Как удалить сайты в бинг?
Дешевое такси (http://ostrovtaxi.ru) предлагает услуги по перевозке пассажиров в Санкт-Петербурге (http://ostrovtaxi.ru), а также за его пределами. Телефон для заказа такси в спб (http://ostrovtaxi.ru) : 600-99-90. Звоните!
На сайте с 20.02.2011
21 октября 2013, 13:38
Проще всего по-моему прописать правило индексации в robots.txt. User-agent: bingbot
Disallow: / Ну и еще насколько знаю существуют web инструменты для bing — http://www.bing.com/toolbox/webmaster.
После оптимизации можно заняться активным спортом, роликовые коньки отличное решение http://roliki.od.ua (http://roliki.od.ua)
На сайте с 10.10.2013
21 октября 2013, 13:44
Maxhit:
Проще всего по-моему прописать правило индексации в robots.txt.
User-agent: bingbot
Disallow: /
Ну и еще насколько знаю существуют web инструменты для bing — http://www.bing.com/toolbox/webmaster.
А так пойдёт? User-agent: * Disallow: / бинг увидит такой роботс и выплюнет страницы? Втечении какого времени?
На сайте с 02.03.2011
21 октября 2013, 13:52
Бинг плевал на запрет в роботс. Он будет и дальше индексировать.
Антибот, антиспам, веб файрвол, защита от накрутки поведенческих: https://antibot.cloud/ + партнерка, до 40$ с продажи.
На сайте с 10.10.2013
21 октября 2013, 14:02
foxi:
Бинг плевал на запрет в роботс. Он будет и дальше индексировать.
Я уже запутался кого слушать а кого нет
На сайте с 02.03.2011
21 октября 2013, 16:42
iterms, а ты не спрашивай. А попробуй. Правда долго придется ждать. Я пробовал. Роботс ему малоинтересен. Спасает только бан по юзер агенту, правда тогда он начинает атаковать сайт с типа простым браузерным юзер агентом, хорошо хоть ходит вроде только из сетей принадлежащих мелкософту, так можно подсети ip банить.
22 октября 2013, 16:28
iterms:
бинг увидит такой роботс и выплюнет страницы? Втечении какого времени?
Это запрет индексации всем ботам всех поисковых систем. Из Бинга сайт точно выпадет, а так же из Яндекса, Гугла и пр. Используйте пример, который вам привел Maxhit. Лично я все ненужные боты (и бинговского в том числе) запрещаю на уровне сервера в .htaccess, т.к. толку от них нет, а вот сервер перегружают неслабо.
Как удалить бинг из Яндекс браузера ?
Не могу спокойно сидеть в интернете, на каждой странице, выбегают рекламы, мешают, иногда все подвисает, это все из-за бинга этого .
В программах и компонентах . его нет! Там он не оседает . Расширения все подчистил . Подскажите, что ещё сделать? Ничего уже не получается у меня 🙁
Спасибо !
Голосование за лучший ответ
Бинг это поисковая система, просто в настройках Яндекс браузера изьени поисковую систему на Ятдекс, так же в настройках можно и удалить любую поисковую систему, в другой раз при установке программ скаченных с интернета будь внимательнее и смотри, что в дополнение тебе предлагается у становить
Зайди во вкладку <дополнительно>в браузере и там будет плагин что то типо bing plagin . Удали его или отключи
Возможность удаления Edge, отключения Bing и других функций Windows определяется JSON-файлом

Принятый в Евросоюзе Закон о цифровых рынках (Digital Markets Act, DMA) вынуждает Microsoft внести значительные изменения в Windows 10 и Windows 11. В ближайшие месяцы пользователи из ЕС получат возможность удалить Microsoft Edge, отключить Bing в поиске на панели задач, убрать ленту новостей MSN с панели виджетов и многое другое.
Сейчас эти изменения тестируются в рамках программы Windows Insider. Microsoft обещает, что стабильных версиях Windows они появятся до 6 марта 2024 года. После этой даты операционные системы компании будут полностью соответствовать Закону о цифровых рынках.
Конечно, официально воспользоваться этими изменениями смогут только пользователи из европейских стран, но есть способы обойти это ограничение. Портал Deskmodder выяснил, что возможность отключения подобных функций Windows определяется в JSON-файле IntegratedServicesRegionPolicySet.json, расположенном в папке C:\Windows\System32. В этом файле можно найти описание включаемых и отключаемых функций, статус по умолчанию и список регионов, где это будет поддерживаться.
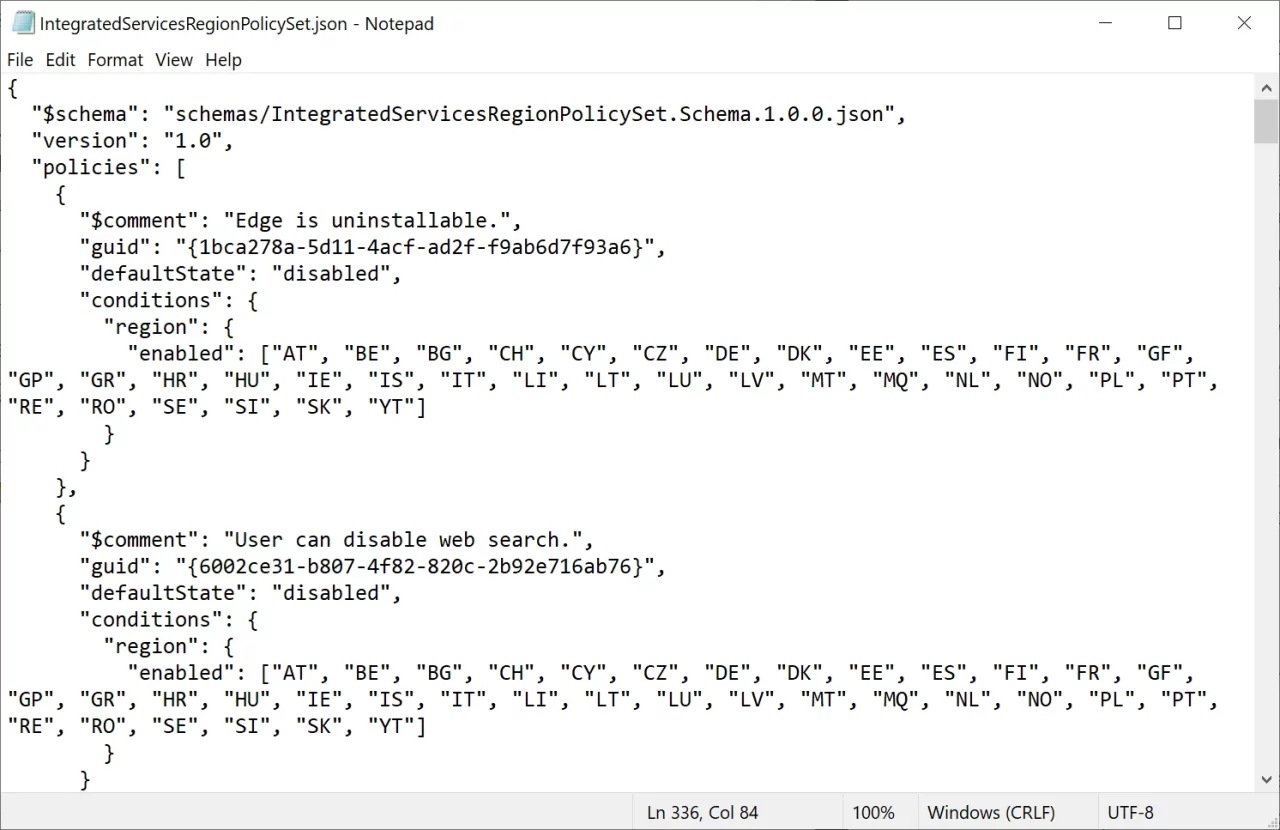
Функции, управляемые этим файлом:
- Возможность удаления Microsoft Edge
- Возможность отключения веб-поиска
- Включение расширений сценариев «Экранного диктора»
- Возможность расширения «Поиска» в «Проводнике» сторонними разработчиками
- Разрешение встроенного поиска в «Проводнике»
- Отображение популярных приложения в окне «Открыть с помощью»
- Отображение сторонних поисковых систем в окне «Поиск»
- Сторонние поисковые системы отображают актуальную сводку при пустой поисковой строке
- Основная поисковая система отображает актуальную сводку при пустой поисковой строке
- Сторонние разработчики могут настраивать Gleam на панели задач
- Отображать настройку Gleam на панели задач от основной поисковой системы
- В меню недавно использовавшихся файлов (MRU) может использоваться сторонний поставщик данных
- Для веб-поиска требуется Microsoft Edge
- Системные компоненты отделены от приложений
- Возможности резервного копирования ограничены
- Отображение файлов от провайдера рекомендаций MS Office MRU
- Отображение ленты других поставщиков в «Виджетах»
- Виджеты сторонних разработчиков отображаются в ленте «Виджетов»
- Лента сторонних виджетов может быть отключена
- Использовать веб-протокол по умолчанию для ссылок в «Виджетах»
- Ограничение совместного использования данных «Виджетов»
- Ограничение совместного использования данных сторонних виджетов
- События UTC следует ограничить тегами
- Совместное использование данных о производительности Xbox
- Общее согласие на ODD
- Windows Copilot
- Автоматическая авторизация в приложениях
- Уведомления на панели задач для виджетов
- Отображение недавних поисковых запросов при пустой поисковой строке
- Показывать веб-сайты в списке рекомендаций в меню «Пуск»
- Авторизация в виджетах ограничена учетной записью по умолчанию
- Включение значков сторонних виджетов на панели задач
- Виджеты должны быть ограничены статическими рекомендациями
- Виджеты сторонних производителей поддерживают оптимальную интеграцию с фреймом и панелью задач
Способ обхода ограничений
По умолчанию вы не являетесь владельцем файла, а значит не сможете его отредактировать. К счастью, это можно изменить.
- Перейдите в папку C:\Windows\System32.
- Создайте копию файла IntegratedServicesRegionPolicySet.json и поместите её в другую папку, чтобы у вас была резервная копия на случай проблем.
- Нажмите правой кнопкой мыши по файлу IntegratedServicesRegionPolicySet.json и выберите «Свойства».
- Перейдите на вкладку «Безопасность» и нажмите на кнопку «Дополнительно».
- Нажмите на надпись «Изменить» рядом с текущим владельцем, которым является TrustedInstaller.
- В появившемся окне введите «Администраторы» и нажмите на кнопку «Проверить имена». Windows должна автоматически указать группу пользователей.
- Нажмите ОК.
- Убедитесь, что в окне изменился владелец файла.
- Подтвердите изменения, нажав ОК.
- Нажмите на кнопку «Изменить» в окне «Свойства».
- Выделите группу «Администраторы».
- Установите галочку рядом с пунктов «Полный доступ».
- Нажмите ОК для завершения.
Теперь можно открыть файл в любом текстовом редакторе и внести необходимые изменения. Рекомендуем запускать текстовый редактор от имени администратора.
Важно! Сейчас изменения в файле IntegratedServicesRegionPolicySet.json не влияют на стабильные версии Windows 10 и Windows 11. Вероятно, эти настройки начнут работать ближе к марту 2024 года.
Как удалять страницы из индекса Google и Яндекса — восемь способов под разные ситуации без вреда для SEO

На любом сайте время от времени возникает необходимость в удалении страниц. Если просто удалить документ в админке, он останется в поисковом индексе. По крайней мере, так будет продолжаться какое-то время. Чтобы полностью убрать страницы и их содержимое из результатов поиска Google и Яндекса используют другие подходы. Способов это сделать довольно много, но ни один из них не является универсальным.
Оптимальную схему удаления всегда выбирают по ситуации. В противном случае, можно не только оставить в поиске нежелательное содержимое, но и навредить SEO-оптимизации своего сайта. Далее мы разберем восемь самых рабочих способов удаления URL-адресов. Расскажем, в каких случаях уместно применять каждый из методов и как избежать распространенных ошибок, негативно влияющих на SEO.
Как проверить присутствие страницы в индексе
Прежде чем приступать к удалению страниц, логично убедиться, действительно ли они присутствуют в индексе. Во-первых, это нужно, поскольку и Google, и Яндекс могут игнорировать некоторые страницы (обычно с малозначительным содержимым); во-вторых, если мы говорим, например, о 404-х страницах, со временем они сами вылетают из индекса.
Обычно индексирование страниц проверяют через запрос с поисковым оператором site:
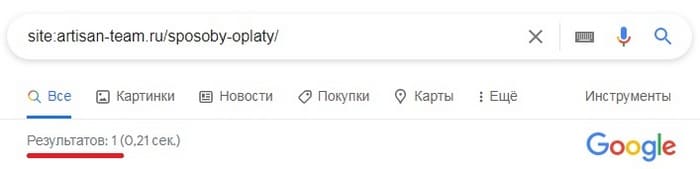
Если поисковик находит URL-адрес через оператор site:, вероятнее всего, документ проиндексирован (но бывают и исключения)
Этот способ, действительно, самый удобный. Он незаменим, например, для быстрого анализа конкурентов, когда нужно на глаз оценить масштаб их сайтов. Но для точеной проверки URL он не подходит, т. к. может в некоторых случаях предоставлять некорректные данные. Например, в результатах поиска может быть показан не запрашиваемый документ, а страница с редиректом, которой формально не существует.
Чтобы точно понять, есть URL в индексе или нет, лучше использовать консоли вебмастера Google и Яндекса.
В Google Search Console вся актуальная информация, касающаяся индексирования страниц, доступна на вкладке Индекс → Покрытие:
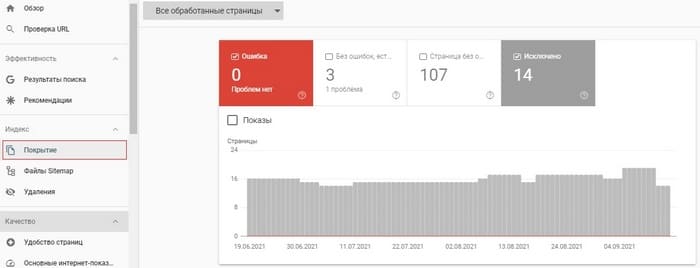
Чтобы проверить страницу еще быстрее, просто вставьте нужный URL-адрес в строку поиска вверху консоли.

Если страница в индексе, будет доступно соответствующее уведомление:
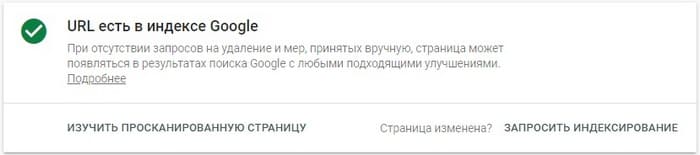
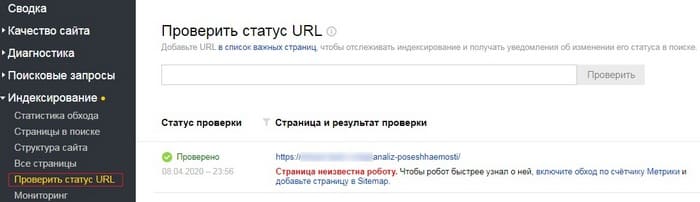
В Яндекс.Вебмастере (Индексирование → Проверить статус URL) для проверки индексирования также предусмотрен отдельный инструмент.
Способ 1. Удаление страницы
Вам ничто не мешает поступить самым очевидным способом – и просто удалить страницу вместе со всем ее содержимым в админке сайта. Это весьма топорный метод, но и его можно использовать, если быть в курсе некоторых нюансов.
После удаления документа этим способом необходимо проверить коды ответа сервера, и убедиться, что они отдают статус HTTP 404 (не найдено) или 410 (удалено). Хоть фактически страница и удалена, тем не менее она остается в индексе и продолжает ранжироваться, до момента пока поисковые роботы не совершат переобход сайта. В отдельных случаях это может занять довольно много времени. В дополнение к этому, даже несмотря на фактическое отсутствие документа, содержимое удаленной страницы будет оставаться доступным в кэше для всех желающих.

Также при удалении и деиндексировании страниц могут возникнуть проблемы с файлами, формат которых отличен от HTML, например, документами PDF, DOC, XLS и др. – их нужно удалять с сервера полностью.
Как мы видим, у этого способа есть немало нюансов, поэтому во многих случаях он не подходит. Его не нужно использовать в следующих ситуациях:
Когда необходимо удалить страницы в срочном порядке . Например, если это документы, сгенерированные вредоносным скриптом после взлома сайта. Ждать запрошенной переиндексации в этом случае – плохой вариант.
Когда на страницу стоят сильные обратные ссылки . Удаление документа в этом случае приведет к «сгоранию» сигналов, усиливающих SEO вашего сайта.
Когда нужно оставить страницу доступной для пользователей . Например, это может быть актуальным, если вы не хотите, чтобы в индексе ранжировались технические страницы с неуникальным контентом (пользовательское соглашение, политика конфиденциальности и пр.).
В этих и ряде других случаев используют менее топорные способы скрытия страниц из поиска.
Способ 2. Использование инструментов для удаления URL
В Google есть отдельный инструмент для быстрой деактивации нежелательных URL. Но его название может вводить в заблуждение, поскольку он удаляет страницы из поиска не навсегда, а только на время . Это удобно, когда нужно действовать незамедлительно, например, после взлома сайта, но в дальнейшем нужно не забыть применить другой метод постоянного удаления.
Эффект от блокировки длится порядка шести месяцев. Все это время Google видит и обрабатывает отклоненные страницы, но не отображает их в выдаче. На обработку самого запроса на скрытие может уйти до суток, хотя на практике это происходит значительно быстрее. В отдельных случаях система может не выполнить запрос на удаление URL, поэтому после подачи заявки нужно отслеживать ее статус, и если она будет отклонена, вам сообщат по какой именно причине. Вместе с самой страницей также на время можно убрать из выдачи ее кэшированную версию.
Таким образом, инструмент для деактивации URL в Google целесообразно использовать только при форс-мажорах, когда нужно экстренно удалить документ:
- при взломах;
- утечке данных;
- сбоях в работе CMS с последующим генерированием «мусорных» страниц и т. д.
Для удаленных URL-адресов, с кодом статуса 404, 502 или 503, запрос на блокировку не работает.
Инструмент для удаления в выдаче Яндекса
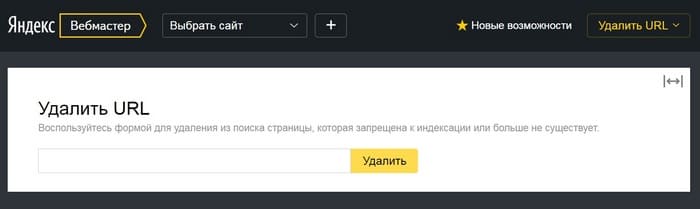
Запросить ускоренное удаление URL из выдачи Яндекса можно через соответствующий инструмент в Вебмастере. Но здесь есть важный нюанс: этот способ подходит только для деиндексирования документов, которые уже удалены либо закрыты для сканирования поисковыми роботами (через тег noindex или блокировку в robots.txt).
Способ 3. Добавление метатега robots с директивой noindex
С помощью метатега robots в HTML-коде страницы вы можете указывать поисковым работам правила обработки для конкретных URL-адресов. Чтобы запретить к индексированию нужную страницу и исключить ее из результатов поиска, к метатегу robots добавляют параметр noindex. Саму запись размещают в элементе head и выглядит она так:
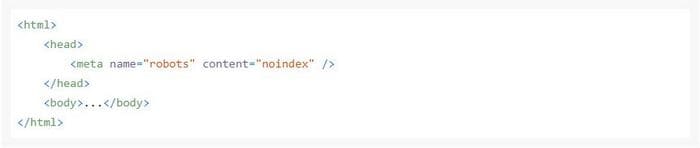
Запрещающую директиву noindex в метатеге robots (не путать с robots.txt) можно использовать в поиске Google, Яндекс и Bing.
Для каких случаев такой способ НЕ подходит:
- для закрытия страниц, имеющих качественные обратные ссылки (noindex заблокирует передачу ссылочных сигналов);
- для URL-адресов, которые нужно скрыть от части пользователей.
- для закрытия от индексирования дополнительных типов файлов, например, PDF, XLS и т. д.
Чтобы поисковые краулеры увидели и распознали метатеги с нужными директивами, страницы должны быть доступны для сканирования. Поэтому важно удостовериться, что они не закрыты от обхода в robots.txt.
Способ 4. Noindex в ответе заголовка X-Robots-Tag
Запрет на индексирование определенных URL также можно сделать через настройку HTTP-заголовка X-Robots-Tag на сервере. В этом случае используют уже упомянутую директиву noindex. HTTP-ответ, где заголовок запрещает индексирование документа, выглядит так:

Запрет через X-Robots-Tag принято считать более надежным способом деиндексирования, чем использование noindex в метатеге robots, поскольку вероятность, что поисковые краулеры проигнорируют директиву HTTP-заголовка значительно ниже. Также этот способ незаменим, когда URL-адрес, который нужно удалить из индекса, это не веб-страница, а, например, PDF-файл.
Тем не менее этот вариант не подходит, если нужно закрыть страницу, которая имеет хорошие обратные ссылки. Также данный способ неуместен, когда нужно деиндексировать страницу максимально оперативно.
Способ 5. Ограничение доступа к странице
Страницы с ограниченным доступом, например, защищенные паролем, по умолчанию закрыты для обхода поисковыми роботами и, соответственно, содержимое таких документов не попадает в индекс. Это довольно специфический способ управления индексированием, и актуален он лишь в тех случаях, когда нужно предоставить доступ к страницам только небольшому кругу пользователей. С технической точки зрения для ограничения доступа можно использовать одно из следующих решений:
- систему учетных записей;
- HTTP-аутентификацию;
- доступ по подтвержденным IP-адресам.
В этих случаях поисковые роботы не смогут проиндексировать содержимое страниц, а сам контент не будет доступен сторонним пользователям. Это актуально при создании внутренних сетей, публикации платного или другого непубличного контента. Также доступ к страницам лучше ограничивать на этапах разработки или тестирования сайта, чтобы исключить индексирование технического «мусора». Если непубличный контент уже попал в индекс и его нужно срочно скрыть из кэша, используют метод №2.
Способ 6, 7 и 8. Деиндексирование с перераспределением ссылочного веса
Описанные выше способы касались удаления из индекса URL, по большей части не представляющих ценности для сайта. Теперь поговорим о ситуациях, когда нужно деиндексировать документы, которые полезны для продвижения и передают ценные SEO-сигналы. Обычно здесь имеют ввиду страницы с качественными обратными ссылками, которые по каким-то причинам нужно скрыть из индекса.
Деиндексирование URL с сохранением их ссылочного веса проводят одним из трех методов.
6. Создание 301-редиректа
Редирект – это техническая настройка, которая автоматически перенаправляет с одного URL-адреса на другой. Их бывает несколько видов, но нас интересует главным образом редирект с кодом 301. Он не просто автоматически перенаправляет пользователей с неактуальной страницы (А) на нужную версию (В), но и указывает поисковым роботам, что весь ссылочный вес документа А нужно перераспределить на документ В, а саму исходную страницу удалить из индекса.
Важно понимать, что такие перенаправления работают только между тематически релевантными URL. Если вы решите сделать 301-редирект со страницы А, которая по содержанию не соотносится со страницей В, поисковикам сильно не понравятся такие манипуляции. Они не только блокируют перераспределение ссылочного веса, но и могут начать учитывать редирект как ложную ошибку (soft 404). Таким образом нужная версия страницы будет недоступной для пользователей.
Больше о принципах работы 301-редиректа и тонкостях его настройки – читайте в отдельной статье.
7. Атрибут rel=”canonical”
Добавление канонического тега rel=”canonical” – классическое решение проблемы дублей и один из способов управления индексированием. Если разные страницы на сайте имеют очень похожее содержимое или полностью повторяются – это серьезный недочет оптимизации. Поисковики умеют объединять такие дубли в группы. Из этого набора они выбирают самую информативную и релевантную страницу (ее называют канонической ), а остальное удаляют из индекса. Но полагаться на работу алгоритмов не стоит, и лучше указать каноническую страницу самому – при помощи тега rel=”canonical”.
Технически в такой каноникализации нет ничего сложного: на всех второстепенных страницах нужно добавить фрагмент кода, который будет сообщать поисковикам, что это дубль, и указывать на основную (каноническую) страницу.
Например, у нас есть основная страница ( www.example.com/blog ) и ее дубль ( www.example.com/blog_2 ). Чтобы подсказать поисковикам, какой документ главный, в HTML-код страницы /blog_2 нужно добавить такой фрагмент:

Атрибут rel=”canonical” поддерживается всеми поисковыми системами. При этом его нужно использовать, только когда страницы действительно дублируются или очень похожи по содержанию. Если поисковик посчитает, что это не так, атрибут rel=”canonical” будет проигнорирован, поскольку это рекомендация, а не обязательная директива. Также каноникалы имеют свойство слетать, поэтому их нужно время от времени проверять, особенно если на сайте проводили технические работы или вносили другие серьезные изменения.
Canonical не используют в связке с noindex (способ 3 и 4). Это конфликтующие сигналы для поисковиков, поскольку атрибут rel=”canonical” дает указание, что нужно проиндексировать другую страницу, а noindex рекомендует убрать документ из индекса. При использовании сразу двух атрибутов поисковые системы, вероятнее всего, учтут canonical, а noindex просто проигнорируют. Но возможен и обратный сценарий – тогда страницы не смогут передавать ссылочные сигналы, а это уже серьезный недочет внутренней оптимизации (по крайней мере, если таких страниц много).
8. Настройка обработки параметров URL
Параметры — это часть URL, которая присоединяется обычно после знака ? в конце адреса. Необходимость в них чаще всего возникает, когда нужно отфильтровать страницу по каким-то характеристикам.
Например, у нас есть карточка женского платья со стандартным URL:

Если мы выберем другой цвет товара, исходная страница поменяет URL на такой:

А если мы найдем это же платье через фильтр магазина, URL карточки уже будет выглядеть так.

Во всех трех случаях мы имеем дело с одной и той же страницей, но разными URL. Чтобы помочь поисковикам корректно сканировать такие дубли, нужно задать настройки обработки параметров. В Google это делают с помощью инструмента «Параметры URL». Подробнее о принципах его использования – в официальной справке. Сам способ применяют исключительно для страниц с параметрами. Во всех остальных случаях применяют атрибут rel=”canonical” или другой из описанных выше методов каноникализации.
В Яндексе, насколько мы в курсе, подобного инструмента не предусмотрено. Чтобы исключить сканирование одинаковых страниц с параметрами, здесь используют другие схемы:
- отклонение в robots.txt через директиву clean-param;
- использование noindex/nofollow;
- каноникализацию через rel=”canonical”.
Как удалить картинки из поискового индекса
Когда нужно оперативно убрать изображение из поиска – удаляют всю страницу, используя способ №1. Это самая быстрая схема, которая к тому же позволяет сразу вычистить фото из кэша. Но инструмент удаления URL работает только под Google, поэтому картинки будут оставаться доступными в Яндексе. К тому же, если нужно убрать изображение из поиска, далеко не всегда целесообразно удалять всю страницу.
Более универсальный, хоть и не такой быстрый, способ скрыть картинки от Google и Яндекса – ограничить их сканирование в файле robots.txt, используя директиву Disallow (она запрещает индексирование разделов сайта, отдельных страниц или конкретного файла). При этом сами изображения будут оставаться на сайте. Это оптимальный вариант для тех, кто использует на своих страницах заимствованные фото и не хочет лишний раз засвечивать их в поиске.

изображение, расположенное по указанному адресу, будет закрыто от индексирования в Google
Этот способ более гибкий благодаря поддержке подстановочных знаков. В robots.txt можно запретить сканирование картинок определенного формата, например, только GIF-файлов:

Также здесь можно дать указание, отображать картинки в основном поиске, но блокировать их на вкладке с изображениями. Это позволит странице, например, отображаться в колдунщике с подтянутым фото на вкладке «Все результаты».
Директива Disallow поддерживается Google и Яндексом, но при необходимости можно заблокировать ранжирование изображений только в одной из поисковых систем. В то же время этот способ не такой быстрый, и чтобы фото пропали из результатов выдачи, придется дождаться переиндексирования.