Борьба с несбалансированностью классов с помощью модуля NEARMISS

В этой статье я расскажу об одном из методов для устранения дисбаланса предсказываемых классов. Важно уточнить, что многие методы, которые строят вероятностные модели, прекрасно работают и без устранения несбалансированности. Однако, когда мы переходим к построению невероятностных моделей или когда рассматриваем задачу классификации с большим количеством классов, стоит озаботиться решением проблемы дисбаланса классов.
Если не бороться с этой проблемой, то модель будет перегружена бо́льшим классом, в следствии будет игнорировать меньший класс, неправильно классифицировать его, поскольку модели будет не хватать примеров и свойств редкого класса. Таким образом, несбалансированность классов напрямую влияет на точность и качество результатов машинного обучения.
Метод NearMiss — это метод недостаточной выборки. Он пробует сбалансировать распределение классов путём случайного исключения наблюдений из бо́льших классов. Если экземпляры из двух разных классов очень похожи между собой, метод удаляет наблюдение из мажоритарного класса.
Давайте рассмотрим работу этого метода на практике. Для начала установим необходимые нам библиотеки через стандартный pip в cmd:
pip install pandas pip install numpy pip install sklearn pip install imblearnЯ буду использовать набор данных о сессиях, связанных с поведением пользователей на веб-страницах онлайн-магазина.
import pandas as pd import numpy as np df = pd.read_csv('online_shoppers_intention.csv') df.shapeСтолбец для прогнозирования называется «Revenue» и может принимать 2 значения: True (пользователь совершил покупку) и False (пользователь не совершил покупку). Посмотрим, какое количество наблюдений приходится на каждый из классов.
df['Revenue'].value_counts()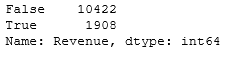
Как видно, классы являются несбалансированными, поскольку делятся примерно в соотношении 85% и 15%.
Разделим наблюдения на обучающую и тестовую выборки:
Y = df['Revenue'] X = df.drop('Revenue', axis = 1) feature_names = X.columns from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.3, random_state = 97)Посмотрим на размерность сформированных наборов данных:
print('Размерность набора данных X_train: ', X_train.shape) print('Размерность набора данных Y_train: ', Y_train.shape) print('Размерность набора данных X_test: ', X_test.shape) print('Размерность набора данных Y_test: ', Y_test.shape)
Далее воспользуемся логистической регрессией и выведем отчёт с основными показателями классификации.
from sklearn.linear_model import LogisticRegression lregress1 = LogisticRegression() lregress1.fit(X_train, Y_train.ravel()) prediction = lregress1.predict(X_test) print(classification_report(Y_test, prediction))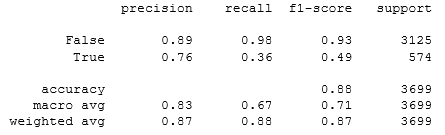
Отметим, что точность модели 88%. Колонка «recall» показывает меру полноты классификатора, способность классификатора правильно находить все положительные экземпляры. Из неё видно, что отзыв миноритарного класса гораздо меньше, то есть модель более склонна к классу большинства.
Перед применением метода NearMiss выведем количество наблюдений каждого класса:
print('Перед применением метода кол-во меток со значением True: <>'.format(sum(y_train == True))) print('Перед применением метода кол-во меток со значением False: <>'.format(sum(y_train == False)))Перед применением метода количество меток со значением True: 1334
Перед применением метода количество меток со значением False: 7297
Теперь воспользуемся методом и выведем количество наблюдений каждого класса.
from imblearn.under_sampling import NearMiss nm = NearMiss() X_train_miss, Y_train_miss = nm.fit_resample(X_train, Y_train.ravel()) print('После применения метода кол-во меток со значением True: <>'.format(sum(Y_train_miss == True))) print('После применения метода кол-во меток со значением False: <>'.format(sum(Y_train_miss == False)))После применения метода количество меток со значением True: 1334
После применения метода количество меток со значением False: 1334
Видно, что метод сравнял классы, уменьшив размерность доминирующего класса. Воспользуемся логистической регрессией и выведем отчёт с основными показателями классификации.
lregress2 = LogisticRegression() lregress2.fit(X_train_miss, Y_train_miss.ravel()) prediction = lregress2.predict(X_test) print(classification_report(Y_test, prediction))
Значение отзывов меньшинства повысилось до 84%. Но из-за того, что выборка большего класса значительно уменьшилась, понизилась точность модели до 61%. Таким образом, этот метод действительно помог справиться с несбалансированностью классов.
- несбалансированные классы
- nearmiss
- машинное+обучение
- Python
- Программирование
- Машинное обучение
Сэмплинг в условиях несбалансированности классов

При классификации в условиях несбалансированности классов могут быть использованы два подхода: балансировка классов и оптимизация модели (например, выбор дискриминационного порога при определении класса). Данная статья посвящена рассмотрению алгоритмов и методов балансировки классов.
В машинном обучении нередко возникают ситуации, когда в обучающем наборе данных доля примеров некоторого класса оказывается слишком низкой (такой класс часто называют миноритарным), а другого — слишком большой (такой класс называют мажоритарным). Эта ситуация в теории машинного обучения известна как несбалансированность классов (class imbalance), а классификация в условиях несбалансированности классов называется несбалансированной классификацией (unbalanced classification).
Несбалансированность классов как правило создаёт проблемы при решении задач классификации, поскольку построенные на таких данных модели имеют «перекос» в сторону мажоритарного класса, т.е. с большей вероятностью присваивают его метку класса новым наблюдениям при практическом использовании модели. Данное явление известно как переоценка (overestimation). Если модель построена так, что отдаёт предпочтение миноритарному классу, то имеет местно недооценка (underestmation).
Особенно актуальна проблема несбалансированности классов в таких областях как кредитный скоринг, медицина, директ-маркетинг и т.д. Практическое использование классификаторов, построенных на обучающих наборах с несбалансированными классами часто оказывается неэффективным из-за большого числа ошибок. При этом издержки ошибок, связанных с ошибочной классификацией мажоритарного или миноритарного классов как правило неравнозначны.
Действительно, если классификатор в системе кредитного скоринга определит «плохого» заёмщика как «хорошего» и ему будет выдан кредит, то при банкротстве последнего банк потенциально теряет всю сумму кредита. Напротив, если «хороший» заёмщик будет классифицирован как «плохой», банк рискует только упущенной выгодой в виде процентов.
Очевидно, что классификация в условиях несбалансированности классов должна производиться с учётом неравенства издержек классификации. Модель должна быть настроена таким образом, чтобы минимизировать число ошибок классификации, связанных с большими издержками. Такой тип классификации известен как классификация, чувствительная к издержкам (cost-sensitive classification).
При классификации в условиях несбалансированности классов могут быть использованы два подхода: балансировка классов и оптимизация модели (например, выбор дискриминационного порога при определении класса). Данная статья посвящена рассмотрению алгоритмов и методов балансировки классов.
Процесс балансировки классов реализуется с помощью соответствующих алгоритмов сэмплинга, которые можно разделить на случайные и специальные. Ребалансировка классов может происходить путём увеличения числа примеров миноритарного класса (undersampling), либо путём сокращения числа примеров мажоритарного (oversampling). Возможно также и сочетание обоих подходов.
Сокращение числа примеров мажоритарного класса
Существует несколько стратегий балансировки обучающих выборок путём сокращения числа примеров мажоритарного класса.
Случайное удаление (random undesampling). Это самая простая и примитивная стратегия, но понятная и несложная в реализации. Сначала определяется число K примеров доминирующего класса, которое требуется удалить, чтобы достичь требуемого соотношения классов в обучающей выборке. Затем случайным образом выбираются K наблюдений доминирующего класса и удаляются.
Метод привлекателен тем, что прост в реализации. Однако, при его использовании могут быть потеряны наблюдения, несущие полезную информацию. Поэтому предпочтительно сделать стратегию балансировки классов более управляемой, то есть выполняемой в соответствии с некоторыми правилами. Рассмотрим несколько таких стратегий.
Поиск связей Томека (Tomek Links). Пусть в наборе данных имеется пара наблюдений E_i и E_j , принадлежащих различным классам. Обозначим расстояние между векторами этих наблюдений в пространстве признаков как d(E_i,E_j) . Пара наблюдений (E_i,E_j) называется связью Томека, если они относятся к разным классам и не существует точки E_k , такой, что d(E_i,E_k)
Несложно увидеть, что связи Томека объединяют близко расположенные наблюдения различных классов. Большое количество связанных таким образом наблюдений вызывает эффект наложения классов в пространстве признаков, как показано на рисунке ниже.
Удаление наблюдений, входящих в связи Томека и относящихся к доминирующему классу, не только выравнивает баланс данных, но и делает границы классов более чёткими и выраженными, что повышает качество классификации.
Правило соcредточенного ближайшего соседа (Condensed Nearest Neighbor Rule). Из исходного набора данных L извлекаются все примеры миноритарного класса и один мажоритарного (обозначим полученное подмножество как S ). Затем производится классификация всех примеров из L по методу одного ближайшего соседа (1-NN), когда каждому, случайно выбранному наблюдению присваивается метка класса ближайшего соседа. При этом, если для наблюдения допущена ошибка классификации (найденный и фактический классы не совпадают), то оно добавляется в S .
Таким образом, из множества L в множество S будут перемещены все наблюдения мажоритарного класса, для которых ближайшим соседом будет наблюдение другого класса. Процесс будет идти до тех пор, пока в исходном наборе не закончатся наблюдения доминирующего класса, близкие к наблюдениям другого класса. В результате в множестве S будет обеспечен баланс классов.
Односторонний сэмплинг (One-side sampling, one-sided selection — OSS). В основе идеи данного подхода лежит сочетание двух предыдущих. На первом шаге применяется правило сосредоточенного ближайшего соседа, а на втором — удаляются все мажоритарные наблюдения, участвующие в связях Томека. Таким образом, удаляются большие «сгустки» мажоритарных наблюдений, а затем область пространства со скоплением миноритарных очищается от мажоритарных, которые создают эффект шума на границах классов и мешают их распознаванию.
Правило «очищающего» соседа (neighborhood cleaning rule — NCR). Идея здесь такая же, как и у одностороннего сэплинга. Все наблюдения классифицируются по правилу трех ближайших соседей (3-NN). Затем удаляются следующие примеры мажоритарного класса:
- которые правильно распознаны;
- являющиеся соседями миноритарных примеров, которые были неверно классифицированы.
Преимущество данного подхода в том, что увеличение области соседства позволяет лучше «очищать» данные от шумов.
Теперь рассмотрим другой подход — увеличение числа примеров миноритарного класса.
Увеличение числа примеров миноритарного класса
Дублирование примеров миноритарного класса (Oversampling). Самый простой метод – это дублирование примеров миноритарного класса. В зависимости от того, какое соотношение классов необходимо получить в выборке, выбирается случайным образом соответствующее количество наблюдений для дублирования.
Такой подход к восстановлению баланса не всегда является наиболее эффективным, поэтому был предложен специальный метод увеличения числа наблюдений миноритарного класса – алгоритм SMOTE (Synthetic Minority Oversampling Technique).
Алгоритм SMOTE. В основе алгоритма лежит идея генерации некоторого количества искусственных наблюдений, которые были бы «похожи» на наблюдения, имеющиеся в миноритарном классе, но при этом не дублировали их. Для создания нового примера находят разность d=X_b−X_a , где X_a и X_b — векторы признаков соседних наблюдений a и b из миноритарного класса, которые находят с помощью метода ближайшего соседа.
Для наблюдения b формируется область из k соседей, из которых в дальнейшем выбирается наблюдение. Затем X_a и X_b умножаются на некоторое случайное значение из интервала (0, 1) в результате чего исходное расстояние d преобразуется к \widehat . Затем путём суммирования X_a и \widehat вычисляются координаты вектора нового наблюдения.
Поясним сказанное на следующем примере (рис.4).
На рисунке для примера миноритарного класса X_1 определяются 5 ближайших соседей того же класса X_2, X_3, X_4, X_5 и X_6 . Затем вычисляется расстояние между X_1 и каждым из них: d(X_1,X_2), . d(X_1,X_6) . Эти расстояния показаны линиями.
Эти расстояния умножаются на случайное число из диапазона (0..1) и результат откладывается от X_1 вдоль линии, соединяющей его с соседом, на конце соответствующего отрезка формируется искусственный пример. Проще говоря, алгоритм формирует новые наблюдения, выбирая случайно место на прямой между объектом и его ближайшим соседом. Благодаря такому подходу искусственные наблюдения всегда будут формироваться вблизи существующих объектов, но не совпадать с ними.
Алгоритм SMOTE позволяет задавать количество наблюдений, которое необходимо искусственно сгенерировать. При этом степень сходства примеров a и b можно регулировать путем изменения числа ближайших соседей: чем оно меньше, тем выше будет степень сходства.
Недостатком данного подхода является то, что алгоритм просто увеличивает плотность наблюдений в областях векторного пространства, «населённых» преимущественно миноритарным классом. Т.е. работает эффективно, когда такие области имеются. Если же примеры миноритарного класса расположены равномерно, то в результате только увеличивается перемешивание классов, что затрудняет классификацию. Это проиллюстрировано на рисунке 5.
На рисунке видно, что генерация искусственных наблюдений имеет место в основном в области, выделенной прямоугольником, где и изначально был паритет классов. В менее населённых областях пространства признаков генерации новых примеров практически нет.
Решить данную проблему позволяет модификация SMOTE, которая получила название ASMO (Adaptive Synthetic Minority Oversampling). Алгоритм ASMO состоит из следующих шагов:
- Если для каждого i -ого примера миноритарного класса из k ближайших соседей g≤k принадлежит к мажоритарному, то набор данных считается «рассеянным». В этом случае используют алгоритм ASMO, иначе применяют SMOTE (как правило, g задают равным 20).
- Используя только примеры миноритарного класса, выделить несколько кластеров (например, с помощью алгоритма k-средних), как показано на рисунке 6.
- Сгенерировать искусственные записи в пределах отдельных кластеров на основе всех классов. Для каждого примера миноритарного класса находят m ближайших соседей, и на основе них (также как в SMOTE) создаются новые записи.
Такая модификация алгоритма SMOTE делает его более адаптивным к различным наборам данных с несбалансированными классами. Недостаток подхода в том, что фактически приходится решать две задачи — кластеризации и сэмплинга. При этом, если выраженная кластерная структура в исходных данных отсутствует, то и алгоритм окажется неэффективным.
Алгоритм ADASYN. Ещё одним недостатком алгоритма SMOTE является то, что он для каждого примера миноритарного класса создаёт одно и то же количество искусственных примеров. Это не вполне оптимально, поскольку не все примеры одинаково «просты» в обучении. Например, наблюдения, расположенные вблизи границ классов обычно «перемешаны» с наблюдениями соседнего класса, поэтому алгоритму обучения сложнее их распознать. Тогда при оверсэмплинге для таких примеров логично генерировать больше искусственных наблюдений, чтобы сделать границу класса более чёткой. На этом принципе и основана работа алгоритма ADASYN.
Путь имеется выборка S , содержащая m наблюдений x_i,y_i, i=1..m . Здесь x_i — n -мерный вектор признаков, y_i — метка класса. Обозначим m_r и m_x — число объектов миноритарного и мажоритарного класса соответственно, так что m_r
Алгоритм состоит из следующих шагов.
- Вычислить показатель несбалансированности классов: d=m_r/m_x .
- Задать порог максимально допустимого показателя несбалансированности d_ и проверить, выполняется ли условие d
- Определить число искусственных наблюдений, которое должно быть сгенерировано из миноритарного класса: G=(m_x−m_r)⋅β , где β — уровень баланса выборки. Так, β=1 означает, что выборка полностью сбалансирована.
- Для каждого наблюдения x_i из миноритарного класса найти k ближайших соседей на основе расстояния Евклида и вычислить отношение r_i=Δ_i/k , где Δ_i — количество из k ближайших соседей вектора x_i , которые принадлежат к мажоритарному классу, т.е. r_i∈[0,1] .
- Нормализовать r_i в соответствии с выражением:
\widehat_=_/\sum\limits_^r_ .- Вычислить количество искусственных примеров, которые нужно сгенерировать для каждого примера миноритарного класса x_i: g_=\widehat_\cdot G , где G — общее число искусственных примеров, которое должно быть сгенерировано для миноритарного класса.
- Для каждого примера миноритарного класса x_i генерировать искусственные примеры g_i в процессе выполнения следующего цикла:
- случайно выбрать один пример миноритарного класса x_ из k ближайших соседей x_i ;
- сгенерировать искусственный пример s_=x_+(x_-x_)\cdot \lambda , где λ — случайное число из диапазона [0, 1].
Таким образом, ключевая идея алгоритма ADASYN заключается в использовании \widehat_ в качестве критерия для автоматического определения количества искусственных примеров, которые необходимо сгенерировать для каждого миноритарного примера. Фактические, \widehat_ это показатель распределения весов для различных примеров миноритарного класса в соответствии с их уровнем сложности для обучения.
Результирующий набор данных после применения алгоритма ADASYN не только обеспечит сбалансированное представление данных в соответствии с желаемым уровнем баланса, определяемым коэффициентом β , но и также заставит алгоритм обучения сосредоточиться на наиболее сложных для обучения примерах. В этом и заключается главное отличие алгоритма ADASYN от SMOTE, в котором для каждого примера миноритарного класса генерируется одинаковое количество искусственных примеров.
Таким образом, классификация в условиях несбалансированности классов является серьёзной проблемой с точки зрения получения корректных результатов. Поэтому если несбалансированность имеет место в обучающем наборе данных, необходимо применить ту или иную стратегию балансировки выборки или построенной модели. Это позволяет если не полностью решить проблему несбалансированности, то во всяком случае снизить её остроту.
Другие материалы по теме:
Дисбаланс классов: как правильно провести классификацию на несбалансированной выборке

Проблема дисбаланса классов может привести при классификации к недообучению модели, а не верно выбранная метрика для оценки качества работы алгоритма к ложному восприятию качества построенной модели. Чтобы избежать этих ошибок нужно понимать logic behind, с которой подробно разберемся в статье.
Что такое дисбаланс:
Важно также заметить, что разница в количестве представленных наблюдений по классам – это не разреженность признаков. Ситуация, в которой у доминирующей части наблюдений отсутствует класс, а остальные наблюдения в приблизительно равных пропорциях представлены в выборке дисбалансом не является.
Дисбалансом также принято считать существенную разницу в количественном представлении классов в выборке.
Разница в 10-20% не будет считаться дисбалансом, тем не менее итоговой «отсечки», по которой выборку можно назвать несбалансированной нет, это всегда эвристика, которая зависит от конкретной задачи.
Есть и обратная ситуация, когда минорный класс настолько мало представлен в выборке, например, 1/10.000, что задача из классификации несбалансированной выборки должна перейти в разряд детектирования аномальных наблюдений, которая решается уже другими методами.
Природа дисбаланса:
Это самый первый вопрос, который необходимо выяснить после установления факта наличия дисбаланса в выборке наблюдений.
Распространенное явление, почему появился дисбаланс классов – это наличие дубликатов в выборке. Логичным действием в такой ситуации является удаление повторяющихся наблюдений.
Дисбаланс может встретиться в многоклассовой задаче из-за исторических особенностей выборки, например, это популяция какого-то редкого вида.
Дисбаланс классов может возникать в случае, если не проведена стратификация при делении тренировочной и тестовой выборках, стратификацию по классам – зависимой переменной, можно установить при помощи параметров библиотеки sklearn.train_test_split, тогда выборка сохранит одинаковый «баланс» или «дисбаланс» в обеих частях выборки.
Функционал ошибки и метрика оценки качества
Если в задаче иcпользуется функция потерь logloss, то не естественное сокращение дисбаланса классов приведет к тому, что алгоритм станет неоткалиброванным.
Также если в задаче используется метрика ROC-AUC, то дисбаланс классов нет необходимости выравнивать, потому что метрика не чувствительна к смещению.
Семплирование
Существует два базовых метода, связанных с семплированием: oversampling и undersampling. В первом случае искусственно расширяется минорный класс, используя, например, технику bootstrapping, а во втором случае рандомно обрезается мажорный класс – из него случайным образом отбирается выборка соизмеримая по размеру с минорным классом.
Давайте, сгенерируем искусственную выборку, на которой, сможем посмотреть применимость методов.
# импорт необходимых библиотек from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # создаем искусственный датасет из 2 признаков и 1000 наблюдений. # для воспроизводимости результатов необходимо зафиксировать random_state X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) Визуализируем датасет, чтобы убедиться в том, что получилось сгенерировать дисбаланс. for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() 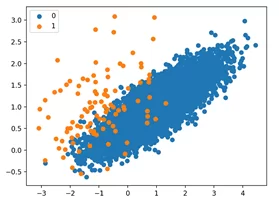
Существуют также методы, так называемого «умного недосемплирования».
Стратегия Nearmiss – 1:
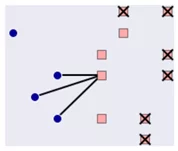
Из мажоритарного класса выбираются объекты, у которых среднее расстояние минимально до N ближайших наблюдений минорного класса.
Для работы с несбалансированной выборкой можно использовать библиотеку imblearn
# параметр version отвечает за тип семплирования undersample = NearMiss(version=1) # генерируем новую выборку X, y = undersample.fit_resample(X, y) # построим новый график for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() 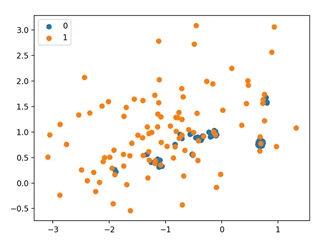
Как видно из диаграммы, в облаке наблюдений остались только те точки мажорного, которые ближе всего находились к представителям минорного.
Стратегия Nearmiss – 2:
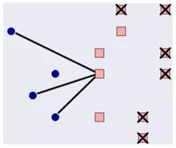
Из мажоритарного класса выбираются объекты, у которых среднее расстояние минимально до N самых дальних наблюдений минорного класса.
Аналогичным образом воспроизведем использование метода при помощи кода:
# указываем версию семплирования и кол-во соседей undersample = NearMiss(version=2, n_neighbors=3) # проводим андерсемплинг X, y = undersample.fit_resample(X, y) # строим график for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() 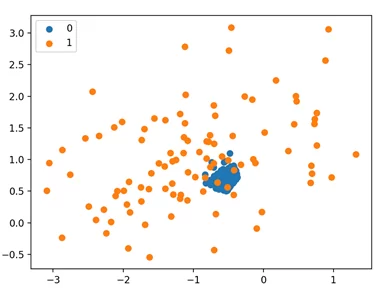
Исполнив пример, мы видим, что Nearmiss-2 выбирает наблюдения, которые находятся в центре масс для перекрытия между двумя классами.
SMOTE: Synthetic Minority Oversampling Techniques и ADASYN: Adaptive Synthetic
В методе SMOTE выбирается одно из наблюдений минорного класса, для него идет поиск k ближайших соседей из того же минорного класса, так формируются «выпуклые пары» объектов. На отрезках между наблюдениями «соседями» выбирается случайный объект, который искусственно расширяет выборку.
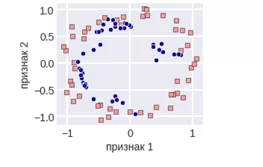
Рассмотрим имплементацию метода SMOTE:
# заменяем тип трансформации oversample = SMOTE() X, y = oversample.fit_resample(X, y) # строим аналогичный график для результатов for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() 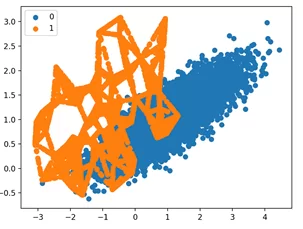
Метод ADASYN имеет схожу логику, но количество искусственно добавленных объектов минорного класса пропорционально количеству объектов доминирующего класса в окрестности наблюдения.
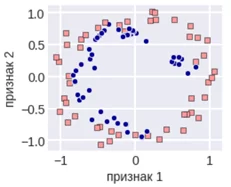
Рассмотрим пример работы ADASYN – адаптивного синтетического семплирования на примере:
# изменяем метод семплирования oversample = ADASYN() X, y = oversample.fit_resample(X, y) # визуализируем результаты for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() 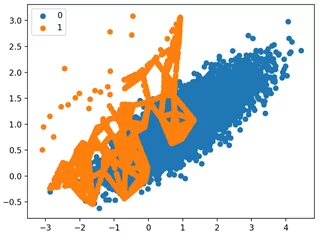
Из примера видим, что наблюдения разных классов, расположенные близко, друг к другу получают наибольший фокус. Остальные наблюдения, расположенные относительно далеко могут быть восприняты, как выбросы. ADASYN уделяет слишком много внимания этим областям пространства функций, и это может привести к снижению производительности модели.
Взвешивание объектов: Во многих алгоритмах, реализованных в sklearn, а также в CatBoost есть возможность уравнять дисбаланс классов, используя веса, присваиваемые наблюдениям. Так, обычно наблюдениям доминирующего класса (с меткой 0) равными 1, а наблюдениям минорного класса присваивают веса 1 — m_40⁄m_1, где m_0,m_1 – это количество наблюдений по классам 0 и 1 соответственно. При оценке такого алгоритма с уравниванием по весам стоит использовать метрику оценки – AUC-ROC, так как она строится в относительных координатах – TRP, FPR.
Присваивание весов можно сделать не вручную, а автоматически, использовав параметр class_weight=’balanced’.
Итог: имея в виду список «маяков», на которые стоит обращать внимание при работе с несбалансированной выборкой, Вы с большой вероятностью избежите большого числа логических ошибок, которые можно допустить, если решать задачу «в лоб».
Балансировка классов в машинном обучении
При использовании алгоритма машинного обучения очень важно обучить модель на наборе данных с почти таким же количеством выборок. Это называется сбалансированным классом. Нам нужны сбалансированные классы для обучения модели, но, если классы не сбалансированы, нам нужно использовать метод балансировки классов перед использованием алгоритма машинного обучения. Итак, в этой статье я расскажу вам, что такое балансировка классов и как реализовать методы балансировки классов с помощью Python.
Что такое балансировка классов?
В машинном обучении балансировка классов означает балансировку классов с несбалансированными выборками. Перед использованием алгоритма машинного обучения важно избежать дисбаланса классов, потому что наша конечная цель – обучить модель машинного обучения, которая хорошо обобщается для всех возможных классов, предполагая, что у нас есть двоичный набор данных с равным количеством выборок.
Итак, перед использованием алгоритма машинного обучения очень важно посмотреть на распределение классов, чтобы исправить проблемы балансировки классов. Например, давайте посмотрим, как мы можем обнаружить несбалансированные классы, создав несбалансированный набор данных с помощью функции make_classification в библиотеке Scikit-learn в Python:
from sklearn.datasets import make_classification nb_samples = 1000 weights = (0.95, 0.05) x, y = make_classification(n_samples=nb_samples, n_features=2, n_redundant=0, weights=weights, random_state=1000) print(x[y==0].shape) print(x[y==1].shape)
результат:
Как и ожидалось, первый класс является доминирующим. Чтобы сбалансировать классы этого типа набора данных, у нас есть два метода предотвращения дисбаланса классов в машинном обучении:
- Повторная выборка с заменой
- Передискретизация SMOTE
Теперь давайте рассмотрим оба этих метода балансировки классов, чтобы увидеть, как мы можем сбалансировать классы, прежде чем использовать какой-либо алгоритм машинного обучения.
Передискретизация с заменой:
В методе передискретизации с заменой мы передискретизируем набор данных, ограниченный второстепенным классом, до тех пор, пока не достигнем желаемого количества выборок в обоих классах. Поскольку мы работаем с заменой, ее можно повторять n раз. Но результирующий набор данных будет содержать точки данных, выбранные из 54 возможных значений (согласно нашему примеру). Вот как мы можем использовать передискретизацию с техникой замены с помощью Python:
numpy as np from sklearn.utils import resample x_resampled = resample(x[y==1], n_samples=x[y==0].shape[0], random_state=1000) x_ = np.concatenate((x[y==0], x_resampled)) y_ = np.concatenate((y[y==0], np.ones(shape=(x[y==0].shape[0],), dtype=np.int32))) print(x_[y_==0].shape) print(x_[y_==1].shape)
результат:
Передискретизация SMOTE:
Передискретизация SMOTE – один из самых надежных подходов, который призван предотвратить дисбаланс классов. Он расшифровывается как «Техника передискретизации синтетического меньшинства». Этот метод разработан специально для создания новых образцов, соответствующих второстепенным классам. Чтобы реализовать технику передискретизации SMOTE для балансировки классов, мы можем использовать библиотеку несбалансированного обучения, в которой есть много алгоритмов для такого рода проблем. Вот как можно реализовать передискретизацию SMOTE для балансировки классов с помощью Python:
from imblearn.over_sampling import SMOTE smote = SMOTE(random_state=1000) x_, y_ = smote.fit_sample(x, y) print(x_[y_==0].shape) print(x_[y_==1].shape)
результат:
Резюме
И передискретизация с заменой, и передискретизация SMOTE – очень полезные методы для предотвращения дисбаланса классов в машинном обучении. Повторная выборка с методом замены используется для увеличения количества выборок, но результирующее распределение будет таким же, как значения, взятые из существующего набора. При этом, передискретизация SMOTE генерирует такое же количество выборок с учетом соседей. Надеюсь, вам понравилась эта статья о том, как избежать дисбаланса классов в машинном обучении и о реализации методов балансировки классов с использованием Python.