagesize 0; SQL> col name format a40; SQL> select file#, name, status from v$datafile; 1 /u02/oradata/ora112/system01.dbf SYSTEM 2 /u02/oradata/ora112/sysaux01.dbf ONLINE 3 /u02/oradata/ora112/undotbs01.dbf ONLINE 4 /u02/oradata/ora112/users01.dbf ONLINE 5 /u02/oradata/ora112/my_indexes01.dbf ONLINE 6 /u02/oradata/ora112/my_data01.dbf ONLINE Оперативные файлы журналов повтора (Online Redo Log Files)
Оперативные файлы журналов повтора — предназначены для записи всех изменений, выполненных над данными базы данных Oracle. Используется для хранения на диске информации для повторного выполнения операций.
Для компьютера выполнить задачи повторно — означает выполнить ее точно так, как она выполнялась в предыдущий раз. Поэтому назначение оперативного файла журнала повтора заключается в сохранении информации об изменениях в базе данных таким, образом, чтобы позже их можно было повторить.
Каждая база данных должна иметь не менее двух оперативных файлов журналов повтора. Текущий файл постепенно заполняется, после его заполнения (или переключения некоторыми командами), база данных приступает к записи в следующий файл. Эта операция называется переключением журналов.
Поскольку файлы повтора необходимы для выполнения восстановления базы данных и являются критичными, их объединяют в группы. Запись происходит одновременно в файлы одной группы.
SQL> set linesize 200; SQL> set pagesize 0; SQL> col member format a50; SQL> select group#, member from v$logfile order by group#; 1 /u02/oradata/ora112/redo01.log 1 /u01/app/oracle/fast_recovery_area/redo01.log 2 /u01/app/oracle/fast_recovery_area/redo02.log 2 /u02/oradata/ora112/redo02.log 3 /u01/app/oracle/fast_recovery_area/redo03.log 3 /u02/oradata/ora112/redo03.log Управляющие файлы (Control Files)
Поскольку база данных Oracle является физическим набором связанных файлов данных, то для их синхронизации и контроля требуется особые методы. Для этих целей используются управляющие файлы.
База данных Oracle может иметь один или несколько управляющих файлов. Если имеется несколько управляющих файлов, все они должны быть абсолютно идентичными. При каждом запуске базы данных Oracle читает информацию управляющего файла, а при каждом изменении размещения или добавления новых файлов данных и журналов базы данных обновляет управляющий файл.
SQL> set linesize 200; SQL> set pagesize 0; SQL> col name format a100; SQL> select name from v$controlfile; /u02/oradata/ora112/control01.ctl /u02/oradata/ora112/control03.ctl /u01/app/oracle/fast_recovery_area/ora112/control02.ctl Файлы параметров pfile, spfie (Parameter Files)
Файлы параметров используются для конфигурирования действий Oracle предже всего при старте. Для того, чтобы запустить экземпляр базы данных, Oracle должен прочесть файл параметров и определить, какие параметры инициализации установлены для этого экземпляра. В файле параметров содержатся многочисленные параметры и их установленные значения. Oracle считывает файл параметров при запуске базы данных. Можно создать несколько файлов параметров, каждый будет соответствовать различным конфигурациям экземпляра.
- spfile — бинарный файл, который используется сервером Oracle при старте.
- pfile — текстовый файл с параметрами, будет использоваться при старте, если не будет найден spfile.
$ ls /u01/app/oracle/product/11.2/dbs/*.ora /u01/app/oracle/product/11.2/dbs/init.ora /u01/app/oracle/product/11.2/dbs/spfileora112.ora При старте, Oracle считает файл spfileora112.ora. (файл серверных параметров). Преимущество spfile заключается в том, что при работе с базой данных, любые изменения в базе касающиеся изменения параметра системы, автоматически записываются в данный файл.
Если используется pfile, для сохранения изменений, необходимо либо “руками вносить эти изменения” в текстовый файл, либо в консоли выполнять команды для создания данных файлов Ораклом.
// создание pfile из памяти (в 11 версии Oracle) SQL> create pfile from memory; // создать pfile из spfile SQL> Create pfile from spfile; Как я могу узнать, что моя база данных использует PFILE или SPFILE?
Выполните следующий запрос, чтобы увидеть какой файл параметров был использован:
SELECT DECODE(value, NULL, 'PFILE', 'SPFILE') "Init File Type" FROM sys.v_$parameter WHERE name = 'spfile'; Init F ------ SPFILE SQL> show parameter spfile; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ spfile string /u01/app/oracle/product/11.2/d bs/spfileora112.ora Архивные файлы журналов повтора (Archive Log Files)
Как только оперативный файл журнала повтора (Redolog) оказывается заполнен, программное обеспечение сервера Oracle начинает запись в следующий файл. Эта операция повторяется, как следствие информация в оперативных файлах журнала (Redolog) многократно перезаписывается.
Если необходимо сохранить историю изменений, нужно, чтобы после переключения журналов сохранялась их копия. Для этого достаточно перевести работу базы данных в режим работы ARCHIVELOG.
Архивные файлы журналов повтора жизненно важны при восстановлении. Если часть базы данных потеряна или повреждена, то для устранения повреждений обычно требуется несколько архивных журналов или туева хуча этих журналов. Файлы журналов повтора должны применяться к базе данных последовательно. Если один из архивных файлов журналов повтора пропущен, то остальные архивные файлы журналов не могут использоваться. Храните все свои архивные файлы журналов повтора с момента выполнения последней резервной копии. Файлы журналов постепенно накапливаются и разрастаются. Иногда необходимо их удалять. Все операции с данными файлами по применению их к базе выполняются исключительно средствами базы данных. А копировать и переносить их при желании можно как угодно. Бездумно удалять их руками не рекомендуется.
SQL> set linesize 200; SQL> set pagesize 0; SQL> col name format a100; SQL> select name from v$archived_log; . /u01/app/oracle/fast_recovery_area/ORA112/archivelog/2011_11_22/o1_mf_1_11_7dq050f1_.arc /u01/app/oracle/fast_recovery_area/ORA112/archivelog/2011_11_23/o1_mf_1_12_7dsykrjd_.arc /u01/app/oracle/fast_recovery_area/ORA112/archivelog/2011_11_24/o1_mf_1_13_7dw3fy96_.arc /u01/app/oracle/fast_recovery_area/ORA112/archivelog/2011_11_24/o1_mf_1_14_7dw3ys4f_.arc /u01/app/oracle/fast_recovery_area/ORA112/archivelog/2011_11_26/o1_mf_1_15_7f04bqyq_.arc . Alert log и трассировочные файлы (trace file)
При работе базы данных события и ошибки регистрируются в текстовых файлах на сервере базы данных. Файл журнала предупреждений (alert log) нужен администратору базы данных для отслеживания важнейших действий с базой данных — наподобие открытия и закрытия базы данных, установления параметров загрузки базы данных и переключения оперативных журналов повтора. Также в эти файлы записываются многие ошибки базы данных для последующего расследования их причин. Любые структурные изменения базы данных также регистрируются в файле журнала предупреждений.
// в 11 версии базы данных по умолчанию: $ ls /u01/app/oracle/diag/rdbms/rdb115/RDB115/trace alert_$.log // в 11 версии появилась XML версия. По умолчанию: $ ls /u01/app/oracle/diag/rdbms/ora112/ora112/alertlog.xml Когда возникает ошибка базы данных, может генерироваться файл трассировки (trace file). Они содержит подробную информацию о возникновении ошибки.
// в 11 версии базы данных по умолчанию трассировочные файлы хранятся /u01/app/oracle/diag/rdbms/ora112/ora112/trace // Следующая команда выведет информацию по расположению трассировочных файлов SQL> show parameter dump_dest Файлы паролей (Password File)
Необязательный файл, используется для защиты информации о подключениях привилегированных пользователей. Если отсутствует, то вы можете выполнять администрирование своей базы данных, только локально. Кроме того, с его помощью контролируется количество привилегированных подключений для управления в одно и то же время.
$ ls /u01/app/oracle/product/11.2/dbs/orapw* /u01/app/oracle/product/11.2/dbs/orapwora112 Tags: Oracle Database, Файлы базы данных Oracle,
 |
 |
 |
Oracle DBA
Собираем также материалы по: SQL & PL/SQL
Лучше потратить какое-то количество времени, чтобы записать успешный опыт, чем потом повторно воспроизводить его по памяти.
Все материалы обновляются по мере нахождения лучших практик и апгрейда знаний. Если будут желающие добавлять свои знания или исправлять ошибки и неточности, пишите в телеграм чате. Если будет учавствовать больше людей, качество материалов будет улучшаться и обновляться быстрее. Ссылки на ваши профили в соц. сетях будут добавлены в статьях, в которых вы учавствуете.
Удаление Oracle Database под Windows
Beginning with 11.2, the Oracle Universal Installer will no longer be used to remove Oracle software from an environment. A new Deinstall tool is shipped with the Oracle Products and is also available for download on OTN
Это из нотки “How to Manually Remove Oracle Server Software on Microsoft Windows Platforms (Doc ID 1069034.1)”
Итак, имеем Oracle Database 11g, которую хотим “снести”.
Существуют 2 + 1 вариант. Рассмотрим их подробнее.
Вариант 1 – Deinstallation Tool
Как сказано в документе, используем Deinstall tool, для этого обращаемся к документации.
“Database Installation Guide for Microsoft Windows”, переходим к разделу “Removing Oracle Database Software”.
Все достаточно описано, выполняем по шагам.
Вариант 2 – ручное удаление (согласно ноте)
В документе описан “гуманный способ”, удаления. Используются консоли Database Configuration Assistant (DBCA) и Net Configuration Assistant (NetCA) для удаления продуктов. Далее ручная зачистка реестра, сервисов, переменных окружения и прочее.
Также описано удаление для кластерной модели.
Вариант 3 – ручное удаление
В результате был выбран этот вариант, т.к. удалялся весь софт Oracle с машины то консоли не использовались.
- Останавливаем все сервисы Oracle
- Удаляем файлы вместе с папкой из ORACLE_HOME
- Удаляем файлы вместе с папкой из C:\Program Files\Oracle
- Удаляем ветку в реестре HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE
- Удаляем в ветке реестра HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services все сервисы, имеющие в наименовании или ссылке слово Oracle
- Корректируем значения переменных окружения CLASSPATH, ORACLE_HOME, PATH, PERL5LIB.
- Удаляем ссылки в меню, относящиеся к продуктам Oracle
- Перегружаем машину, смотрим, чтобы все что мы делали – действительно привело к нужным нам результатам.
Остальное – не критично, т.к. нам ведь для переустановки.
Если хочется просто зачистить машину, чтобы следов не осталось, то тогда надо использовать документ (ноту), и по шагам выполнять указанные там действия.
2 thoughts on “ Удаление Oracle Database под Windows ”
Saimon
6. Корректируем значения переменных окружения CLASSPATH, ORACLE_HOME, PATH, PERL5LIB.
Можно этот пункт по подробней, где искать эти переменные, как корректировать?
Заранее спасибо.
Ну, как сказать. Есть 2 способа.
1 – вызываете командную строку (cmd.exe, или в far manager). Ну а там команды set, path и остальное.
2 – используете изменение настроек среды через оконный интерфейс
Правой кнопкой мыши на системной иконке открываете окно System Properties. Закладка Advanced. Внизу кнопка System Variables.
Далее в окне System Variables выбираете в нижнем блоке свою переменную, нажимаете кнопочку Edit п2 описан для windows XP ��
Служба системы отслеживания измененных данных для Oracle компании Attunity
Служба CDC для Oracle — это служба Windows, которая просматривает журналы транзакций Oracle и записывает изменения, касающиеся отслеживаемых таблиц Oracle, в таблицы изменений SQL Server. Таблицы изменений SQL, в которых хранятся изменения, полученные из Oracle, являются одинаковыми типами таблиц изменений, используемых в собственной функции отслеживания измененных данных SQL Server. Это упрощает использование этих изменений, как и использование изменений, внесенных в базы данных SQL Server.
Установка
Microsoft Change Data Capture for Oracle by Attunity поддерживает SQL Server 2019 и ниже.
Скачайте конструктор и службу системы отслеживания измененных данных Microsoft для Oracle от Attunity для соответствующей версии SQL Server по одной из следующих ссылок:
- Пакет дополнительных компонентов для конструктора и службы CDC Oracle для Microsoft SQL Server 2016 Integration Services от Attunity
- Пакет дополнительных компонентов для конструктора и службы CDC Oracle для Microsoft SQL Server 2017 Integration Services от Attunity
- Пакет дополнительных компонентов для служб Microsoft SQL Server 2019 Integration Services
Служба CDC для Oracle может быть установлена на любом поддерживаемом компьютере Windows с доступом к исходной базе данных Oracle и целевому экземпляру SQL Server, где находится целевая база данных CDC. Службе CDC не требуется локальная установка базы данных Oracle или базы данных SQL Server только их поддерживаемых клиентов. Сведения о месте установки необходимых компонентов базы данных см. в подразделе Предварительные требования базы данных в этом разделе.
Установка службы CDC SQL Server для Oracle помещает пользовательский интерфейс конфигурации службы и программу службы в выбранное расположение. Служба CDC Service для Oracle настраивается отдельно с помощью консоли конфигурации службы Oracle CDC. Дополнительные сведения о настройке службы Oracle CDC Service см. в разделе Справка F1 по службе системы отслеживания информации об изменениях данных для Oracle компании Attunity.
Служба CDC для Oracle может быть установлена на любом поддерживаемом компьютере Windows, где установлен собственный клиент SQL Server; Он не должен быть установлен на том же компьютере, где установлен целевой СЕРВЕР SQL Server.
Поддерживаемые среды Windows
Служба системы отслеживания измененных данных для Oracle от Attunity может работать в следующих средах Windows:
- Windows 8 и 8.1
- Windows 10
- Windows Server 2012 и 2012 R2
- Windows Server 2016
- Windows 2019
Предварительные требования базы данных
Для работы со службой CDC Service для Oracle следует установить клиент Oracle, совместимый с версией базы данных Oracle. Это обязательный компонент, который нужно получить у Oracle и установить до установки службы Oracle CDC Service. Кроме того, необходимо установить клиент ODBC для SQL Server, используя процесс установки SQL Server.
Служба CDC для Oracle поддерживает следующие версии:
Исходная база данных Oracle
- База данных Oracle 10g, выпуск 2
- База данных Oracle 11g, выпуск 1 и 2
- База данных Oracle 12c в классической установке (многотенантная установка не поддерживается)
- База данных Oracle 18c в классической установке (многотенантная установка не поддерживается), только для SQL Server 2019
- База данных Oracle 19c в классической установке. (Многотенантная установка не поддерживается), только для SQL Server 2019
Целевая база данных SQL Server
Список функций, поддерживаемых выпусками SQL Server, см. в разделе «Функции, поддерживаемые выпусками SQL Server».
Запуск программы установки
Чтобы установить службу CDC для Oracle, откройте мастер установки для используемой платформы Windows (32/64-разрядная версия) и следуйте инструкциям на экране.
Удаление службы системы отслеживания измененных данных для Oracle от Attunity
Служба CDC Service для Oracle удаляется с помощью пункта панели управления «Программы и компоненты».
Удаление службы CDC не удаляет созданные базы данных SQL Server. Для полного удаления средства необходимо удалить базу данных MSXDBCDC и определенные базы данных CDC, созданные в целевом экземпляре SQL Server, с которыми вы работали.
Если программное обеспечение службы CDC Service удаляется с одного компьютера и устанавливается на другой, нужно задать только следующие данные:
- Организация сервиса
- Строка подключения и учетные данные SQL Server
- Главный пароль
Все остальные определения хранятся в SQL Server и доступны из предыдущей установки на другом компьютере.
В этой документации
- Архитектура службы системы отслеживания измененных данных для Oracle компании Attunity
- Служба CDC Oracle
- Справка F1 по службе системы отслеживания информации об изменениях данных для Oracle компании Attunity
- Руководство по службе системы отслеживания измененных данных для Oracle компании Attunity
Утилиты экспорта и импорта данных в базе данных Oracle — Data Pump
В состав технологии Data Pump входят утилиты: Data Pump Export (expdp) и Data Pump Import (impdp).
Data Pump Export – выгружает данные в файлы операционной системы, называемые файлами дампа (dumps files), в специальном формате, который может понимать только утилита Data Pump Import.
Получить справку по утилитам можно выполнив команды:
expdp help=y impdp help=y Если необходимо выполнить экспорт схемы или ее объектов, воспользуйтесь правами данной схемы. Использовать полномочия учетных записей sys и system не рекомендуется (по той причине, что для импорта могут потребоваться права sys и system соотвестственно).
Файл параметров экспорта схемы.
$ vi exoprt_schema_name.config JOB_NAME=impdp_schema_name DUMPFILE=dpdumps:schema_name.dmp LOGFILE=dplogs:expdp_schema_name_YYYYMMDD.log JOB_NAME — имя задания, чтобы при необходимости задание можно было бы идентифицировать по имени.
DUMPFILE — каталог для дампа LOGFILE — каталог для логов
dplogs — ссылка в базе данных на каталог в котором должны будут сохраниться логи результата выполнения экспорта схемы базы данных.
dpdumps — ссылка в базе данных на каталог в котором должны будут сохраниться файл дампа базы данных.
dplogs и dpdumps должны ссылаться на реальные каталоги операционной системы с достаточным набором прав на запись.
# mkdir -p /u03/oradata/datapump/dumps # mkdir -p /u03/oradata/datapump/logs # chown -R oracle11:dba /u03/oradata/datapump/dumps # chown -R oracle11:dba /u03/oradata/datapump/logs Создание ссылки в базе данных на катлоги операционной системы
$ sqlplus / as sysdba Посмотреть уже имеющиеся каталоги для datapump:
SQL> set linesize 200; SQL> set pagesize 0; SQL> col directory_name format a30; SQL> col directory_path format a60; SQL> select directory_name, directory_path from dba_directories; Мне не нравится каталог по умолчанию. Предпочитаю его удалить
DROP DIRECTORY DATA_PUMP_DIR; CREATE DIRECTORY dpdumps as '/u03/oradata/datapump/dumps'; CREATE DIRECTORY dplogs as '/u03/oradata/datapump/logs'; Делегирую права на запись в данную директорию пользователю scott
GRANT READ, WRITE ON DIRECTORY dpdumps TO scott; GRANT READ, WRITE ON DIRECTORY dplogs TO scott; Если необходимо предоставить возможность экспорта данных в указанные каталоги для любых схем:
GRANT READ, WRITE ON DIRECTORY dpdumps TO PUBLIC; GRANT READ, WRITE ON DIRECTORY dplogs TO PUBLIC; Экспорт схемы с использованием файла параметров:
$ nohup expdp scott/tiger parfile=exoprt_schema_name.config & В некоторых случаях необходимо явно указать SID базы данных.
$ nohup expdp scott/tiger@SID parfile=exoprt_schema_name.config & Экспорт можно выполнить одной командой без использования файла параметров:
$ nohup expdp scott/tiger job_name=scott_export_job_01 dumpfile=dpdumps:scott_YYYYMMDD.dmp logfile=dplogs:scott_YYYYMMDD & Технология Data Pump состоит из трех главных компонентов:
- Пакет DBMS_DATAPUMP – это главный механизм для осуществления загрузки и выгрузки метаданных словаря данных. В пакете DBMS_DATAPUMP содержится основополагающие элементы технологии Data Pump в виде процедур, которые в действиельности приводят в действие задания по загрузке и выгрузке данных. Содержимое этого пакета отвечает за работу как утилиты Data Pump export, так и утилиты Data Pump Import.
- Пакет DBMS_METADATA – для извлечения и изменения метаданных Oracle.
- Клиенты с интерфейсом командной строки – impdbp и expdp
Режимы утилиты Data Pump Export
Data Pump Export поддерживает несколько режимов для выполнения заданий.
- Режим экспорта всей базы данных. Позволяет выполнять экспорт всей базы данных за один сеанс экспорта с помощью параметра FULL. Для использования этого режима, необходимы привилегии EXPORT_FULL_DATABASE.
- Режим схем. Позволяет выполнять экспорт данных и/или объектов только конкретного пользователя с помощью параметра SCHEMAS.
- Режим табличных пространств. Позволяет выполнять экспорт всех таблиц, которые содержатся в одном или нескольких табливчных пространствах, с помощью параметра TABLESPACES или только метаданных тех объектов, которые содержатся в одном или нескольких табличных пространствах, с помощью параметра TRANSPORT_TABLESPACES. Выполнять экспорт табличных пространств между базами данных можно, чначала выполнив экспорт метаданных, затем скопировав файлы табличного пространства на целевой сервер, а потом импортировав метаданные в целевую базу данных.
- Режим таблиц. Позволяет выполнять экспорт только одной или нескольких конкретных таблиц с помощью параметра TABLES.
По умолчанию для выполнения заданий Data Pump Export и Data Pump Import используется режим схем.
Параметры фильтрации экспортируемых данных.
Параметр CONTENT — позволяет выполнять фильтрацию тех данных, которые должны помещаться в файл дампа при экспорте. Он может принимать следующие значения:
- ALL – указывает, что требуется экспортировать как данные таблиц, так и определения этих таблиц и других объектов (метаданных);
- DATA_ONLY – указывает, что требуется экспортировать только строки таблиц.
- METADATA_ONLY – указывает, что требуется экспортировать только метаданные.
Пример:
$ nohup expdp scott/tiger dumpfile=dpdumps:mydump01.dmp logfile=dplogs:mydump01.log CONTENT=DATA_ONLY & Парамтеры ECLUDE и INCLUDE
Параметры EXCLUDE и INCLUDE – это два взаимоисключающих параметра, которые можно применять для выполнения так называемой фильтрации метаданных (metadata filtering). Фильтрация метаданных позволяет выборочно исплючать или наоборот включать определенные типы объектов во время выполнения задания Data Pump Export или Data Pump Import. В преджней утилите экспорта для указания того, требуется ли экспортировать такие объекты, применялись параметры CONSTRAINTS, GRANTS и INDEXES. За счет использования параметров EXCLUDE и INCLUDE теперь стало можно включать и исключать объекты и многих других видов помимо тех четырех, фильтарцию которых можно было осуществлять ранее. Например, если необходимо сделать так, тобы во время экспорта не экспортировались никакие пакеты, такое поведение задается с помощью параметра EXCLUDE.
Проще говоря, параметр EXCLUDE помогает пропускать определенные типы объектво базы данных во время операции экспорта или импорта, а параметр INCLUDE наоборот – включать в эти операции только определенный набор объектов. Ниже показано, как в общем случае выглядит синтаксис этих параметров:
EXCLUDE=тип_объекта[:конструкция_имени] INCLUDE=тип_объекта[:конструкция_имени] Параметры EXCLUDE и INCLUDE являются взаимоисключащими. Поэтому во время выполенния одного и того же задания применять можно толкьо какой-то один из них; использовать тот и другой одновременно нельзя.
Как для параметра EXCLUDE, так и для параметра INCLUDE, элемент конструкцияимени является необязательным. Как известно, некоторые объекты в базе данных, например, таблицы, индексы, пакеты и процедуры, обладают именами, а некоторые, напримре, объекты GRANTS – нет. Элемент конструкцияимени в параметре EXCLUDE или INCLUDE позволяет приенять SQL-функцию для фильтрации именованных объектов.
Ниже приведен простой пример исключения всех таблиц, имя которые начинается с ECMP.
EXCLUDE=TABLE:”LIKE ‘EMP%’” В этом примере ”LIKE ‘EMP%’” пре конструкцию имени.
Элемент конструкция_имени является необязательным в параметрах EXCLUDE и INCLUDE. Он представляет собой просто средство фильтрации, позволяющее более точно определять тип подлежащих исключению или включению объектво (индексов, таблиц и т.д.). В случае его пропуска включаться или исключаться будут все объекты указанного типа.
В следующем примере Oracle исключит из операции экспорта все индексы, потому в элементе конструкция_имени не было указано никакого значения, требующего, чтобы исключались только определенные индексы:
EXCLUDE=INDEX Вдобавок параметр EXCLUDE может применяться для исключения целой схемы, как показано в следующем примере:
EXCLUDE=SCHEMA:”=’HR’” Параметр INCLUDE является противоположностью параметру EXLCUDE и позволяет принудительно включать в операцию экспорта только определенный набор объектов. Как и в случае параметра EXLCUDE, для указания того, какие точно объекты требуется экспортировать, вместе с INCLUDE тоже можно использовать элемент конструкция_имени.
Ниже приведены три примера, демонстрирующие примеение элемента конструкция_имени для ограничения выбираемых объектов:
INCLUDE=TABLE:”IN (‘EMPLOYEES’,’DEPARTMENTS’)”; INCLUDE=PROCEDURE INCLUDE=INDEX:”LIKE ‘EMP%’” В первом примере параметр INCLUDE указывает, что в процессе экспорта должны приниать участие только две таблицы: ECMPLOYEES и DEPARTMENTS, во втором – только процедуры, а в третьем – только индексы, причем лишь те, имя у которых начинается с EMP.
В следующем примере показано, как использовать символ косой черты для отмены двойных кавычек:
$ expdp scott/tiger DUMPFIEL=dum.file%U.dmp schemas=SCOT EXCLUDE=TABLE:\”=’EMP’\”, EXLUDE=FUNCTION:\”=’MY_FUNCTION’\” При выполнении фильтрации метаданных за счет применения параметра EXCLUDE и INCLUDE нужно помнить о том, что все объекты, которые зависят от какого-то из фильтуемых объектов, будут обрабатываться тем же образом, что и сам этот фильтруемый объект. Например, в случае использвоания параметра EXCLUDE для исключения некоторой таблицы также автоматичеки будут исключаться индексы, граничения, триггеры и прочие зависящие от этой тблицы объеекты.
Существует еще множество всевозможных параметров в т.ч. и шиврование, компрессиия и д.р.
Data Pump Import
$ nohup impdp scott/tiger dumpfile=datapumps:mydump01.dmp logfile=datapumps:mydump01.log & Иногда, (в моем случае при неудачном импорте) можно вытащить из файла дампа весь код DDL.
Для этого можно воспользоваться параметром SQLFILE.
$ nohup impdp scott/tiger dumpfile=datapumps:mydump01.dmp logfile=datapumps:mydump01.log sqlfile=datapumps:scott.sql job_name=scott_import_job_01 & Создается файл scott.sql с DDL.
Параметры фильтрации
Параметр CONTENT применяться в Data Pump Import, как и в Data Pump Export, для указания того, должны ли загружаться только строки (CONTENT=DATA_ONLY), строки и метаданные (CONTENT=ALL), либо только метаданные (CONTENT=METADATA_ONLY). Параметры EXLCUDE и INCLUDE имеют в Data Pump Import точно такое же предназначение, как и в Data Pump Export, и явялются взаимоисключающими, а в частности:
- Параметр INCLUDE используется для перечиления объектов, которые необходимо импортировать;
- Параметр EXCLUDE применятьтся для перечисления объектов, которые имортировать не требуется.
Ниже приведент простой пример использования параметра INCLUDE. В этом примере импорт ограничивается только объектами таблиц. В результате импортирована будет только таблица PERSONS.
INCLUDE=TABLE:”= ‘persons’ “ Для импорта только тех таблиц, имя у которых начинается с букв PER, можно использоть конструкцию INCLUDE=TABLE:”LIKE ‘PER%’”. Вдобавок параметр INCLUDE можно применять и отрицательным образом, указывая то, что все объекты с оперделенным синтаксисом должны игнорироваться: INCLUDE=TABLE:”NOT LIKE ‘PER%’”
Обратите внимаение на то, что в случае установки для параметра CONTENT занчения DATA_ONLY, использовать во время импорта ни параметр EXCLUDE ни параметр INCLUDE нельзя.
Параметр TABLE_EXISTS_ACTION позволяет указывать Data Pump Import, что следует делать в случае, если таблица уже существует. Для этого параметра можно устанавливать четыре разных значения:
- SKIP – (значение по умолчанию) – пропукать таблицу, если таковая уже существует;
- APPEND – присоединять строки к таблице;
- TRUNCATE – усекать таблицу и загружать данные из экспортного файла дампа.
- REPLACE – удалять таблицу, если таковая сущствует, создавать ее заново и снова загружать в нее данные.
Параметры переопределения
Параметр REMAP_TABLE
Параметр REMAP_TABLE позволяет переименовывать таблицу при выполнении операции импорта с сипользованием метода переноса табличных пространств.
TABLES=hr. employees REMAP_TABLE=hr. employees:emp В этом примере параметр REMAP_TABLE указывает, что при выполнении операции импорта имя таблицы hr.employees должно быть изменено на hr.emp
Параметр REMAP_SCHEMA
Параметр REMAP_SCHEMA позволяет перемещать объекты из одной схемы в другую. Задается этот параметр примерно так:
REMAP_SCHEMA=hr:oe В этом примере параметр REMAP_SCHEMA указывает, что при выполнении операции импорта требуется перемесить все объекты из исходной схемы HR в целевую схему OE. Утилита Data Pump Import может даже создать схему OE, если таковой в целевой базе данных не существует.
Параметр REMAP_TABLESPACE
Иногда бывает нужно, чтобы табличное пространство, в которое выполняется импорт даннных, отличалось от используемого в исходной базе данных. Параметр REMAP_TABLESPACE позволяет осуществлять во время импорта перемещение объектов из одного табличноо пространства в другое.
REMAP_TABLESPACE=’example_tbs’: ‘new_tbs’ Параметр REMAP_DATAFILE
При перемещении баз данных между двумя различными платформами, на каждой из которых используетс свое соглашие по именованию фалов, параметр REMAP_DATAFIE приходится очень кстати, поскольку позволяет изменять формат именования файлов. Ниже приведен пример, показывающий, как с помощью этого параметра указать утилите Data Pump Import, что вместо формата фаловой системы Windows, требуется использовать формат файловой системы UNIX. После этого при обнаружении в экспортном файле дампа людой ссылки на файл с именем в формате файловой истемы Windows, утилита Data Pump Import будет автоматически изменять имя файла в соответствии с форматом файловой системы UNIX.
REMAP_DATAFIELE=’DB1$:[HRDATA.PAYROLL]tbs6.f’:’/db1/drdata/payroll/tbs6.f’ Параметры TRANSFORM
Предположим, что требуется импортировать таблицу из другой схемиы или даже другой азы данных и не импортироват при этом другие атрибуты хранения объектов, т.е. необходимо просто перенести содержациеся в таблице данные. Параметр TRASNSFORM позволяет указать утилите Data Pump Import не импортировать оперделенные атрибуты хранения и атрибуты других видов. За счет применения параметра TRANSFORM можно исключать из таблицы или индекса конструкции STORAGE и TABLESPACE или только конструкции STORAGE. При выполнении импорта с помощью Data Pump Oracle создает объекты с использованием DDL-операторов, которые находит в экспортных файлах дампа. Параметр TRANSFORM, по сути, указывает утилите Data Pump Import изменять приводящие к созданию объектов операторы DDL оперделенным образом.
В целом синтаксис параметра TRANSFORM выглядит так:
Ниже приведено краткое описание того, что собой представляет кадый элемент.
1) Название_трансовармации. Существуют всего четыре опции, которые могут указываться на месте этого элемента. Эти опции позволяют, соответственно, изменять четыре основных вида характеристик объекта.
- SEGMENT ATTRIBUTES. Эта опция позволяет влиять на атриуты сегмента, в число которых вхдят физические атрибуты, атрибуты хранения, табличные пространства и журанлы. Принуждать Data Pump Import включать все эти атрибтуы можно, указав на месте название_трансформации этой опции со значением Y (SEGMENT_ATTRIBUTES=Y), которое является для этого параметра значением по умолчанию. В таком случае Data Pump Import будет включать все четыре атрибута сегмента вместе с их операторами DDL.
- STORAGE. За счет указания на месте название_трансформации опции STORAGE со значением Y (STORAGE=Y), представляющее собой значение по умолчанию, можно получать лишь атрибуты хранения тех объектов, которые являются частью задания Data Pump Import.
- OID. В случае указания на месте название_трансформации опции OID со значением Y (OID=Y), которое является для нее значением по умолчанию, объектым таблицам во время импорта будет приваиваться новй OID.
- PCTSPACE. За счет указания на месте название_трансформации опции PCTSPACE с положительным числом в качестве значения можно увеличивать выделяемый под объекты и файлы данных объем пространства на соответствующее количество процентов.
2) Значение. На месте элемента значение в параметре TRANSFORM может указываться либо значение Y (да), либо значение N (нет). Как упоминалось выше, для первых трех опций, которые могут указываться на месте название_трансформации, по умолчанию устанавливается занчение Y. Это означает, что по умолчанию Data Pump предусмативает выполнение импорта как атрибутов сегмента, так и атрибутов хранения объекта. В качестве альтернативного варианта, для этих опций можно устанавивать значение N и тем самым указывать Data Pump не импортировать исходные атрибуты сегмента и/или хранения. Что касается опции PCTSPACE, то для нее на месте элемета занчение можнет задваться только какое-то число.
3) Типобъекта. На месте элемета типобъекта можно указывать утилите Data Pump Import, объекты какого типа необходимо трансформировать. Это могут быть таблицы, индексы, табличные пространсва, типы, кластеры, граничения и прочие обхекты, в зависимости от опций, указываемых на месте название_транформации. В случае не указания типа подлежащих транформаци обхектов при использовании опции SEGMENT_ATTRIBUTES и STORAGE, эти опции будут применяться ко всем таблицам и индексам, которые являются частью операции импорта.
Ниже приведен пример применения параметра TRANSFORM:
TRANSFORM=SEGMENT_ATTIBUTES:N:table В этом примере для SEGMENT_ATTRIBUTES установлено занчение N, а в качестве типа объекта указана таблица. В такой спецификации параметр TRANSFROM указывает утилите Data Pump Import не импортировать существующие атрибуты хранения ни для каких таблиц.
Мониторинг выполнения заданий Data Pump
Наиболее важными для мониторинга за выполнением заданий Data Pump являются представления DBA_DATAPUMP_JOBS и DBA_DATAPUMP_SISSIONS.
Представление DBA_DATAPUMP_JOBS позволяет получать сводную информацию обо всех выполняющихся в текущий момент заданиях Data Pump.
SQL> set pagesize 0; SQL> set linesize 220; SQL> col owner_name format a20; SQL> col job_name format a20; SQL> col operation format a20; SQL> col state format a20; SQL> SELECT owner_name, job_name, operation, state FROM dba_datapump_jobs WHERE state = 'EXECUTING'; SYS IMP_M2M_SVT IMPORT EXECUTING Представление DBA_DATAPUMP_SESSIONS позволяет выяснять, какие пользователькие сеансы в текущий момент подключены к заданию Data Pump Export или Data Pump Import
SQL> SELECT sid, serial# FROM v$session s, dba_datapump_sessions d WHERE s.saddr = d.saddr; Просмотр информации о ходе выполненния заданий Data Pump
Ниже приведен типичный сценарий, который можнро использовать для получения информаци о том, сколько времени осталось до завершения выполнения задания Data Pump:
SQL> SELECT opname, target_desc, sofar, totalwork, start_time, time_remaining FROM v$session_longops; - OPNAME — имя задания Data Pump
- TOTALWORK — показывает, сколько всего мегабайт было насчитано для выполнения данного задания;
- SOFA — показывает, сколько пока было передано мегабайт во время выполнения данного задания;
Дополнительно
Oracle Data Pump 21c and Cloud Object Stores
https://www.youtube.com/watch?v=6S2N1-V5qc8
Tags: Oracle Database, экспорт, импорт, Data Pump
| |
|
|
Oracle DBA
Собираем также материалы по: SQL & PL/SQL
Лучше потратить какое-то количество времени, чтобы записать успешный опыт, чем потом повторно воспроизводить его по памяти.
Все материалы обновляются по мере нахождения лучших практик и апгрейда знаний. Если будут желающие добавлять свои знания или исправлять ошибки и неточности, пишите в телеграм чате. Если будет учавствовать больше людей, качество материалов будет улучшаться и обновляться быстрее. Ссылки на ваши профили в соц. сетях будут добавлены в статьях, в которых вы учавствуете.