sp_query_store_force_plan (Transact-SQL)
Включает принудительное принудительное выполнение определенного плана для конкретного запроса в хранилище запросов.
При принудительном выполнении плана для конкретного запроса каждый раз, когда SQL Server сталкивается с запросом, он пытается принудительно применить план в оптимизаторе запросов. Если это не удастся сделать, запускается расширенное событие, и оптимизатору запросов предписывается выполнить оптимизацию обычным способом.
Синтаксис
sp_query_store_force_plan [ @query_id = ] query_id , [ @plan_id = ] plan_id , [ @disable_optimized_plan_forcing = ] disable_optimized_plan_forcing , [ @force_plan_scope = ] 'replica_group_id' [ ; ] Аргументы
[ @query_id = ] query_id
Идентификатор запроса. @query_id является bigint, без значения по умолчанию.
[ @plan_id = ] plan_id
Идентификатор плана запроса, который необходимо принудительно принудить. @plan_id является bigint, без значения по умолчанию.
[ @disable_optimized_plan_forcing = ] disable_optimized_plan_forcing
Указывает, следует ли отключить принудительное выполнение оптимизированного плана. @disable_optimized_plan_forcing бит по умолчанию 0 .
[ @force_plan_scope = ] ‘ реплика_group_id’
При включении дополнительных хранилище запросов дополнительных реплика можно принудительно заставить планы на дополнительных реплика. Выполнение sp_query_store_force_plan и sp_query_store_unforce_plan выполнение дополнительных реплика. Необязательный аргумент @force_plan_область по умолчанию используется только для локальной реплика (основной или вторичной), но при необходимости можно указать реплика_group_id ссылки sys.query_store_реплика.
Значения кода возврата
0 (успешно) или 1 (сбой).
Замечания
Результирующий план выполнения, вынужденный этой функцией, совпадает или аналогичен принудительному выполнению плана. Так как итоговый план может не совпадать с планом, указанным в инструкции sys.sp_query_store_force_plan , производительность этих планов может различаться. В редких случаях возможна значительная негативная разница в производительности, и тогда администратору следует удалить принудительный план.
Просмотрите принудительные планы на вторичных реплика с помощью sys.query_store_plan_forcing_locations.
Разрешения
Необходимо разрешение ALTER для базы данных.
Примеры
В следующем примере возвращаются сведения о запросах в хранилище запросов.
SELECT txt.query_text_id, txt.query_sql_text, pl.plan_id, qry.* FROM sys.query_store_plan AS pl INNER JOIN sys.query_store_query AS qry ON pl.query_id = qry.query_id INNER JOIN sys.query_store_query_text AS txt ON qry.query_text_id = txt.query_text_id; После определения query_id и plan_id, которые требуется принудительно, используйте следующий пример, чтобы принудительно использовать план.
EXEC sp_query_store_force_plan @query_id = 3, @plan_id = 3; SELECT query_plan FROM sys.query_store_plan AS qsp INNER JOIN sys.query_store_plan_forcing_locations AS pfl ON pfl.query_id = qsp.query_id INNER JOIN sys.query_store_replicas AS qsr ON qsr.replica_group_id = qsp.replica_group_id WHERE qsr.replica_name = 'yourSecondaryReplicaName'; Связанный контент
- sys.query_store_plan_forcing_locations (Transact-SQL)
- sys.query_store_реплика (Transact-SQL)
- sp_query_store_remove_plan (Transact-SQL)
- sp_query_store_remove_query (Transact-SQL)
- sp_query_store_unforce_plan (Transact-SQL)
- Представления каталога хранилища запросов (Transact-SQL)
- Мониторинг производительности с использованием хранилища запросов
- sp_query_store_reset_exec_stats (Transact-SQL)
- sp_query_store_flush_db (Transact-SQL)
- Рекомендации по хранилищу запросов
Обратная связь
Были ли сведения на этой странице полезными?
SET FORCEPLAN (Transact-SQL)
Если параметр FORCEPLAN имеет значение ON, оптимизатор запросов SQL Server обрабатывает соединение в том же порядке, что и таблицы в предложении FROM запроса. Кроме того, при установке параметра FORCEPLAN в значение ON принудительно используется вложенный цикл соединения, если для построения плана запроса не требуются другие типы соединений или же они запрашиваются с указаниями соединений или запросов.
Синтаксис
SET FORCEPLAN
Сведения о синтаксисе Transact-SQL для SQL Server 2014 (12.x) и более ранних версиях см . в документации по предыдущим версиям.
Замечания
Инструкция SET FORCEPLAN, в сущности, переопределяет логику, используемую в оптимизаторе запросов для обработки инструкции SELECT языка Transact-SQL. Данные, возвращаемые инструкцией SELECT, не зависят от этого параметра. Единственное различие заключается в том, как SQL Server обрабатывает таблицы для удовлетворения запроса.
Указания оптимизатора запросов также можно использовать в запросах, чтобы повлиять на способ обработки инструкции SELECT SQL Server.
Инструкция SET FORCEPLAN применяется на этапе выполнения или запуска, но не на этапе синтаксического анализа.
Разрешения
Разрешения SET FORCEPLAN по умолчанию имеют все пользователи.
Примеры
В следующем примере выполняется соединение четырех таблиц. Параметр SHOWPLAN_TEXT включен, поэтому SQL Server возвращает сведения о том, как он обрабатывает запрос по-разному после SET FORCE_PLAN включения параметра.
USE AdventureWorks2022; GO -- Make sure FORCEPLAN is set to OFF. SET SHOWPLAN_TEXT OFF; GO SET FORCEPLAN OFF; GO SET SHOWPLAN_TEXT ON; GO -- Example where the query plan is not forced. SELECT p.LastName, p.FirstName, v.Name FROM Person.Person AS p INNER JOIN HumanResources.Employee AS e ON e.BusinessEntityID = p.BusinessEntityID INNER JOIN Purchasing.PurchaseOrderHeader AS poh ON e.BusinessEntityID = poh.EmployeeID INNER JOIN Purchasing.Vendor AS v ON poh.VendorID = v.BusinessEntityID; GO -- SET FORCEPLAN to ON. SET SHOWPLAN_TEXT OFF; GO SET FORCEPLAN ON; GO SET SHOWPLAN_TEXT ON; GO -- Reexecute inner join to see the effect of SET FORCEPLAN ON. SELECT p.LastName, p.FirstName, v.Name FROM Person.Person AS p INNER JOIN HumanResources.Employee AS e ON e.BusinessEntityID = p.BusinessEntityID INNER JOIN Purchasing.PurchaseOrderHeader AS poh ON e.BusinessEntityID = poh.EmployeeID INNER JOIN Purchasing.Vendor AS v ON poh.VendorID = v.BusinessEntityID; GO SET SHOWPLAN_TEXT OFF; GO SET FORCEPLAN OFF; GO SQL-Ex blog

Документация SQL Server содержит довольно крутой список хинтов запросов:
Но что там за цветной ящик? Смотрим.
Поскольку оптимизатор запросов SQL Server обычно выбирает наилучший план выполнения запроса, мы рекомендуем использовать хинты только как последнее средство для опытных разработчиков и администраторов баз данных.
Я мог бы пошутить, но. каждая отдельная вещь в этом предупреждении верна. SQL Server действительно обычно выбирает лучший план выполнения для запроса, примерно 99,999% времени, и вы если вы используете хинт запроса, то вероятно допускаете ошибку.
Однако следует сказать, что если вы читаете этот блог, то вы уже более опытны, чем большинство пользователей SQL Server. Нет, серьезно, я знаю, у вас все хорошо, и что давно пора подумать об использовании нескольких из них, когда ситуация с настройкой запросов становится действительно ужасной.
Подробнее о каждом из них, включая версии, когда они появились, читайте в документации на хинты запросов.
OPTION (MIN_GRANT_PERCENT = 5) или OPTION (MAX_GRANT_PERCENT = 10) — когда планы выполнения ваших запросов запрашивают слишком много (или недостаточно) памяти, а вы уже пытались настроить запросы и индексы, этот хинт является последним полезным средством.
OPTION (FORCE ORDER) — если вы боретесь с планом выполнения, который не вполне понимает, какая из таблиц наиболее селективна или должна быть обработана первой, этот хинт вынуждает SQL Server обрабатывать таблицы в том порядке, в котором они записаны в запросе. Этот хинт мне нравится больше, чем индексные хинты, поскольку он все же предоставляет SQL Server свободу действий при выборе метода доступа к каждой таблице.
OPTION (MAXDOP 0) — если вы уперлись в сервер поставщика третьей стороны, требующего, чтобы вы установили MAXDOP = 1, знали ли вы, что можете установить значение MAXDOP выше для вашего собственного запроса, используя хинт? Хорошо, теперь вы знаете: этот хинт уровня запроса переписывает серверную установку MAXDOP. Замечательно для построения индексов или таблиц для отчетов.
Документация содержит еще много того, что вы определенно не будете использовать часто — но сегодня, похоже, хороший день, чтобы вернуться и посмотреть, какие новые варианты доступны для используемой вами версии SQL Server.
SQL-Ex blog
Появление в SQL 2016 Query Store (хранилище запросов) явилось, без сомнения, наиболее привлекательной и обсуждаемой новой функциональностью. В этой статье мы просто бросим краткий взгляд на нее, что это такое, как запустить и как это можно использовать. Это будет довольно краткий обзор — потребуется целая книга, чтобы описать все подробно — но, надеюсь, что он даст вам понятие о том, насколько это будет полезно и как начать использовать.
На базовом уровне то, что делает хранилище запросов, довольно просто. Оно просто хранит информацию, относящуюся к исполняющимся запросам.
- Планы выполнения — планы выполнения, генерируемые для каждого запроса, сохраняются в хранилище запросов, и, если план меняется, новый план сохраняется тоже.
- Метрики производительности — такая информация, как использование ЦП, чтения и записи, захватывается и сохраняется для каждого запроса.
Это не что-то радикально новое, вы уже могли выполнить запрос для нахождения плана выполнения запроса, и вы также могли запросить агрегированные метрики производительности, относящиеся к заданному запросу.
Разница состоит в том, что теперь история может поддерживаться без применения дополнительного мониторинга. Ранее метрики производительности могли агрегироваться в единственный накопительный итог, начиная от последнего перезапуска экземпляра SQL — и могли очищаться при следующем перезапуске. Теперь они сохраняются на постоянной основе и разделены по времени, поэтому вы можете реально оценивать изменения с течением времени.
Простая деятельность по сохранению старых планов выполнения также важна для устранения проблем производительности. Каждый, кто работал с большим объемами производственных данных, столкнется с проблемой, когда функция, которая работала хорошо, внезапно начала испытывать проблемы производительности.
Обычной причиной этого является то, что называется «регрессией плана». Это когда план выполнения изменился — а новый план не так хорош, как старый, для большего числа выполнений. Раньше вы могли подозревать, что именно это было причиной наблюдаемой проблемы, но не было легкого способа проверить это. Теперь вы можете использовать хранилище запросов для наблюдения и сравнения старого и нового планов, чтобы проверить это. Вы можете даже одним или двумя щелчками заставить запрос вернуться к использованию старого (лучшего) плана — хотя мы надеемся, что люди не будут злоупотреблять этой возможностью, а попытаются, по крайней мере, разобраться в проблеме и подумать о ее решении. Обычно существует причина, по которой SQL считает, что новый план будет лучше — и конкретный план может хорошо работать на данный момент, но он может оказаться не лучшим планом в будущем, когда данные поменяются.
Давайте рассмотрим эту функциональность немного более подробно.
Включение хранилища запросов
Хранилище запросов — это конфигурация уровня базы данных. Важно понимать это и то, что информация фактически хранится в системных таблицах базы данных. Это означает, что если вы резервируете и восстанавливаете базу данных, информация сохраняется. Очень важно также, что информация сохраняется асинхронно — поэтому не должно быть какого-либо влияния на производительность при выполнении самих запросов. Конечно, будут иметь место некоторые накладные расходы сервера в момент сохранения данных, но в большинстве случаев незначительные.
Вы можете включить Query Store для базы данных с помощью T-SQL (или в вашем исходном коде) или посредством GUI в SSMS. Я просто хочу продемонстрировать это в GUI, чтобы вы смогли увидеть разные опции. Выполните щелчок правой кнопкой на базе данных, выберите свойства, а затем выберите страницу Query Store в самом низу списка:

Как видно выше, Query Store включен для базы данных WideWorldImporters со всеми установками по умолчанию.
Первой установкой является “Operation Mode”. По умолчанию она установлена в «Off». Чтобы включить Query Store и позволить ему выполняться для конкретной базы данных, вам следует изменить ее на “Read Write”. Это все.
Интервал Data Flush — это как часто данные хранилища запросов записываются на диск — напомню, что это выполняется асинхронно.
Интервал Statistics Collection задает величину отрезков времени, в которых агрегируются метрики производительности запроса.
Затем у нас есть кое-что, связанное с хранением данных. Важно отметить, что если хранилище запросов заполнится и ничто не приведет к его очистке, то оно перейдет в режим Read-Only (только чтение), и никакие данные не будут сохраняться, пока не освободится место. По умолчанию объем установлен в 100Мб — это не так много места, поэтому я реально не вижу никаких оснований не включать эту функцию.
Оставляя установку Auto для “Size Based Cleanup Mode”, должно гарантировать, что старые данные очищаются, если хранилище запросов начнет заполняться. Выше находится “Query Store Capture Mode” — если оставить AUTO, то будут игнорироваться нечастые запросы или запросы с незначительными накладными расходами.
Последняя настройка “Stale Query Threshold” определяет то, как долго хранятся данные в днях. 30 дней принимается по умолчанию. Было бы полезно существенно увеличить ее, если мы хотим использовать Query Store для мониторинга производительности на более длительный период. Но это может зависеть от места, которое хранилище запросов будет использовать для вашей базы данных — помните, что значением по умолчанию является 100Мб, но вы можете увеличить его, когда захотите.
Внизу страницы свойств можно увидеть несколько круговых диаграмм, которые показывают сколько места в базе данных выделено Query Store и сколько из этого места использовано.
Итак, хранилище запросов установлено и сконфигурировано, давайте посмотрим на то, что это нам дает.
Хранилище запросов в действии и навязывание плана
Как показано выше, я установил Query Store для копии базы данных WideWorldImporters на экземпляре SQL 2016. Я создал хранимую процедуру, которую запускаю каждые 2 секунды, и установил 1-минутный интервал Statistics Collection Interval в Query Store (а не 1 час) с тем, чтобы довольно быстро получить некоторые цифры и графики.
В ветке базы данных в SSMS теперь появилась папка Query Store, где находятся некоторые встроенные отчеты:
Для этого сообщения в блоге я собираюсь продемонстрировать только пару из них. Давайте откроем отчет “Top Resource Consuming Queries”:

Можно увидеть несколько вещей. Слева вверху находится гистограмма наиболее дорогих запросов (вы видите один большой прямоугольник, а остальные небольшие по сравнению с ним — большой соответствует моему запросу). Вы можете задать в конфигурации затраты ЦП или логические чтения среди других опций, а также нужны ли вам средние, максимальные или минимальные значения. По сути, есть масса способов, которыми вы можете настроить свое представление.
Честно говоря, я боролся с некоторыми из этих встроенных отчетов Query Store, чтобы заставить их показать мне то, что я хотел, поэтому готовьтесь немного поиграть, чтобы понять, как использовать эту функцию.
На гистограмме зеленый прямоугольник — это выбранный в настоящее время запрос, справа находится точечный график показателей выполнения этого запроса на интервалах нашей статистики (напомню, что я установил интервал в 1 минуту). Можно видеть, что я наблюдаю среднее число логических чтений. Вы также видите, что этот запрос прекрасно выполнялся примерно до 14:05, когда что-то произошло (это был я!) и число логических чтений в каждом выполнении внезапно выросло. Кружки на точечном графике в этом месте также изменили цвет, и это показывает, что теперь запрос использует новый план выполнения.
Рядом с графиком находится легенда, сообщающая какому плану соответствует цвет кружка, и, если вы щелкните на желаемом плане в легенде, он отобразится на нижней панели. В данный момент я наблюдаю исходный план (Plan 1). Заметим, что в заголовке указано «not forced» (не навязанный), также имеется кнопка справа от заголовка, предлагающая вариант «Force Plan» (навязанный план). Давайте задержимся на минуту, прежде чем сделаем это.
Прежде чем что-то поменять, чтобы попытаться решить проблему с этим запросом, давайте посмотрим отчет “Regressed Queries”. Он почти такой же, но вы можете использовать его с разных сторон. Т.е. он может не быть одним из наиболее дорогих ваших запросов, которые начали работать плохо, поэтому, если вы взгляните на отчет Regressed Queries, он будет фокусироваться на тех запросах, для которых план выполнения изменился в интервале, который вы рассматриваете. И опять для меня было непросто добиться от этого отчета, чтобы он дал интересующую меня информацию — потребуется немного поиграться с ним.
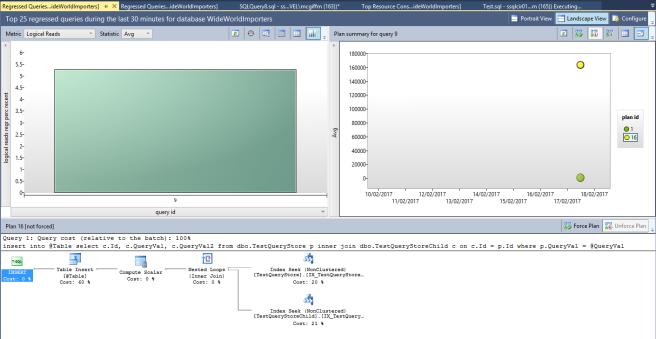
Вы можете увидеть на диаграмме только один большой широкий прямоугольник — т.к. я имею только один регрессивный запрос с интервале (последние 30 минут), который я выбрал для просмотра. Это может упростить выявление запросов, в которых возникает подобная проблема.
Я вернусь к предыдущему отчету Resource Consumers (потребление ресурсов) и попытаюсь решить проблему. Теперь я действительно знаю, что я делал и почему запрос стал плохим. Это был результат, вызванный прослушиванием параметров, когда, если перекомпилировать хранимую процедуру, сформированный план выполнения может отличаться в зависимости от параметров, с которыми выполнялся запрос. Обычно это формирует лучший план для предоставленных параметров — но может оказаться далеко не лучшим планом для всех наборов параметров. В данном случае я принудил хранимую процедуру сформировать план, который оказался дорогим в большинстве случаев.
Эту проблему было бы лучше пофиксить в коде хранимой процедуры, но в продакшене исправление может занять несколько дней, а у нас есть проблема прямо сейчас. Поэтому давайте использовать функциональность Force Plan для решения проблемы — только на время.
Я выбираю желаемый план и щелкаю кнопку “Force Plan”. Эффект проявляется сразу, и я замечаю его спустя минуты, поскольку мой интервал сбора статистики очень мал. Пусть поработает немного, и я покажу вам новый график:
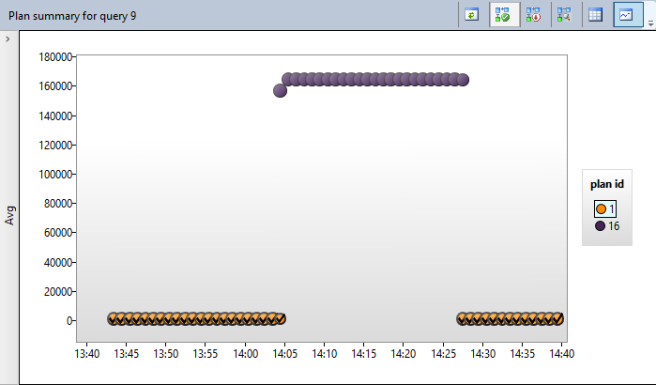
Вы можете увидеть, что теперь запрос вернулся к быстрому выполнению. Замечу, что все оранжевые кружки теперь отмечены галочкой, чтобы обозначить, что этот план является принудительным.
Сравнение планов
Связанной функцией в SQL 2016 является возможность сравнения двух планов выполнения для поиска изменений. Для себя я не посчитал это удивительным, когда посмотрел на нее, но это было обусловлено естественными ограничениями — если два плана существенно отличаются, то выделение различия просто выделит все. Однако это может быть полезным, чтобы, по крайней мере, видеть одновременно оба плана на экране и легко переходить от одного к другому.
Вам нет необходимости делать это посредством Query Store — если выполнить щелчок правой кнопкой на любом плане выполнения в SSMS, где теперь есть опция “Compare ShowPlan”, и, поскольку вы уже имеете план, который хотите сравнить с сохраненным в файле, то можете двигаться дальше. Заметим, что хорошо то, что это является функцией SSMS, поэтому, если вы имеете SSMS 2016 или выше, вы можете пользоваться этим для сравнения планов на более ранних версиях SQL Server.
С помощью Query Store вы можете сравнивать планы непосредственно из хранилища. Если мы вернемся к одному из отчетов выше, планы перечислены в легенде точечного графика. Вы можете выбрать более одного плана, используя Shift+ щелчок. Затем вы можете щелкнуть кнопку в панели инструментов выше точечного графика, которая имеет всплывающую подсказку “Compare the Plans for the selected query in separate window” (Сравнить планы для выбранного запроса в отдельном окне).
Давайте сделаем это для двух планов, сформированных выше для нашего запроса. Результат показывает нам два представления рядом. Может быть полезно взглянуть на них по отдельности для лучшего размещения на странице. В левой части имеем:
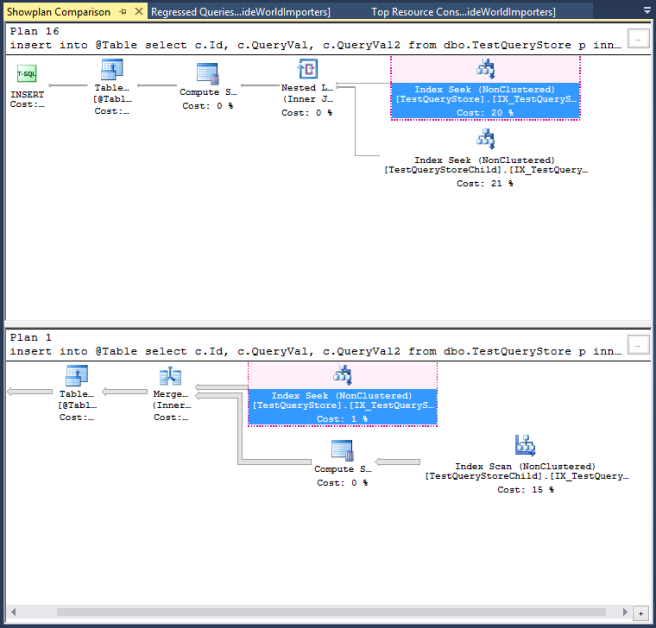
Выделенная красным область — это то, где инструмент обнаружил совпадение планов. В остальном он не так уверен. Тем не менее, это хорошее визуальное представление, просто чтобы увидеть, что делают оба плана. Справа на экране вы получаете это представление:
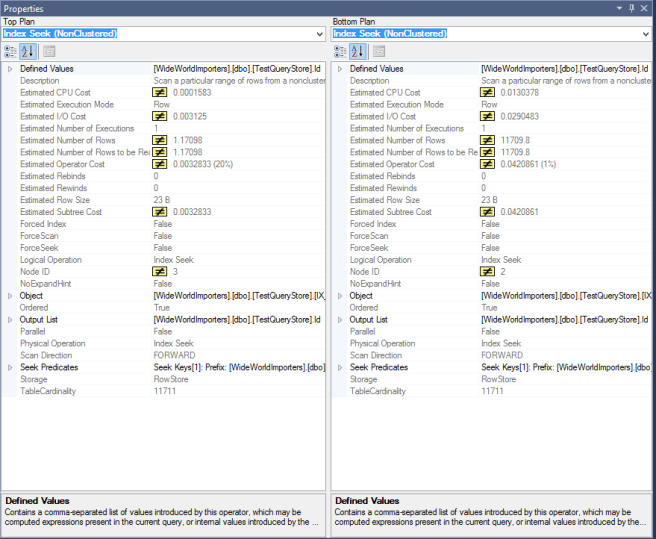
Здесь показано сравнение свойств выбранного оператора на каждом плане — отметим, что это не обязательно должен быть эквивалентный оператор на каждом плане. Вы можете выбрать оператор Nested Loop сверху и оператор Index Scan снизу, и они будут показаны — хотя тут сравнение может иметь мало смысла!
Итак, это полезный инструмент, но не следует ожидать от него магического решения процесса сравнения планов за вас. В общем, слишком много различий между планами, чтобы это было так просто — но это может помочь — немного…
Представления каталога хранилища запросов
Подобно всему в SQL Server, вся информация, к которой вы можете получить доступ посредством GUI в SSMS, доступна непосредственно с использованием системных каталогов и представлений. Поэтому, если вы хотите проверить информацию, которая не предоставляется встроенными отчетами, то можете просто написать свои собственные запросы.
Имеются такие новые представления:
sys.database_query_store_options
sys.query_context_settings
sys.query_store_plan
sys.query_store_query
sys.query_store_query_text
sys.query_store_runtime_stats
sys.query_store_runtime_stats_interval
Вместо того, чтобы погружаться в детали, я просто дам ссылку на MSDN:
Заключение
Хранилище запросов — замечательная функция. Не космическая, но очень полезная. В частности, она очень помогает исследованию проблем с производительностью, экономя время на их исправления.
Она также полезна для мониторинга производительности во времени и дает возможность опережать проблемы масштабируемости с конкретными запросами.
Методы навязывания плана также замечательны для быстрого исправления — но не злоупотребляйте этим. Есть возможность навязывания планов в более ранних версиях SQL — но это непросто, поэтому люди предпочитают просто править код. Навязывание планов может привести к устранению симптомов, но не причин, и впоследствии может вызвать другие проблемы.