Как установить forceplan для таблицы sql
Параметр FORCEPLAN иллюстрирует старый метод настройки в Microsoft SQL Server и Sybase. Он требует отдельного оператора SQL: SET FORCEPLAN ON
Этот параметр действует на весь SQL-код, который выполняется в текущем соединении, пока вы не выполните оператор: SET FORCEPLAN OFF
Когда значение параметра FORCEPLAN равно ON, база данных выполняет только простейшую оптимизацию SQL. Обычно она использует планы вьшолнения с вложенными циклами, которые работают при помощи индексов и соединяют таблицы в том же порядке, в каком они перечислены в разделе FROM. Если вы хотите получить план именно такого типа, то SET FORCEPLAN будет идеальным вариантом, поскольку не только включает нужный план, но и экономит время разбора, которое в противном случае было бы потрачено на выбор из большого диапазона планов, особенно для соединений множества таблиц. Это, образно говоря, обоюдоту-пой меч, поэтому применяйте его только когда знаете, что в разделе FROM указан правильный порядок соединения, и хотите использовать вложенные циклы.
5Диаграммное изображение простых запросов SQL
Для превращения искусства настройки SQL в науку необходим общий язык, общая парадигма для описания и решения проблем настройки SQL. Эта книга — первое печатное издание, которое может научить вас методу, исправно служившему мне и тем, кому я его объяснил. Я называю этот метод методом диаграммного изображения запросов.
Как и любой новый инструмент, метод диаграммного изображения запросов требует некоторых авансовых инвестиций и затрат времени от будущего пользователя. Но мастерство владения этим инструментом обеспечивает гигантские вознаграждения, поэтому я прошу вас быть терпеливыми — трудно будет лишь в самом начале. Скоро вы найдете ответы, которые не дал бы вам ни один другой инструмент, пртем приложить првдется лишь немного усилий. А в конце изучения мой метод станет вам настолько привычным, что, как и в случае с любым другим хорошим инструментом, вы не будете замечать, что используете его.
Зачем нужен новый метод?
Поскольку я прошу вас быть терпеливыми, начну с рассмотрения того, зачем нам нужен этот новый инструмент. Почему бы не использовать то, что вы уже знаете, например информацию SQL-сервера, для решения проблем производительности? Самая большая проблема с использованием SQL-сервера для настройки — то, что он предлагает одновременно слишком много и недостаточно информации для решения задачи настройки. Информация SQL-сервера существует для функционального описания, какие столбцы и строки нужны приложению из каких таблиц, по каким условиям их нужно соединять, и в каком порядке возвращать. Однако большая часть этой информации совершенно не относится к настройке запроса. С другой стороны, информация, относящаяся и даже жизненно необходимая для настройки-о распределении данных в таблицах- полностью отсутствует. У SQL много общего со старыми проблемами эквивалентности, печально известными еще из математики начальной школы, разве что SQL-сервер с большей вероятностью пропускает необходимую информацию. Кахсую задачу, из двух приведенных ниже, вам будет легче решить?
Для отдыха на природе Джонни приготовил по восемь лепешек, три сосиски, одной полоске бекона и два яйца для себя и своих друзей Джима, Мэри и Сью. Каждая девочка отдала одну треть своих сосисок, 25 % лепешек и половину яиц мальчикам. Джим уронил лепешку и две сосиски, и их украл енот. У Джонни аллергия на кленовый сироп, а у Мэри на половине лепешек была клубника, но все остальные поливали лепешки кленовым сиропом. Сколько лепешек с кленовым сиропом съел каждый ребенок?
(8+(0.25 X 8) -1) + (0.75 х 8/2) + (0.75 х 8) — ? Естественно, вторую задачу решать проще.
Диаграмма запроса — это скелетный синтез основных элементов настройки проблемы эквивалентности SQL и ключевых распределений данных, необходимых для поиска оптимального плана исполнения. Благодаря скелетному синтезу вы отбрасываете отвлекающие, ненужные детали и сосредотачиваетесь на ядре проблемы. В результате получается намного более компактный язык, который можно использовать для реальных задач и упражнений. Проблемы, которые на языке SQL описывались бы страницами кода (а в реальных проблемах, когда патентованный код нельзя легально просмотреть, потребовались бы дни для изучения поведения запроса), превращаются в простые, абстрактные диаграммы, занимающие половину страницы. Ваш темп изучения чрезвычайно ускорится с этим инструментом, частично благодаря тому, что сходство между проблемами настройки и функционально отличающимися запросами станет очевидным. Вы увидите шаблоны и сходства, которые никогда бы не заметили на уровне SQL-кода, и будете многократно использовать свои решения с минимальными усилиями.
Ни один известный мне инструмент не создаст для вас ничего подобного диаграмме запроса, так же, как ни один инструмент не превращает математическую проблему эквивалентности в простую арифметику. Поэтому вашим первым шагом в настройке SQL будет перевод проблемы SQL в проблему диаграммы запроса. Так же, как преобразование задач эквивалентности в арифметическое выражение является самым трудным шагом, вы, вероятнее всего, будете считать перевод проблем настройки SQL в диаграммы запросов самым сложным (или хотя бы самым долгим) шагом в настройке SQL, по крайней мере, в первое время. Однако обнадеживает то, что, хотя человеческие языки развивались бессистемно по мере эволюции общения между сложными человеческими разумами, SQL был создан как структура для общения с компьютерами. Проблемы эквивалентности настройки SQL составляют гораздо меньшую сферу интересов, чем проблемы эквивалентности натуральных языков. По мере тренировки процесс перевода SQL в диаграмму запросов становится все быстрее и проще, иногда вы даже сможете даже быстро выполнить этот перевод в уме. Как только вы сделаете диаграмму запросов и получите хотя бы начальное понимание метода диаграммного гаображения запросов, то будете считать большинство проблем настройки тривиальными.
Дополнительным и совершенно незапланированным преимуществом оказывается то, что диаграммы запросов оказываются ценным средством в поиске целых классов незаметных логических ошибок приложения, которые трудно обнаружить при тестировании, так как они возникают в достаточно редких и трудных случаях. В главе 7 я буду подробно обсуждать, как использовать эти диаграммы для поиска и исправления таких логических проблем.
Руководство по тех. обслуживанию
![]()
В данном разделе приведена инструкция для установки SQL Server 2019. Для более старших версий процесс установки принципиально не отличается.
Установка SQL Server 2019
1. Установите SQL Server 2019 или выше. В зависимости от размеров базы данных и необходимых функций можно использовать различные редакции .
Выберите пункт Скачать носитель
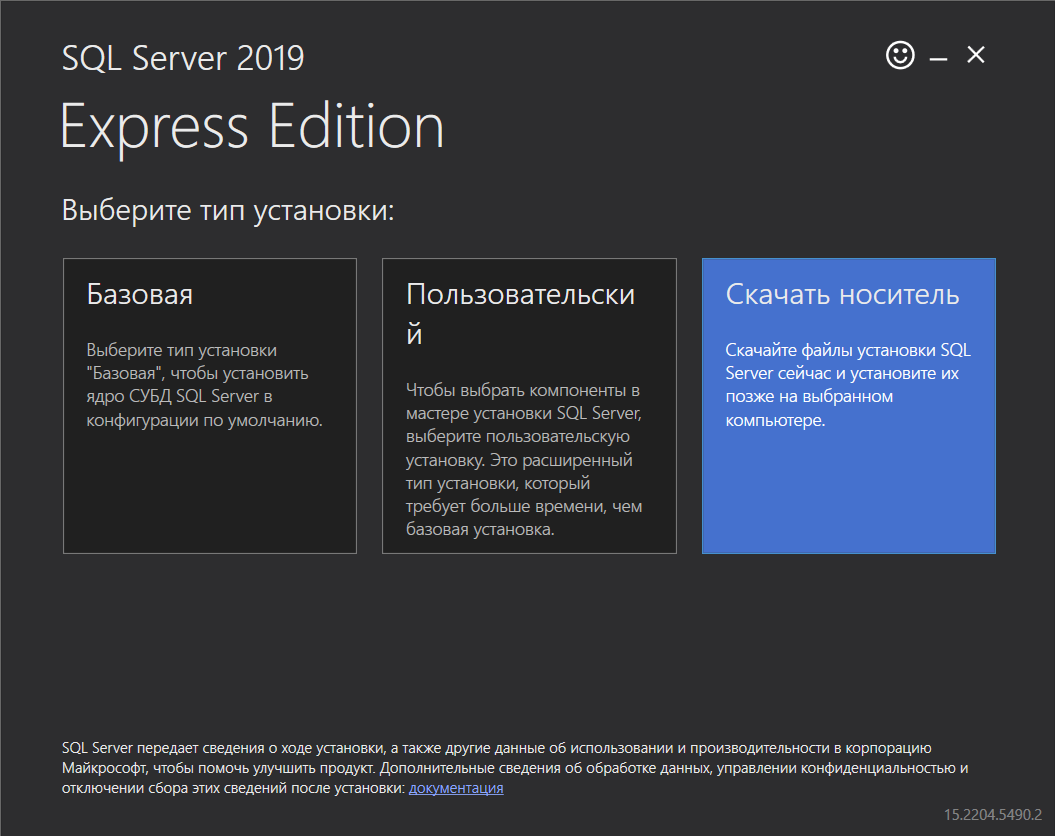
Выбор варианта установки SQL Server
2. Выберите язык и укажите папку для хранения установочных файлов,. Язык должен соответствовать языку операционной системы Windows Server 2016. Нажмите кнопку Скачать .
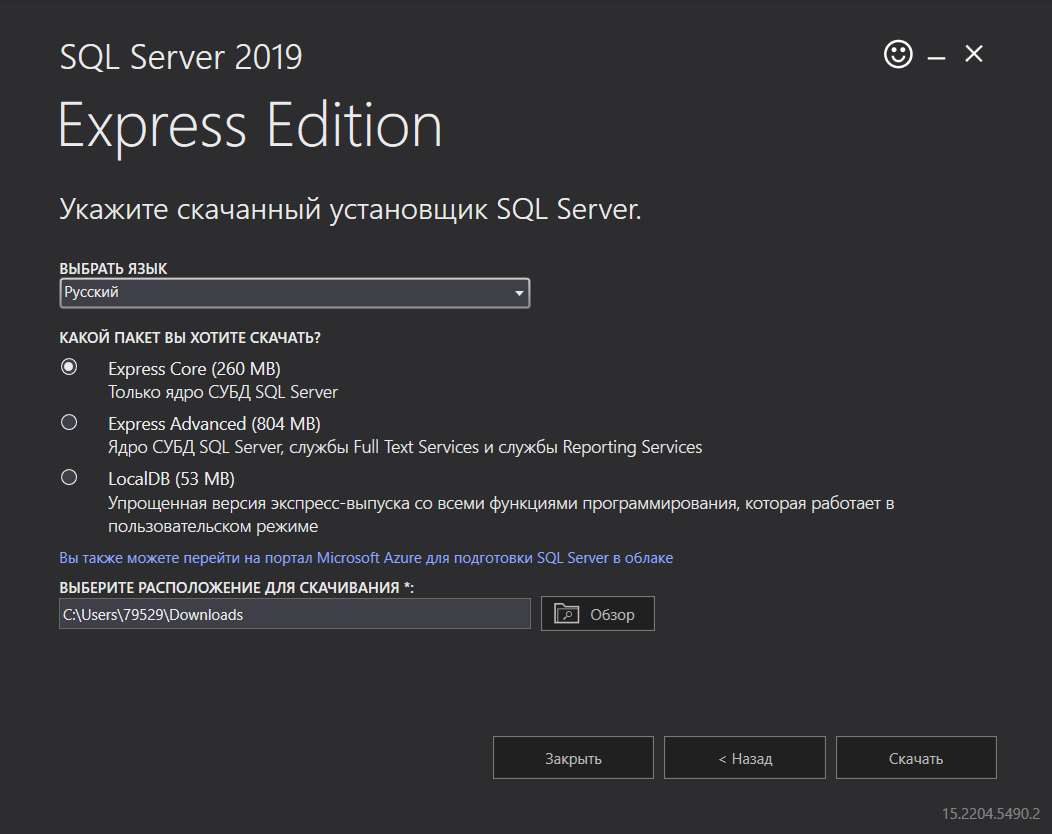
Выбор языка и расположения SQL Server
Начнется процесс загрузки дистрибутива по указанному расположению.
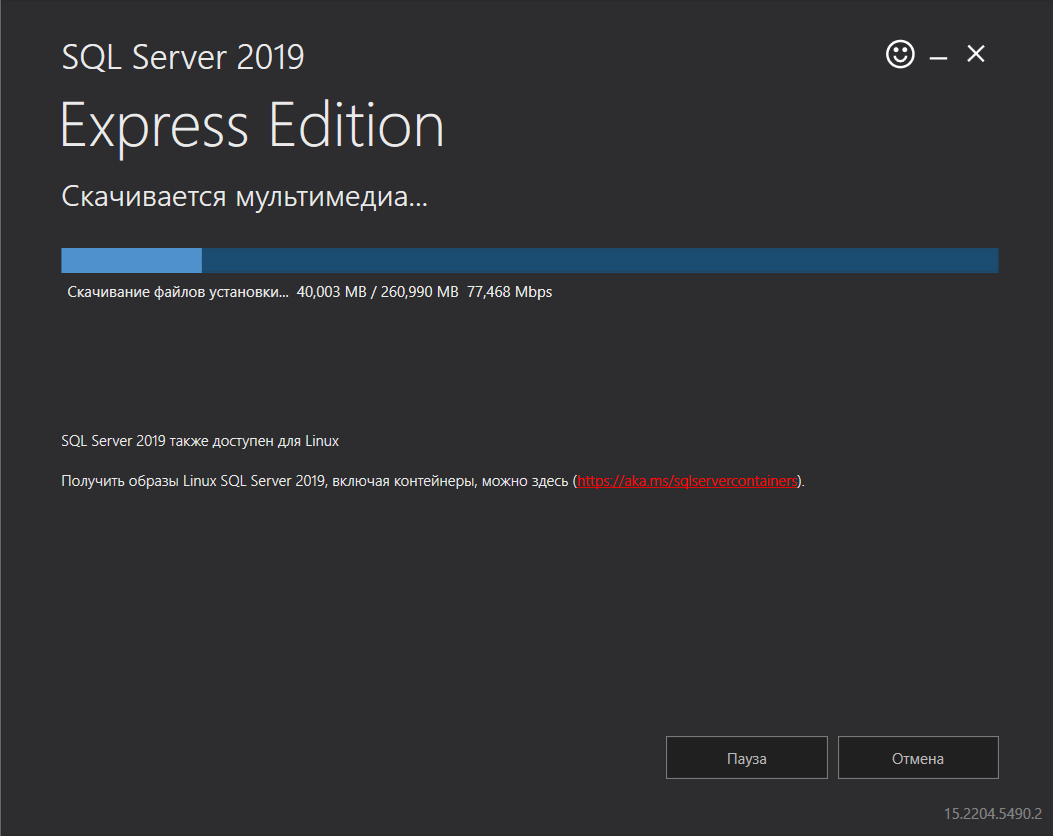
Скачивание файлов установки
З. 3апустите скачанный EXE файл из папки, указанной на предыдущем шаге — вы можете перейти в нее из установщика по кнопке Открыть папку .
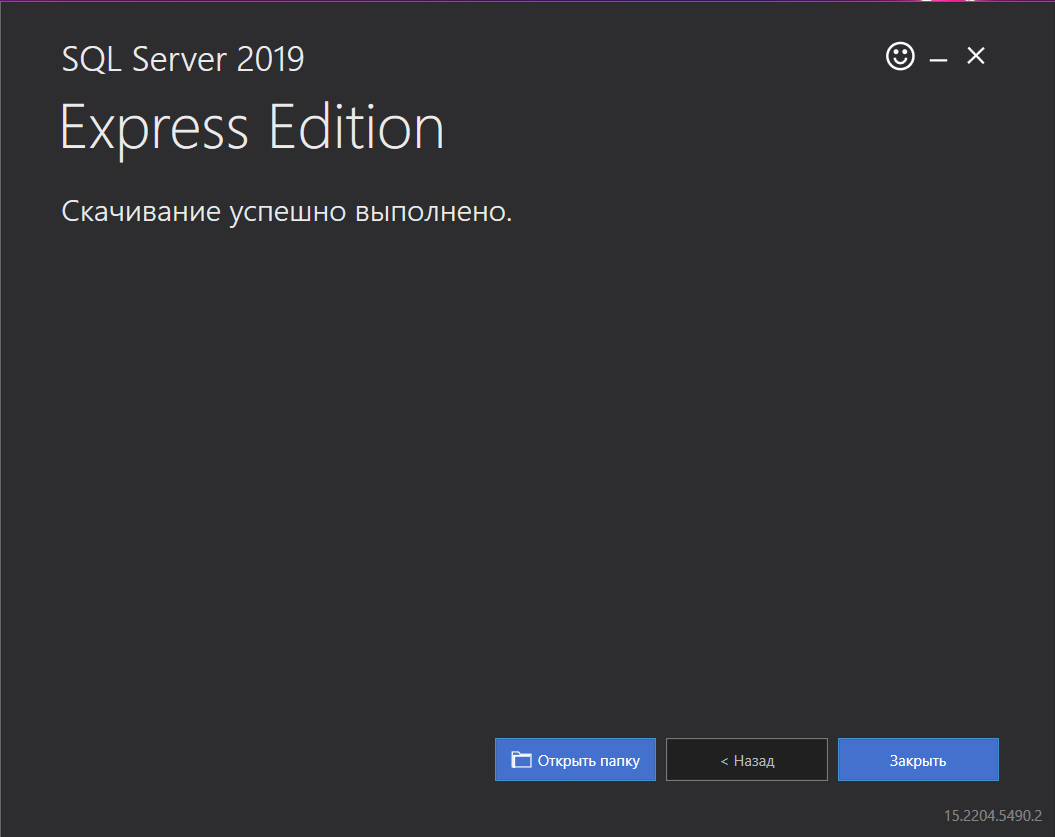
Сообщение об успешном скачивании, переход в папку установки по кнопке
4. Выберите каталог для извлекаемых файлов.
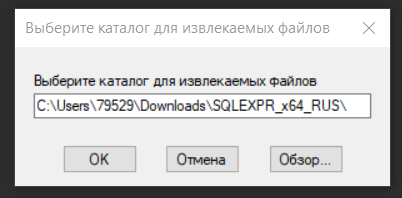
Выбор каталога для извлекаемых файлов
5. После извлечения файлов откроется центр установки SQL Server 2019. Перейдите в раздел Установка (Installation) и выберите пункт Новая установка изолированного экземпляра SQL Server или добавление компонентов к существующей установке (New SQL Server stand-alone installation or add features to an existing installation).
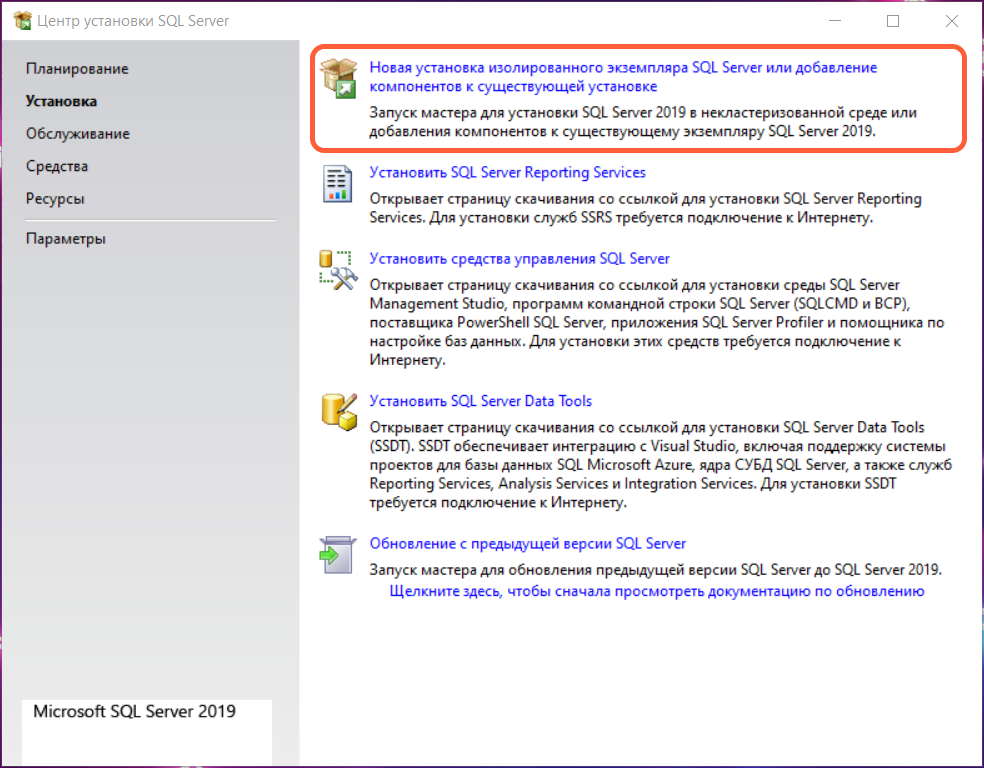
Центр установки SQL Server 2019
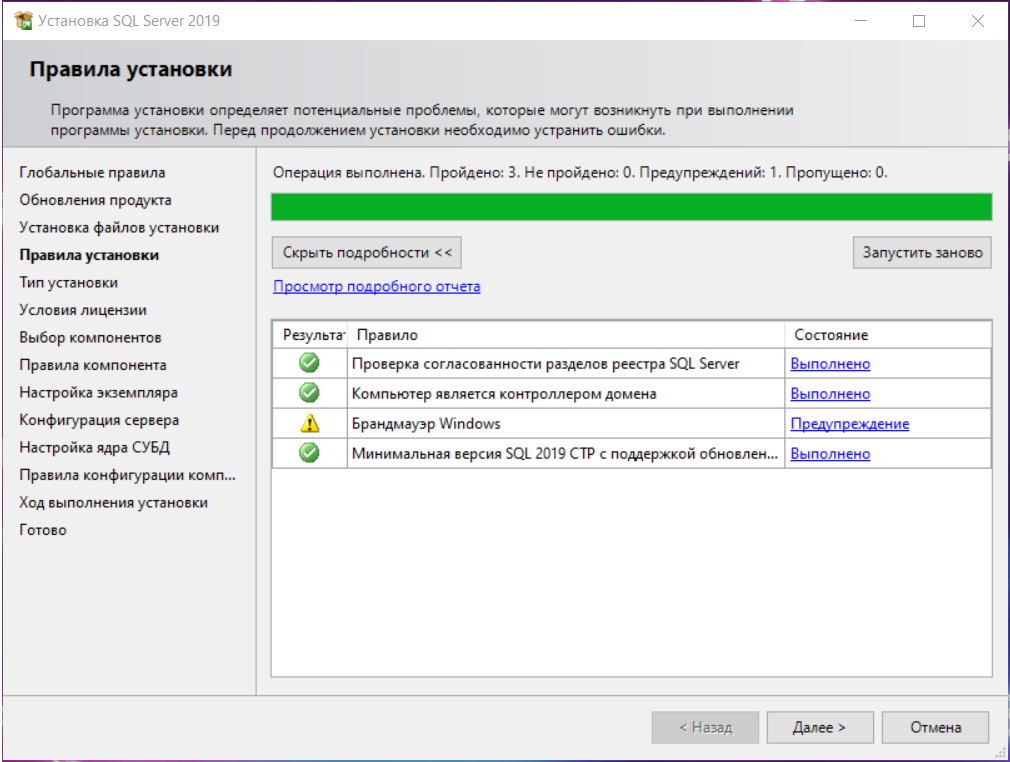
6. Программа установки определит потенциальные проблемы, которые могут возникнуть при выполнении установки. Нажмите Далее .
7. Выберите тип установки. При первой установке выберите пункт Выполнить новую установку SQL Server 2019 .
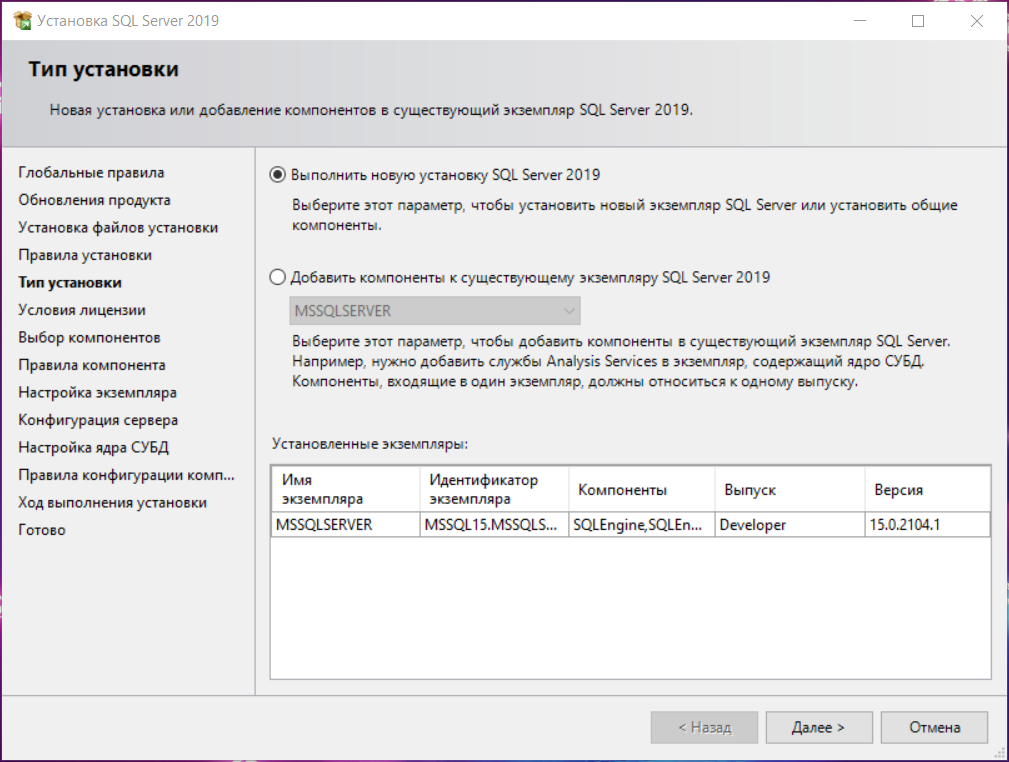
Выбор типа установки
8. После прочтения необходимо принять лицензионное соглашение и нажать кнопку Далее .
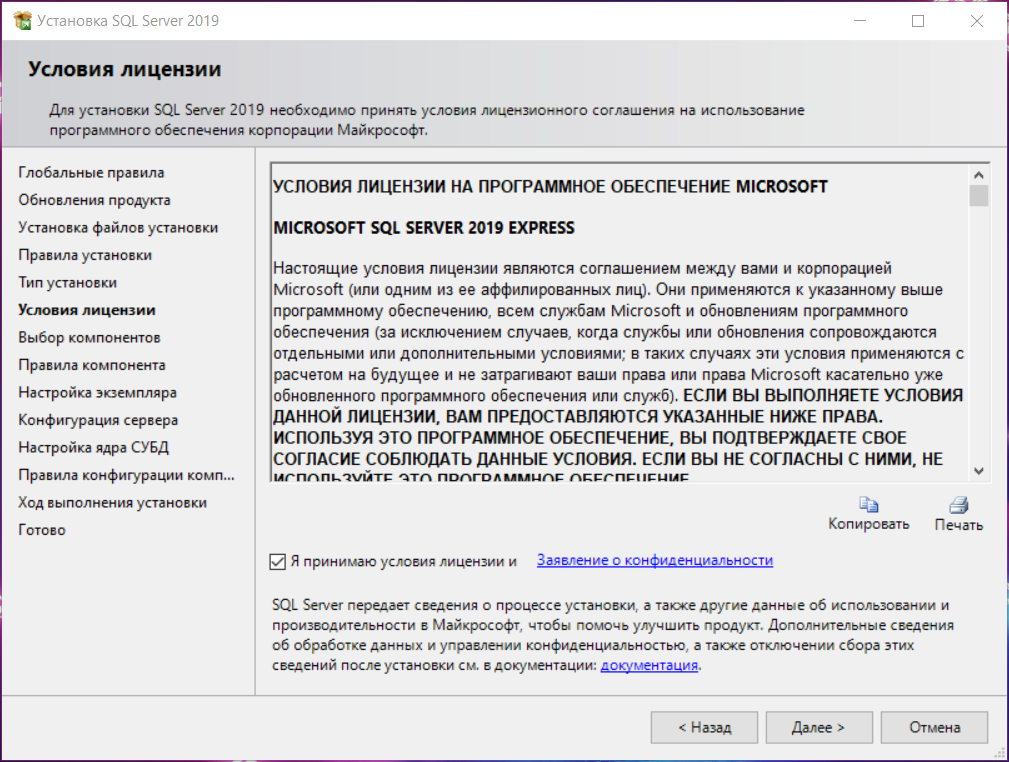
9. Установите нужные компоненты.
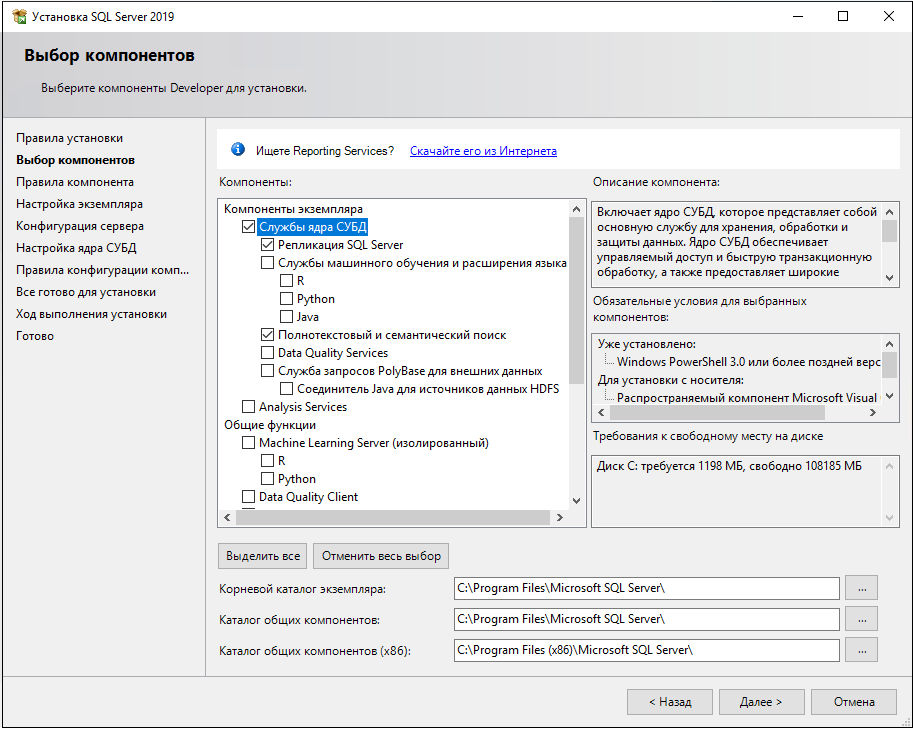
Обязателен к установке
Database Engine Services
Основной движок SQL Server. Включает ядро СУБД, которое представляет собой основную службу для хранения, обработки и защиты данных. Ядро СУБД обеспечивает управляемый доступ и быструю транзакционную обработку.
SQL Server Replication
Службы репликации. Включает набор технологий для копирования и распространения данных и объектов баз данных из одной базы данных в другую и синхронизации этих данных между базами данных для согласованности. С помощью репликации можно распространять данные по разным узлам, а также удаленным и мобильным пользователям по локальным или глобальным сетям, коммутируемым соединениям, беспроводным соединениям и через Интернет.
Machine Learning Services and Language Extensions
Службы для выполнения R/Python/Java кода в контексте SQL Server
Full-Text and Semantic Extractions for Search
Полнотекстовая технология поиска или семантический поиск в документах (например docx).
Data Quality Services
Службы для коррекции и валидации данных
PolyBase Query Service For External Data
Технология для доступа к внешним данным, например на другом SQL Server или в Oracle Database.
Технология для бизнес-отчетов (BI) и работы с OLAP.
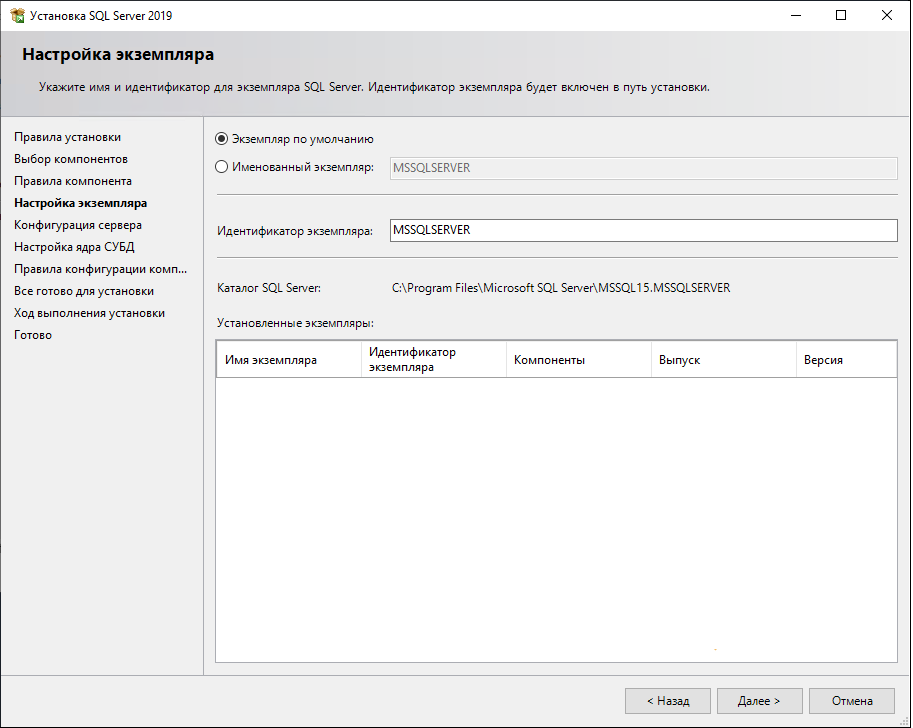
10. В настройка экземпляра выберите экземпляр по умолчанию, т.к. это будет единственный экземпляр сервера.
11. Настройте запуск от имени системы. Во вкладке Параметры сортировки проверьте, чтобы была установлена сортировка Cyrillic_General_CI_AS для Database Engine , т.к. она задается только при установке и для ее изменения в дальнейшем потребуется переустанавливать сервер.
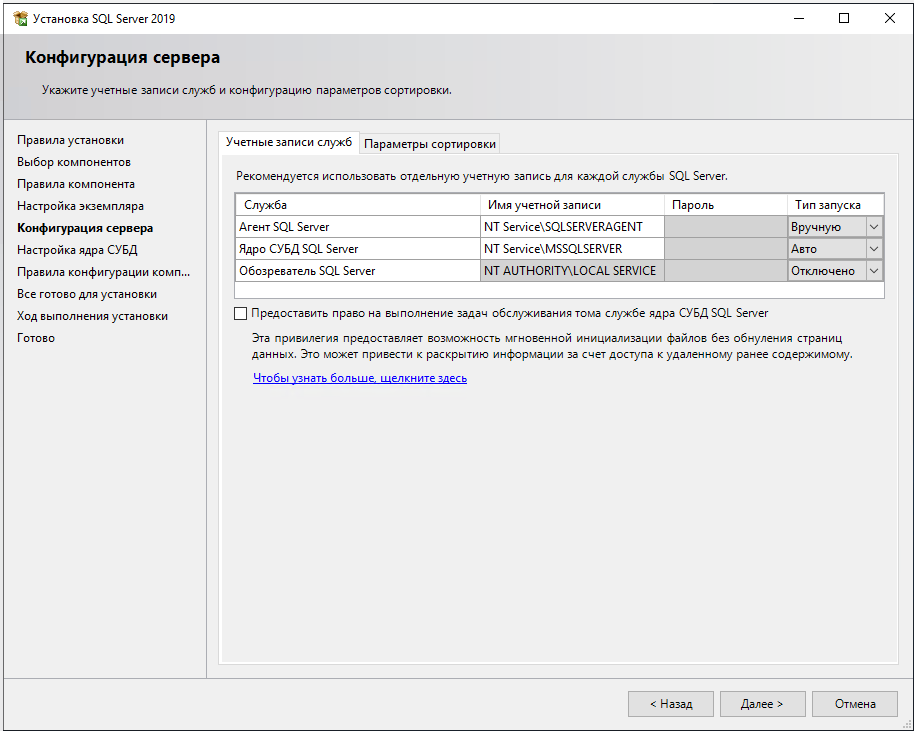
Настройка параметров запуска
12. Установите авторизацию в смешанный режим. Добавьте текущего пользователя в администраторы SQL сервера.
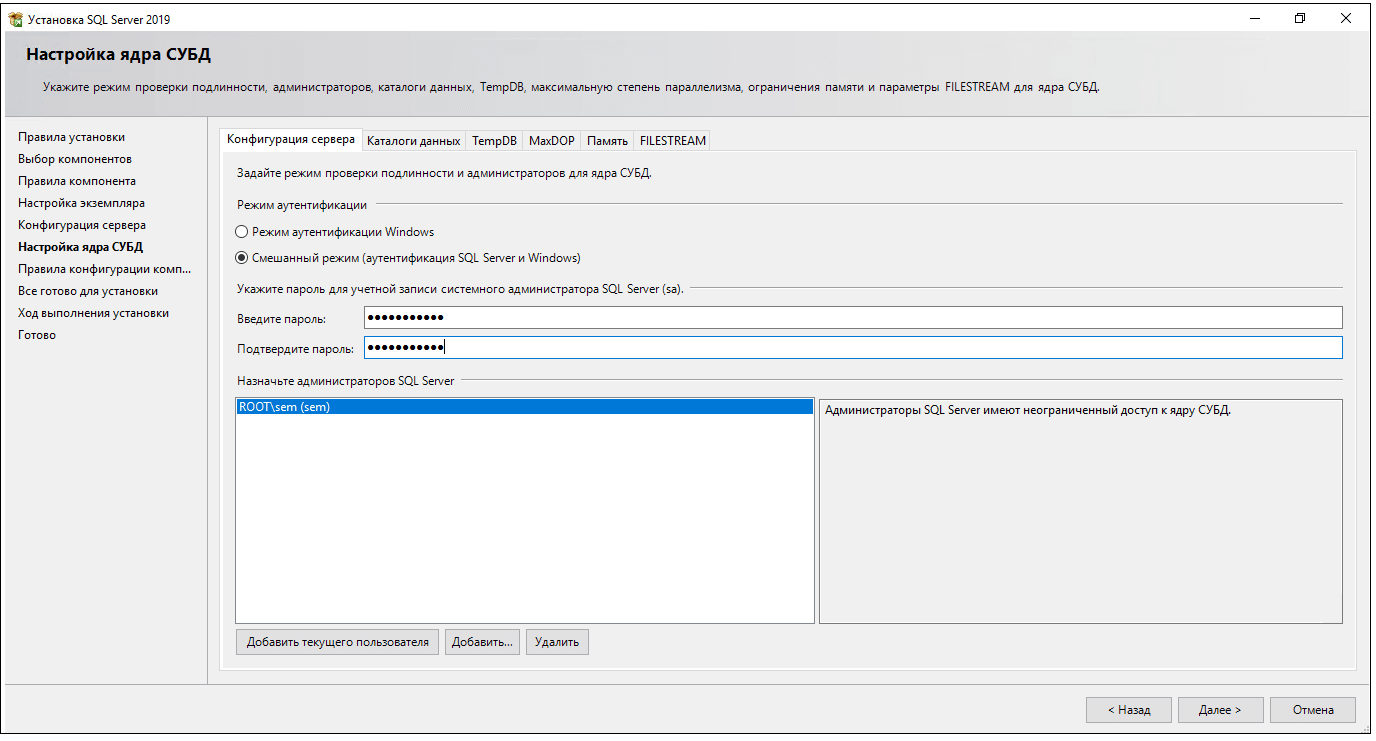
Выбор режима авторизации и добавление администратора
На данном шаге можно также заполнить вкладку TempDB , указав количество баз, чтобы позже не настраивать это вручную.
13. Во вкладке Каталог данных укажите путь к папке, где будут размещаться файлы баз данных (рекомендуется использовать отдельный от ОС физический диск) в поле Корневой каталог данных .
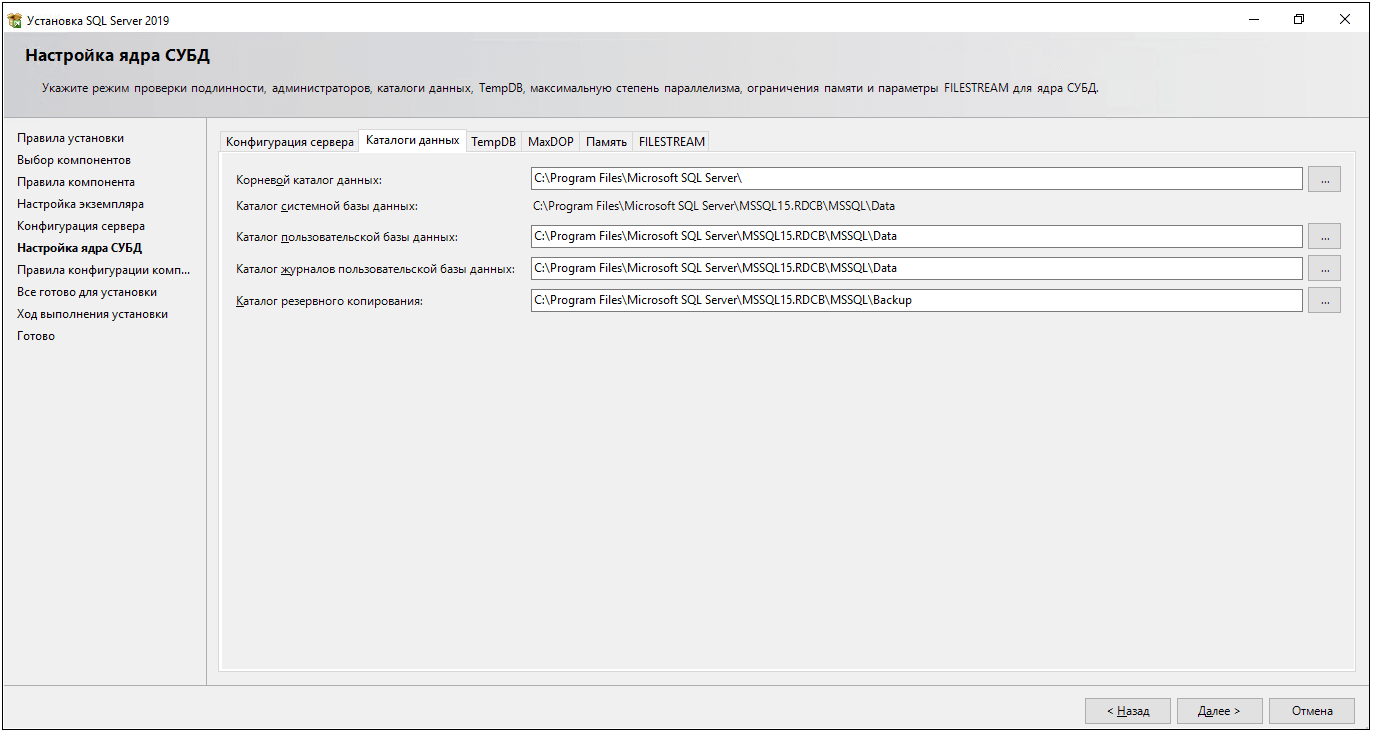
Дождитесь завершения установки.
Настройка SQL Management Studio
1. Откройте SQL Management Studio и в свойствах сервера измените значение параметра Максимальная степень параллелизма на 4. Этот параметр регулирует работу с процессорными ядрами, которые сервер может привлекать на обработку запроса. В параметре Оптимизировать для нерегламентированной рабочей нагрузки установите True .
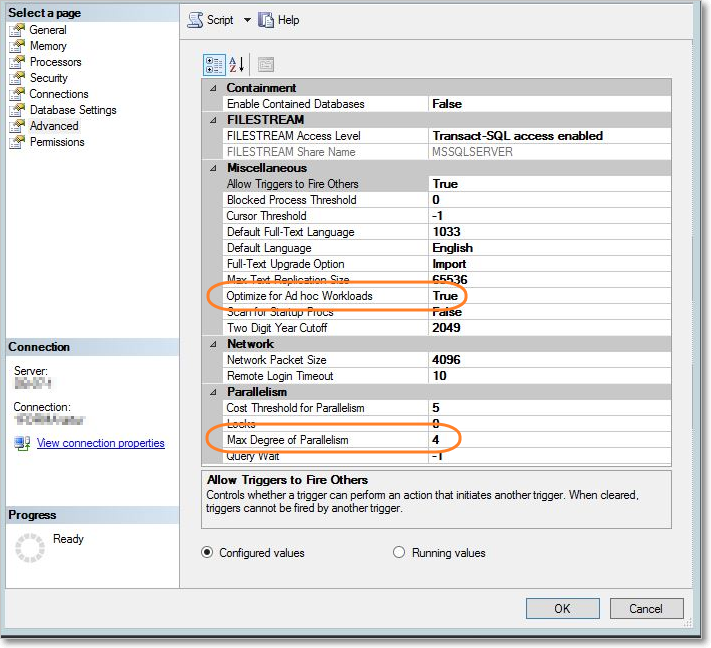
Установка параметров SQL MS
2. По умолчанию удаленный доступ к серверу может быть закрыт, поэтому нужно разрешить подключение.
Запустите утилиту Диспетчер конфигурации SQL Server (Пуск — Все программы — Microsoft SQL Server 2019 — Средства настройки — Диспетчер конфигурации SQL Server).
В разделе Сетевая конфигурация SQL Server — Протоколы для . для строки TCP/IP вызовите контекстное меню (правой кнопкой мыши) и выберите пункт Свойства .
На вкладке Протокол установите параметр Включено в значение Да , а на закладке IP-адреса в ветке IPAll установите параметр TCP-порт в значение 1433 . Затем нажмите ОК .
Аналогичным способом настоятельно рекомендуем отключить все остальные протоколы, кроме TCP/IP.
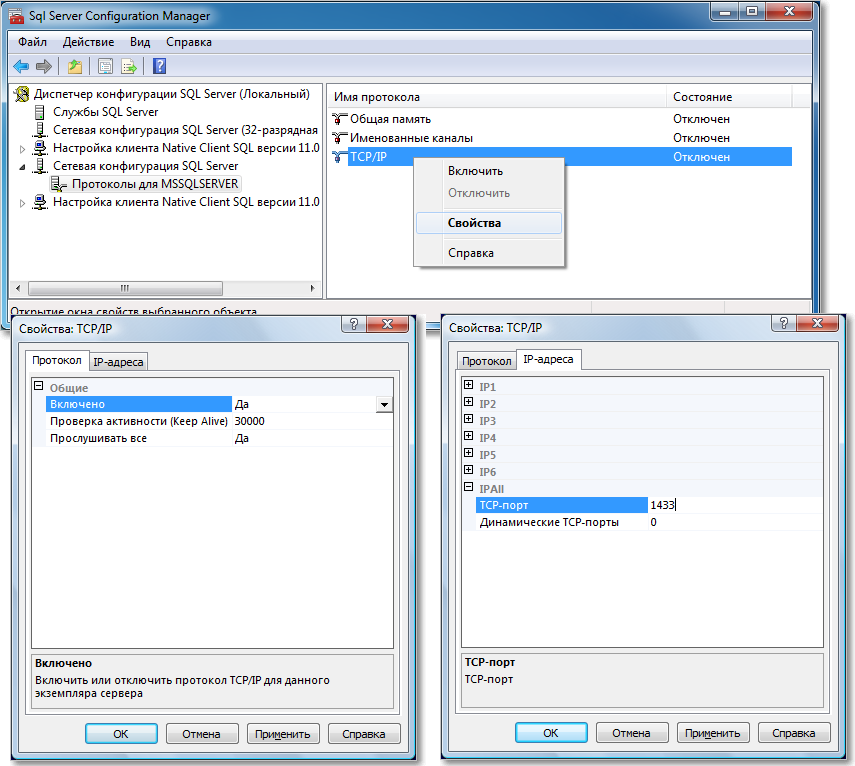
Настройка сетевых протоколов
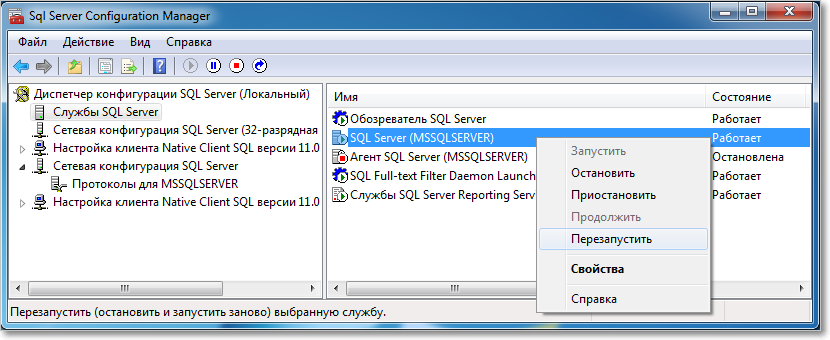
3. В разделе Службы SQL Server для строки SQL Server (…) вызовите контекстное меню (правой кнопкой мыши) и выберите пункт Перезапустить (этот пункт можно пропустить, если Вы перезагрузите компьютер после завершения остальных настроек):
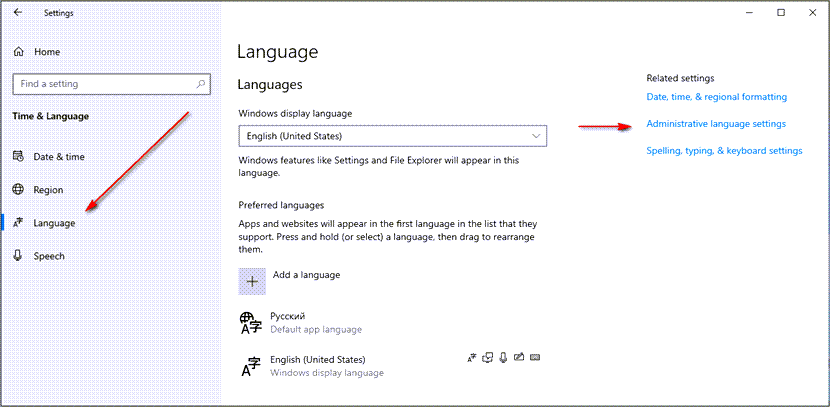
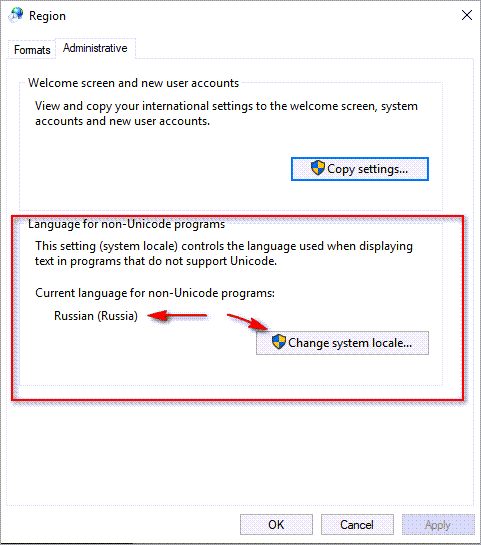
4. Если вы устанавливаете SQL Server на НЕ русскоязычную ОС Windows, после окончания установки на сервере откройте панель управления ( Control Panel ), перейдите в раздел Time & Language , затем в раздел Language и нажмите на ссылку Administrative language settings . Нажмите кнопку Change system locale , для Language for non-Unicode programs выберите язык Russian и снова перезагрузите компьютер.
На этом подготовка SQL Server 2019 к установке «Первой Формы» завершена.
С чем кушать Irregular Selectivity в MSSQL и не только
Недавно мне пришлось объяснять это нашим братьям меньшим на работе, и я решил написать текст, который может пригодиться. В конце вы найдете ссылку на полезный скрипт для MSSQL, а также Postgres и MySQL. Если тема вам знакома, перематывайте к последней главе.
В идеальном мире, если в таблице миллион записей, а разных значений например, 100K, то на каждое значение приходится по 10 записей. Но что делать, если в список ваших значений затесалось особое значение, например, NULL, пробел или ‘n/a’? Для SQL optimizier это головная боль. Для вас тоже.
Как такие значения вообще образуются?
Выделю пять причин (может, вы знаете больше?)
Такова жизнь — n/a, пустая строка итд. Те же нелегальные иммигранты, у которых нет SSN.
Умолчание. По своей сути мало отличается от предыдущего пункта
Кит и рыбешка. Часто бывает что большинство операций относится к одному отделу, фирме, пользователю итд.
Следствие роста. Мы завели в базе ‘department id’ на будущее, когда будет много отделов, но очень долго был только один, и только вот стали появляться другие
Искусcтвенно сгенеренные данные. Чаще всего бывает при генерации данных для базы в DEV при лени разработчиков. Это потом аукнется на PROD.
Наиболее проблемными являются случаи кит и рыбешка и следствие роста, которые похожи друг на друга. Мы, как покажем ниже, можем сделать ветку для ‘n/a’, но категорически не хочется делать hardcode id ‘кита’ в коде, тем более, что в разных инсталляциях продукта для разных клиентов статистики могут быть совершенно разными.
Сделаем демо пример
create table Unlucky ( n int identity primary key, VAL varchar(32), somethingElse varchar(128)) GO set nocount on declare @n int=1000000 while @n>0 begin set @n=@n-1 insert into Unlucky select convert(varchar,@n/10)+'val', convert(varchar,@n)+convert(varchar,@n) +convert(varchar,@n)+convert(varchar,@n) end GO update Unlucky set VAL='n/a' where n%2=1 GO create index VAL on Unlucky (val) GOВ табличке миллион записей, но половина имеет val=’n/a’, для остальных записей у нас 5 записей на значение:

Потестируем

Как и ожидалось, SQL server достаточно умный и использует статистики для получения оптимального плана. Но давайте погрузим все это в процедуру:
create procedure GetVal @val varchar(32) as select * from Unlucky where val=@val GO
Пока все выглядит прeкрасно, потому что SQL server способен проверить значение параметра, когда значение передается явно, как константа. Это называется parameter sniffing.
А теперь о грустном.
Но parameter sniffing легко запутать.

И вот уже в обоих случаях используется index seek. А если первой вызовется процедура с n/a:

То есть кто первым встал, того и тапки. После перезапуска SQL server, после изменения статистики или в произвольный момент времени план SQL server может ‘застрять’ в ‘неправильном’ положении. Приходится хвататься за молоток freeproccache. Такая ситуация называется poisoned execution plan.
И как с этим бороться?
Первый подход в кодировании отдельной ветки для особого значения или значений:
create procedure SmartGetVal @val varchar(32) as if @val='n/a' select * from Unlucky where val='n/a' -- not @val. else select * from Unlucky where val=@val GOВторой подход заключается в использовании динамического SQL:
create procedure DynGetVal @val varchar(32) as declare @sql varchar(1000) set @sql='select * from Unlucky where val='''+@val+'''' exec(@sql) GOВторой подход надо использовать с осторожностью (SQL injection, возможные проблемы с правами на таблицы итд), С другой стороны для OLAP/Reporting систем построение длинного запроса может быть куда более эффективным, если количество вариантов указан параметр или нет велико. Кроме того, это позволяет использовать индекс с WHERE (см. ниже)
И уж точно это лучше любимого приема девелоперов, проклинаемого всеми DBA:
where . and (@userid IS NULL or userid=@userid) and (@companyid IS NULL or companyid=@companyid) and (@deptid IS NULL or deptid=@deptid) 
Также обратите внимание на query hints OPTION(RECOMPILE) — это может подойти для простых кверей но тратить 100-500ms на компиляцию длинных каждый раз не стоит.
Также обратите внимание на хинты OPTION(OPTIMIZE FOR UNKNOWN) и OPTION (OPTIMIZE FOR @var=value. )
Также имеет смысл создать индекс, который не содержит частых значений:
drop index Unlucky.VAL create index VAL on Unlucky (val) where val<>'n/a'Но увы — процедура SmartGetVal прекратит работать оптимально, во второй ветке SQL не понимает, что можно использовать индекс, так как в@valточно нет значения ‘n/a’, и заставить его это сделать невозможно:
alter procedure SmartGetVal @val varchar(32) as if @val='n/a' select * from Unlucky where val='n/a' -- not @val. else select * from Unlucky with (index=val) where val=@val GO Процедура создасться нормально но потом получим:
Msg 8622, Level 16, State 1, Procedure SmartGetVal, Line 5 [Batch Start Line 47]
Query processor could not produce a query plan because of the hints defined in this query. Resubmit the query without specifying any hints and without using SET FORCEPLAN.
Без HINT вторая ветка будет использовать table scan. Динамический SQL же будет работать оптимально.
Полезные скрипты для обнаружения irregular selectivity
Для MS SQL предлагаю скрипт, который пройдет по всем целым и строковым (не очень длинным) колонкам и представит selectivity report:

Первые колонки в комментариях не нуждаются, предпоследняя рассчитывается так: выбираем самое частое значение и смотрим, сколько на него приходится записей. Последняя колонка — то же самое в процентах. Если вы видите числа более 30%, то это кандидат на проблему.
Вы также увидите колонки с малой селективностью, которые индексировать, вероятно, не стоит.
Вас наверное удивляет, что результат выглядит как HTML таблица? Потому что это часть большого проекта. Впрочем, для MSSQL вы можете использовать скрипт отдельно.
‘standalone’ скрипт для MSSQL, измените имя таблицы в первой строке
declare @tab varchar(128) = 'tablename' declare @s varchar(128), @sql varchar(max), @rows bigint select @rows=max(rowcnt) from sysindexes where @rows=0 set @rows=1 create table #res (s varchar(128), cnt int) create table #tp (s varchar(128), topper int) DECLARE cols CURSOR FOR select name from syscolumns where and xtype in (48,52,56,127,167,231,239,175,108) and length Для Postgre и MySQL есть версии в самих модулях, скачайте их по ссылкам и ищите файл с именем *selectivity. , равно как и для MSSQL
Настройка связи с MS SQL
r_keeper_7 можно связать только с MS SQL версии 2012 и выше. В статье рассмотрена настройка связи с MS SQL 2012.
Установка SQL сервера
Для установки SQL сервера:
-
Установите MS SQL Server 2012 или выше. Можно использовать выпуск Express.
Во время установки сервера используйте смешанный режим аутентификации и задайте пароль для пользователя — sa
- Раскройте ветку Сетевая конфигурация SQL Server.
- Выберите Протоколы MSSQLSERVER.
- Дважды нажмите по строке TCP/IP.
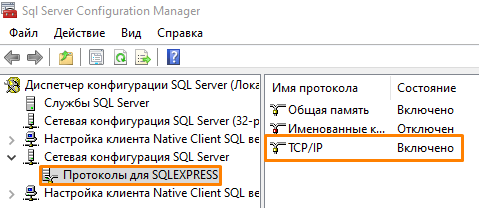
- В открывшемся окне на вкладке Протокол включите поле Включено.
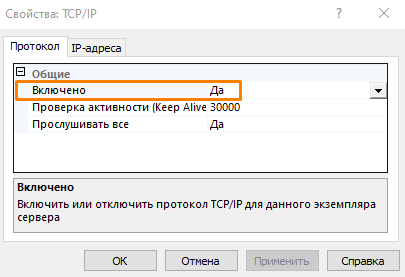
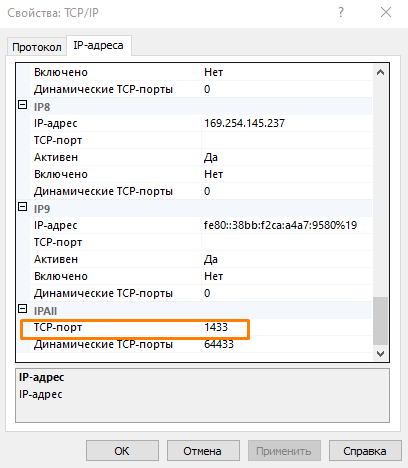
- Убедитесь, что во вкладке IP-адреса в блоке IPAll указан порт. По умолчанию порт 1433, но вы можете указать любой свободный порт.
- Перезапустите SQL Server.
Режим версионности строк
Вы можете перевести базу в режим версионности строк — Row Versioning. Это необязательный режим, поэтому эту настройку можно пропустить.
По умолчанию SQL Server работает в режиме Read Commited, который подразумевает блокирование данных во время запроса. Это может сильно помешать в случае многопользовательской работы. Начиная с версии 2005, поддерживается режим READ COMMITTED using row versioning. В этом режиме блокировки могут помешать только в том случае, когда разные пользователи пишут в одно и то же место,. Чтение данных никогда не блокируется и никого не блокирует.
Для включения режима версионности строк выполните скрипт:
ALTER DATABASE RK7 SET READ_COMMITTED_SNAPSHOT ON;Восстановление базы данных из резервной копии
Вы можете восстановить базу данных из резервной копии:
- Запустите MS SQL Server Management Studio и пройдите авторизацию
- Слева в окне Обозреватель объектов выделите группу Базы данных
- Вызовите контекстное меню правой кнопкой мыши и выберите пункт Восстановить базу данных
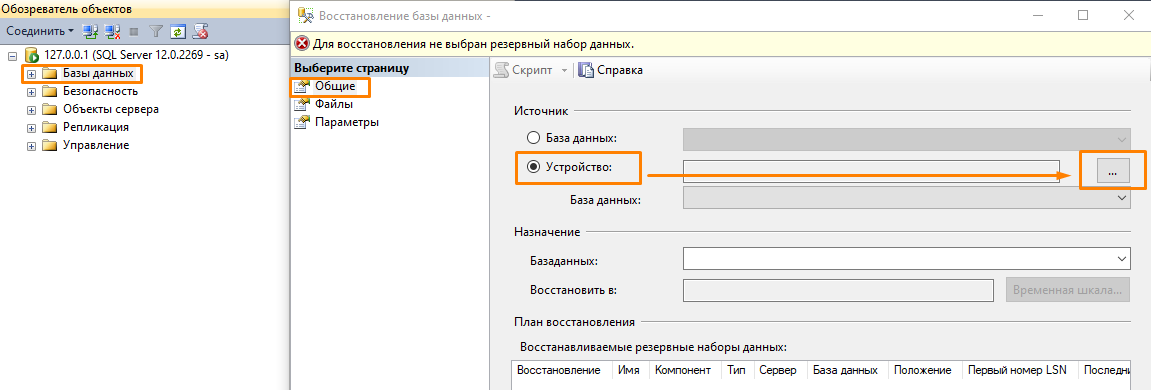
- В открывшемся окне в разделе Общие укажите источник Устройство, а затем нажмите кнопку с тремя точками.
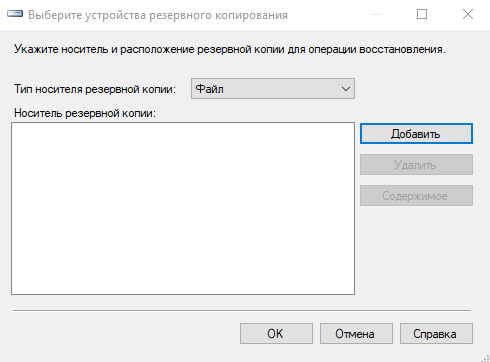
- Выберите тип носителя Файл и нажмите кнопку Добавить.
- Укажите путь к файлу и нажмите ОК.
- Проверьте базу на ошибки, нажав кнопку Проверка носителя резервной копии, и затем нажмите ОК.
- Дождитесь восстановления базы. После успешного восстановления система сообщит о завершении процесса:
Готово. База появится в списке баз данных.
Настройки в менед жерской станции
Чтобы настроить станцию, выполните следующие действия:
- Зайдите в справочник Сервис > Экспорт данных > Настройки Внешних БД и сделайте копию предустановленной настройки «Microsoft SQL Server». Присвойте ей уникальное имя и смените статус настройки на Активный.
- В по ле Осн овное > Строка соединения нажмите на кнопку в конце строки или дважды нажмите на по ле ввода.
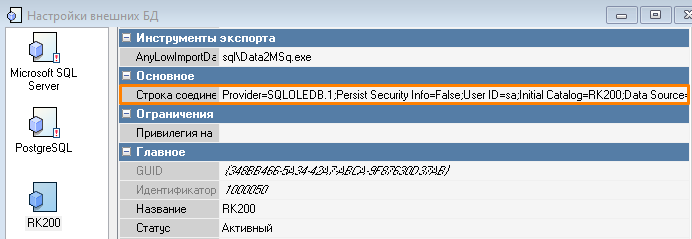
- Откроется окно ConnectionString. Нажмите кнопку Build.
- Откроется окно Свойства канала передачи данных. Н астройте связь с базой данных, созданной ранее:
- Перейдите во вкладку Поставщик данных и убедитесь, что выбран Microsoft OLE DB Provider for SQL Server.
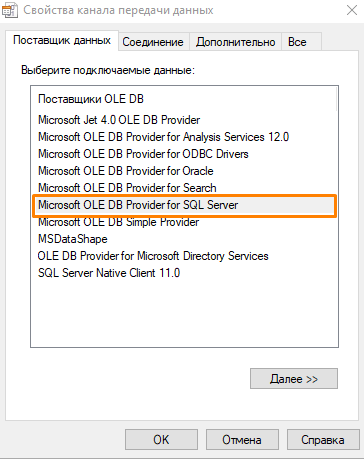
- Во вкладке Соединение выберите сервер из списка, введите имя пользователя и пароль. Если нужного сервера нет в списке, то необходимо вручную ввести его имя.
Если SQL-север установлен на том же компьютере, что и сервер справочников или отчетов, укажите адрес 127.0.0.1. Если на другом — укажите его IP-адрес и убедитесь, что сервер доступен по сети.
Имя сервера также можно посмотреть при запуске SQL Server Management Studio.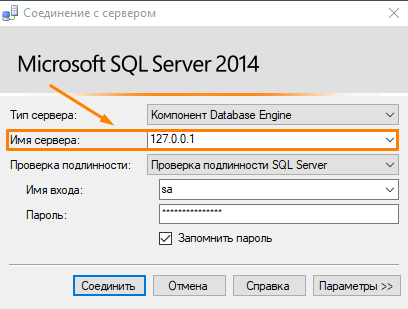 Введите имя пользователя и пароль. Выберите базу данных на сервере и нажмите Проверить подключение.
Введите имя пользователя и пароль. Выберите базу данных на сервере и нажмите Проверить подключение. - Если проверка соединения прошла успешно, то нажмите ОК.
- В окне Свойства канала передачи данных нажмите ОК. Поле Строка соединения примет вид:
Provider=SQLOLEDB.1;Password=[пароль];Persist Security Info=True;User Catalog=[имя базы];Data Source=[имя сервера или IP-адрес].Выполните выгрузку в БД SQL, используя созданную настройку:
- Перейдите в меню Сервис > Экспорт данных > Экспорт в другую БД.
- В поле Параметры соединения выберите созданную настройку.
- Укажите Имя пользователя и Пароль.
- В блоке Параметры экспорта оставьте флаги по умолчанию, если выгрузка происходит в чистую БД SQL.
- Нажмите Проверить.
- При удачном соединении кнопка ОК станет активной, нажмите ее. Запустится экспорт данных в БД SQL. В этот момент в SQL создаются таблицы.
При успешной выгрузке окно с настройками экспорта данных закроется. Появится сообщение Экспорт завершен успешно.
Далее необходимо настроить сервер справочников, пролицензировав его и выбрав созданную настройку. Для этого:
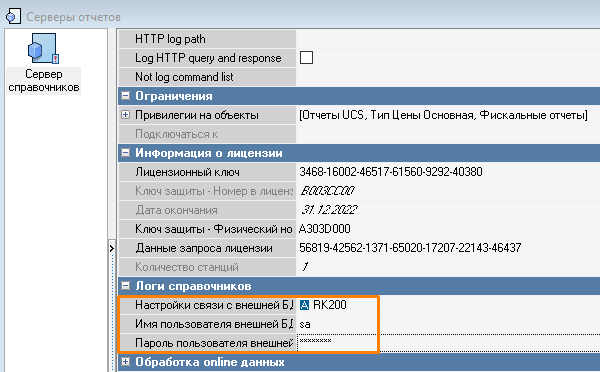
- Перейдите в меню Настройки > OLAP Отчеты > Серверы Отчетов , выберите нужный сервер и настройте его:
- Пролицензируйте сервер справочников/отчетов согласно описанию в статье настройка сервера справочников.
- В группе Связь с внешней БД :
- В поле Настройки связи с внешней БД выберите созданную настройку.
- В поле Имя пользователя внешней БД пропишите имя пользователя БД SQL.
- В поле Пароль пользователя внешней БД прописать пароль пользователя БД SQL.
- Укажите такие же настройке в группе Логи справочников :
- В поле Настройки связи с внешней БД выберите созданную настройку.
- В поле Имя пользователя внешней БД пропишите имя пользователя БД SQL.
- В поле Пароль пользователя внешней БД пропишите пароль пользователя БД SQL.
- В группе Основное сделать следующее:
- В поле Источник данных кубов выберите параметр БД SQL.
- В поле Протоколирование запросов выберите подходящий параметр:
- llAll протоколировать все запросы
- llErroneous протоколировать запросы с ошибками
- llNone — не протоколировать
- В поле Режим базы данных UDB выберите один из режимов: большой, средний, маленький, ультра легкий. Данный режим относиться к накопительной базе Check.udb.
- Большой — полная копия. Это режим по умолчанию. Используется для простых ресторанов, не сетевых. Не меняйте параметр Полная копия на другое, пока не настроите соединение с внешней базой данных.
- Средний — частичная копия. Режим означает, что кроме данных заказов, все суммы будут сохраняется в check.udb.
- Маленький — только чеки. Режим используется, если вы уверены, что будет иметься достаточно много накопительных данных — несколько ресторанов. В большинстве случаев рекомендуется использовать этот режим, чтобы база не становилась слишком большой.
- Ультралегкий — только общие смены. В check.udb будет содержаться только информация об общих сменах и ссылки на них в базе SQL.
Если вы решили изменить Режим базы данных UDB с большого на маленький при настроенной связи с SQL, то есть ресторан проработал в таком режиме уже продолжительное время, и выполнить ручной экспорт накопительных данных повторно, то размер файла Check.udb автоматически уменьшится. В результате большая часть информации из этой базы будет удалена, и в базу SQL экспортируются не все данные. Поэтому никогда не делайте экспорт накопительных данных, если вы используете режим базы данных UDB Маленький или Средний.
Выбранный режим базы данных UDB никак не влияет на справочную информацию. Справочная информация всегда сохраняется на каждом сервере отчетов в полном объеме и может быть экспортирована повторно при необходимости.
- В секции Обработка данных выберите ресторан, данные с которых нужно собирать и видеть в отчетах.
- В конфиг урационном файле сервера справочников rk7srv.INI и в файле сервера отчетов repsserv.ini пропишите параметр UseSQL=1 .
- Д ля сервера справочников параметр необходимо прописать в секции [RefServer]
- Для сервера отчетов — в секции [Config].
- Д ля сервера справочников параметр необходимо прописать в секции [RefServer]
- Перезагрузите сервер справочников и сервер отчетов.
Все изменения в настройках внешней БД происходят во время работы сервера при параметре UseSQL=0.
Если необходимо поменять настройки внешней БД:
- Остановите все серверы отчетов и сервер справочников, которые используют эту настройку.
- В конфигурационном файле сервера справочников rk7srv.INI или сервера отчетов repsserv.ini пропишите параметр UseSQL=0.
- Запустите нужный сервер.
- Поменяйте настройки.
- Вновь остановите сервер.
- В конфигурационном файле верните параметру UseSQL значение 1 — UseSQL=1.
Готово, мож но продолжать р аботу.
Одновременно для нескольких ролей в r_keeper нельзя сделать связь с БД в SQL Server используя одного и того же пользователя в БД SQL. В r_keeper не сохранится информация о пользователе в настройках связи с внешней БД.
Оптимизация производительности
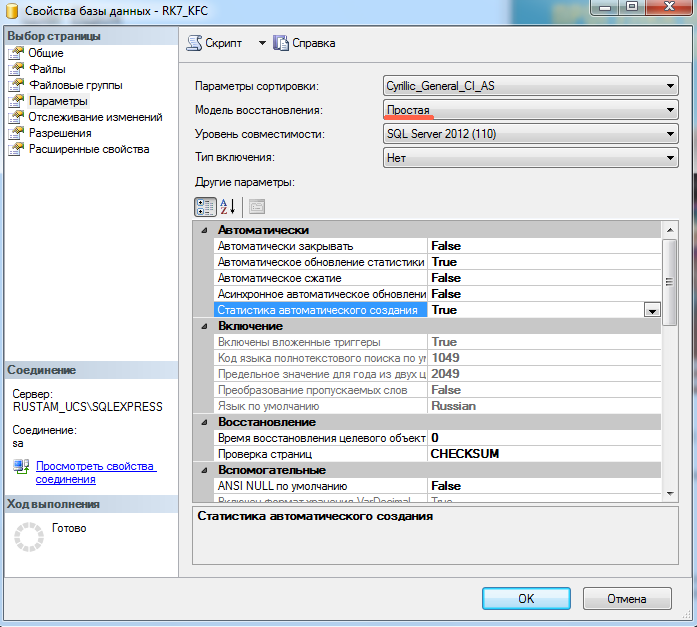
В целях экономии дискового пространства и некоторого увеличения производительности рекомендуется использовать Простую — Simple модель восстановления.
Ознакомиться с различными моделями восстановления SQL, их различиями и особенностями вы можете в официальной документации Microsoft.После изменения модели восстановления необходимо выполнить сжатие файла лога. Для этого:
- Нажмите правой кнопкой мыши на используемую базу данных
- Выберите Задачи >Сжать >Файлы
- В открывшемся окне выберите тип файла Журнал
- Нажмите на кнопку ОК.
Возможные проблемы
Проблема: Иногда может не идти экспорт в только что созданную БД сервера SQL Server 2008 при выбранном провайдере Native Client.
Решение: Выберите другой провайдер Microsoft OLE DB Provider for SQL Server, создайте заново чистую БД и повторите экспорт.Проблема: Не строятся прямые отчеты
Решение: Если у роли отличаются права доступа на просмотр отчетов на разные объекты, то для построения прямых отчетов необходимо завести разных пользователей на SQL сервере. Затем настройте роли с такими пользователями в SQL. Для этого:- В менеджерской станции r_keeper перейдите в меню Персонал > Работники
- Выберите роль, которой хотите предоставить доступ, и перейдите в ее Свойства
- Раскройте раздел Связь с внешней БД и дважды нажмите на поле SQL конфигурация
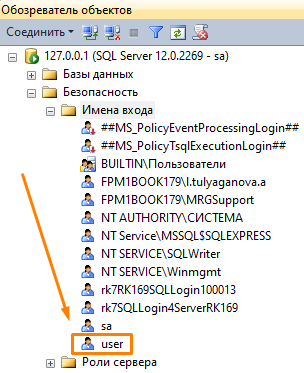
- Укажите Имя пользователя и Пароль для создания нового пользователя в SQL

- Войдите в MS SQL, используя созданные данные. В базе данных появится пользователь.
- Перейдите во вкладку Поставщик данных и убедитесь, что выбран Microsoft OLE DB Provider for SQL Server.