Обучение моделей Keras в большом масштабе с помощью Машинного обучения Azure

ОБЛАСТЬ ПРИМЕНЕНИЯ: пакет SDK для Python azure-ai-ml версии 2 (текущая версия)
Из этой статьи вы узнаете, как запустить сценарии обучения Keras с помощью пакета SDK Для Python машинного обучения Azure версии 2.
В примере кода в этой статье используется Машинное обучение Azure для обучения, регистрации и развертывания модели Keras, созданной с помощью серверной части TensorFlow. Модель, глубокая нейронная сеть (DNN), созданная с помощью библиотеки Keras Python , работающей поверх TensorFlow, классифицирует рукописные цифры из популярного набора данных MNIST.
Keras — это высокоуровневый API нейронной сети, который может работать поверх других популярных платформ DNN для упрощения разработки. С помощью Машинного обучения Azure вы можете быстро масштабировать задания обучения с помощью эластичных облачных вычислительных ресурсов. Вы также можете отслеживать обучающие запуски, управлять версиями моделей, развертывать модели и многое другое.
Независимо от того, разрабатываете ли вы модель Keras с нуля или используете существующую модель в облаке, Машинное обучение Azure поможет создавать модели, готовые для использования в рабочей среде.
Если вы используете API Keras tf.keras, встроенный в TensorFlow, а не автономный пакет Keras, вместо этой статьи см. статью Обучение моделей TensorFlow.
Предварительные требования
Чтобы воспользоваться преимуществами этой статьи, вам потребуется:
- Доступ к подписке Azure. Если у вас еще нет учетной записи, создайте бесплатную учетную запись.
- Запустите код, приведенный в этой статье, с помощью вычислительного экземпляра Машинного обучения Azure или собственной записной книжки Jupyter.
- Вычислительный экземпляр Машинного обучения Azure — скачивание или установка не требуется
- Выполните инструкции Создание ресурсов, чтобы приступить к созданию выделенного сервера записной книжки, предварительно загруженного с помощью пакета SDK и репозитория примеров.
- В папке примеров глубокого обучения на сервере записных книжек найдите готовую и развернутую записную книжку, перейдя в этот каталог: одношаговая инструкция tensorflow для заданий > python > версии 2 > для пакета SDK > для одношагового > обучения tensorflow > train-hyperparameter-tune-deploy-with-keras.
- Установите пакет SDK машинного обучения Azure (версия 2).
Вы также можете найти завершенную версию Jupyter Notebook этого руководства на странице примеров GitHub.
Перед запуском кода в этой статье для создания кластера GPU необходимо запросить увеличение квоты для рабочей области.
Настройка задания
В этом разделе настраивается задание для обучения путем загрузки необходимых пакетов Python, подключения к рабочей области, создания вычислительного ресурса для выполнения командного задания и создания среды для выполнения задания.
Подключение к рабочей области
Сначала необходимо подключиться к рабочей области Машинного обучения Azure. Рабочая область Машинного обучения Azure — это ресурс верхнего уровня данной службы. Она предоставляет централизованное место для работы со всеми артефактами, создаваемыми при использовании Машинного обучения Azure.
Мы используем DefaultAzureCredential для получения доступа к рабочей области. Эти учетные данные должны обрабатывать большинство сценариев проверки подлинности пакета Azure SDK.
Если DefaultAzureCredential это не подходит для вас, просмотрите azure-identity reference documentation или Set up authentication дополнительные доступные учетные данные.
# Handle to the workspace from azure.ai.ml import MLClient # Authentication package from azure.identity import DefaultAzureCredential credential = DefaultAzureCredential()Если вы предпочитаете использовать браузер для входа и проверки подлинности, следует раскомментировать следующий код и использовать его.
# Handle to the workspace # from azure.ai.ml import MLClient # Authentication package # from azure.identity import InteractiveBrowserCredential # credential = InteractiveBrowserCredential()Затем получите дескриптор рабочей области, указав идентификатор подписки, имя группы ресурсов и имя рабочей области. Чтобы найти эти параметры, выполните указанные ниже действия.
- Найдите имя рабочей области в правом верхнем углу панели инструментов Студия машинного обучения Azure.
- Выберите имя рабочей области, чтобы отобразить идентификатор группы ресурсов и подписки.
- Скопируйте значения группы ресурсов и идентификатора подписки в код.
# Get a handle to the workspace ml_client = MLClient( credential=credential, subscription_id="", resource_group_name="", workspace_name="", )Результатом выполнения этого скрипта является дескриптор рабочей области, который будет использоваться для управления другими ресурсами и заданиями.
- Создание MLClient не приведет к подключению клиента к рабочей области. Инициализация клиента отложена и будет ожидать первого вызова. В этой статье это произойдет во время создания вычислительных ресурсов.
Создание вычислительного ресурса для выполнения задания
Машинному обучению Azure требуется вычислительный ресурс для выполнения задания. Этот ресурс может быть компьютером с одним или несколькими узлами с ОС Linux или Windows или конкретной вычислительной структурой, например Spark.
В следующем примере скрипта мы подготавливаем Linux compute cluster . Вы можете просмотреть страницу Azure Machine Learning pricing с полным списком размеров виртуальных машин и цен. Так как для этого примера нам нужен кластер GPU, давайте выберем модель STANDARD_NC6 и создадим вычислительные ресурсы Машинного обучения Azure.
from azure.ai.ml.entities import AmlCompute gpu_compute_target = "gpu-cluster" try: # let's see if the compute target already exists gpu_cluster = ml_client.compute.get(gpu_compute_target) print( f"You already have a cluster named , we'll reuse it as is." ) except Exception: print("Creating a new gpu compute target. ") # Let's create the Azure ML compute object with the intended parameters gpu_cluster = AmlCompute( # Name assigned to the compute cluster name="gpu-cluster", # Azure ML Compute is the on-demand VM service type="amlcompute", # VM Family size="STANDARD_NC6s_v3", # Minimum running nodes when there is no job running min_instances=0, # Nodes in cluster max_instances=4, # How many seconds will the node running after the job termination idle_time_before_scale_down=180, # Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination tier="Dedicated", ) # Now, we pass the object to MLClient's create_or_update method gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result() print( f"AMLCompute with name is created, the compute size is " )Создание среды задания
Чтобы запустить задание Машинного обучения Azure, вам потребуется среда. Среда Машинного обучения Azure инкапсулирует зависимости (такие как среда выполнения программного обеспечения и библиотеки), необходимые для запуска сценария обучения машинного обучения в вычислительном ресурсе. Эта среда аналогична среде Python на локальном компьютере.
Машинное обучение Azure позволяет использовать курированную (или готовую) среду или создать настраиваемую среду с помощью образа Docker или конфигурации Conda. В этой статье описано, как создать настраиваемую среду Conda для заданий с помощью YAML-файла Conda.
Создание пользовательской среды
Чтобы создать настраиваемую среду, определите зависимости Conda в ФАЙЛЕ YAML. Сначала создайте каталог для хранения файла. В этом примере мы назвали каталог dependencies .
import os dependencies_dir = "./dependencies" os.makedirs(dependencies_dir, exist_ok=True)Затем создайте файл в каталоге зависимостей. В этом примере мы назвали файл conda.yml .
%%writefile /conda.yaml name: keras-env channels: - conda-forge dependencies: - python=3.8 - pip=21.2.4 - pip: - protobuf~=3.20 - numpy==1.22 - tensorflow-gpu==2.2.0 - kerasСпецификация содержит некоторые обычные пакеты (например, numpy и pip), которые будут использоваться в задании.
Затем используйте YAML-файл, чтобы создать и зарегистрировать эту настраиваемую среду в рабочей области. Среда будет упакована в контейнер Docker во время выполнения.
from azure.ai.ml.entities import Environment custom_env_name = "keras-env" job_env = Environment( name=custom_env_name, description="Custom environment for keras image classification", conda_file=os.path.join(dependencies_dir, "conda.yaml"), image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest", ) job_env = ml_client.environments.create_or_update(job_env) print( f"Environment with name is registered to workspace, the environment version is " )Дополнительные сведения о создании и использовании сред см. в разделе Создание и использование программных сред в Машинном обучении Azure.
Настройка и отправка задания обучения
В этом разделе мы начнем с ознакомления с данными для обучения. Затем мы рассмотрим, как выполнить задание обучения с помощью предоставленного скрипта обучения. Вы научитесь создавать задание обучения, настроив команду для запуска скрипта обучения. Затем вы отправите задание обучения для запуска в Машинном обучении Azure.
Получение данных для обучения
Вы будете использовать данные из базы данных измененных национальных стандартов и технологий (MNIST) рукописных цифр. Эти данные по получению с веб-сайта Yan LeCun и хранятся в учетной записи хранения Azure.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Дополнительные сведения о наборе данных MNIST см. на веб-сайте Yan LeCun.
Подготовка скрипта обучения
В этой статье мы предоставили скрипт обучения keras_mnist.py. На практике вы сможете использовать любой пользовательский скрипт обучения как есть и запускать его с помощью Машинного обучения Azure без необходимости изменять код.
Предоставленный скрипт обучения выполняет следующие действия:
- обрабатывает предварительную обработку данных, разбивая данные на тестовые и обучающие;
- обучает модель, используя данные; И
- возвращает выходную модель.
Во время выполнения конвейера вы будете использовать MLFlow для регистрации параметров и метрик. Сведения о том, как включить отслеживание MLFlow, см. в статье Отслеживание экспериментов и моделей машинного обучения с помощью MLflow.
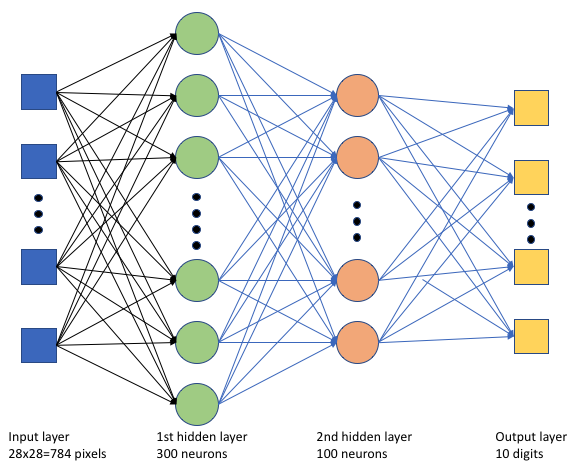
В сценарии keras_mnist.py обучения мы создадим простую глубокую нейронную сеть (DNN). Этот DNN имеет:
- Входной слой с 28 * 28 = 784 нейронами. Каждый нейрон представляет пиксель изображения.
- Два скрытых слоя. Первый скрытый слой имеет 300 нейронов, а второй скрытый слой имеет 100 нейронов.
- Выходной слой с 10 нейронами. Каждый нейрон представляет целевую метку от 0 до 9.
Создание задания обучения
Теперь, когда у вас есть все ресурсы, необходимые для выполнения задания, пришло время создать его с помощью пакета SDK Для Python для Машинного обучения Azure версии 2. В этом примере мы создадим command .
Машинное обучение command Azure — это ресурс, который указывает все сведения, необходимые для выполнения кода обучения в облаке. Эти сведения включают входные и выходные данные, тип используемого оборудования, устанавливаемое программное обеспечение и способ выполнения кода. содержит command сведения для выполнения одной команды.
Настройка команды
Для запуска сценария обучения и выполнения нужных задач вы будете использовать универсальный command скрипт. Создайте объект , Command чтобы указать сведения о конфигурации задания обучения.
from azure.ai.ml import command from azure.ai.ml import UserIdentityConfiguration from azure.ai.ml import Input web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/" job = command( inputs=dict( data_folder=Input(type="uri_folder", path=web_path), batch_size=50, first_layer_neurons=300, second_layer_neurons=100, learning_rate=0.001, ), compute=gpu_compute_target, environment=f":", code="./src/", command="python keras_mnist.py --data-folder $> --batch-size $> --first-layer-neurons $> --second-layer-neurons $> --learning-rate $>", experiment_name="keras-dnn-image-classify", display_name="keras-classify-mnist-digit-images-with-dnn", )- Входные данные для этой команды включают расположение данных, размер пакета, количество нейронов на первом и втором уровнях, а также скорость обучения. Обратите внимание, что мы передали веб-путь непосредственно в качестве входных данных.
- Для значений параметров:
- укажите вычислительный кластер gpu_compute_target = "gpu-cluster" , созданный для выполнения этой команды;
- укажите настраиваемую среду, созданную keras-env для выполнения задания Машинного обучения Azure;
- настройте само действие командной строки— в данном случае команда имеет значение python keras_mnist.py . Вы можете получить доступ к входным и выходным данным в команде с помощью $> нотации;
- настройка метаданных, таких как отображаемое имя и имя эксперимента; где эксперимент является контейнером для всех итераций, которые выполняется в определенном проекте. Все задания, отправленные с одинаковым именем эксперимента, будут перечислены рядом друг с другом в Студия машинного обучения Azure.
отправить задание.
Пришло время отправить задание для выполнения в Машинном обучении Azure. На этот раз вы будете использовать create_or_update в ml_client.jobs .
ml_client.jobs.create_or_update(job)После завершения задание зарегистрирует модель в рабочей области (в результате обучения) и выведет ссылку для просмотра задания в Студия машинного обучения Azure.
Машинное обучение Azure запускает сценарии обучения, копируя весь исходный каталог. Если у вас есть конфиденциальные данные, которые вы не хотите отправлять, используйте файл .ignore или не включайте их в исходный каталог.
Что происходит во время выполнения задания
При выполнении задания оно проходит следующие этапы:
- Подготовка. Создается образ Docker в соответствии с определенной средой. Образ отправляется в реестр контейнеров рабочей области и кэшируется для последующего выполнения. Журналы также передаются в журнал заданий, и их можно просмотреть для отслеживания хода выполнения. Если указана курируемая среда, будет использоваться кэшированный образ, который поддерживается этой курируемой средой.
- Масштабирование. Кластер пытается увеличить масштаб, если для выполнения выполнения требуется больше узлов, чем доступно в настоящее время.
- Выполнение. Все скрипты в папке скриптов src отправляются в целевой объект вычислений, хранилища данных подключаются или копируются, а скрипт выполняется. Выходные данные из stdout и папки ./logs передаются в журнал заданий и могут использоваться для мониторинга задания.
Настройка гиперпараметров модели
Вы обучили модель с помощью одного набора параметров. Теперь давайте посмотрим, можно ли еще больше повысить точность модели. Вы можете настроить и оптимизировать гиперпараметров модели с помощью возможностей sweep Машинного обучения Azure.
Чтобы настроить гиперпараметров модели, определите пространство параметров, в котором будет выполняться поиск во время обучения. Это можно сделать, заменив некоторые параметры ( batch_size , , first_layer_neurons second_layer_neurons и learning_rate ), переданные заданию обучения, специальными входными данными azure.ml.sweep из пакета.
from azure.ai.ml.sweep import Choice, LogUniform # we will reuse the command_job created before. we call it as a function so that we can apply inputs # we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier job_for_sweep = job( batch_size=Choice(values=[25, 50, 100]), first_layer_neurons=Choice(values=[10, 50, 200, 300, 500]), second_layer_neurons=Choice(values=[10, 50, 200, 500]), learning_rate=LogUniform(min_value=-6, max_value=-1), )Затем вы настроите очистку в задании команды, используя некоторые параметры очистки, такие как основная метрика для watch и используемый алгоритм выборки.
В следующем коде мы используем случайную выборку, чтобы попробовать различные наборы конфигураций гиперпараметров в попытке максимизировать нашу основную метрику , validation_acc .
Мы также определяем политику досрочного BanditPolicy завершения — . Эта политика работает путем проверки задания каждые две итерации. Если основная метрика выходит validation_acc за пределы десятипроцентного диапазона, Машинное обучение Azure завершит задание. Это избавляет модель от дальнейшего изучения гиперпараметров, которые не обещают помочь достичь целевой метрики.
from azure.ai.ml.sweep import BanditPolicy sweep_job = job_for_sweep.sweep( compute=gpu_compute_target, sampling_algorithm="random", primary_metric="Accuracy", goal="Maximize", max_total_trials=20, max_concurrent_trials=4, early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2), )Теперь вы можете отправить это задание, как раньше. На этот раз вы будете выполнять задание очистки, которое подметает задание обучения.
returned_sweep_job = ml_client.create_or_update(sweep_job) # stream the output and wait until the job is finished ml_client.jobs.stream(returned_sweep_job.name) # refresh the latest status of the job after streaming returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)Вы можете отслеживать задание с помощью ссылки на пользовательский интерфейс студии, которая отображается во время выполнения задания.
Поиск и регистрация лучшей модели
После завершения всех запусков можно найти запуск, который создал модель с наивысшей точностью.
from azure.ai.ml.entities import Model if returned_sweep_job.status == "Completed": # First let us get the run which gave us the best result best_run = returned_sweep_job.properties["best_child_run_id"] # lets get the model from this run model = Model( # the script stores the model as "keras_dnn_mnist_model" path="azureml://jobs/<>/outputs/artifacts/paths/keras_dnn_mnist_model/".format( best_run ), name="run-model-example", description="Model created from run.", type="mlflow_model", ) else: print( "Sweep job status: <>. Please wait until it completes".format( returned_sweep_job.status ) )Затем можно зарегистрировать эту модель.
registered_model = ml_client.models.create_or_update(model=model)Развертывание модели в качестве подключенной конечной точки
После регистрации модели ее можно развернуть в качестве сетевой конечной точки, то есть в качестве веб-службы в облаке Azure.
Для развертывания службы машинного обучения обычно требуется:
- Ресурсы модели, которые требуется развернуть. К этим ресурсам относятся файл модели и метаданные, которые вы уже зарегистрировали в задании обучения.
- Некоторый код для запуска в качестве службы. Код выполняет модель в заданном входном запросе (входном скрипте). Этот начальный скрипт получает данные, отправленные в развернутую веб-службу, и передает их модели. После того как модель обработает данные, скрипт возвращает клиенту ответ модели. Скрипт предназначен для вашей модели и должен понимать данные, ожидаемые и возвращаемые моделью. При использовании модели MLFlow Машинное обучение Azure автоматически создает этот скрипт.
Создание подключенной конечной точки
В качестве первого шага к развертыванию модели необходимо создать конечную точку в сети. Имя конечной точки должно быть уникальным во всем регионе Azure. В этой статье вы создадите уникальное имя с помощью универсального уникального идентификатора (UUID).
import uuid # Creating a unique name for the endpoint online_endpoint_name = "keras-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import ( ManagedOnlineEndpoint, ManagedOnlineDeployment, Model, Environment, ) # create an online endpoint endpoint = ManagedOnlineEndpoint( name=online_endpoint_name, description="Classify handwritten digits using a deep neural network (DNN) using Keras", auth_mode="key", ) endpoint = ml_client.begin_create_or_update(endpoint).result() print(f"Endpint provisioning state: ")После создания конечной точки ее можно получить следующим образом:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name) print( f'Endpint "" with provisioning state "" is retrieved' )Развертывание модели в конечной точке
После создания конечной точки можно развернуть модель с помощью скрипта записи. Конечная точка может иметь несколько развертываний. Используя правила, конечная точка может направлять трафик в эти развертывания.
В следующем коде вы создадите одно развертывание, которое обрабатывает 100 % входящего трафика. Мы указали произвольное имя цвета (tff-blue) для развертывания. Для развертывания можно также использовать любое другое имя, например tff-green или tff-red . Код для развертывания модели в конечной точке выполняет следующие действия:
- развертывает наилучшую версию модели, зарегистрированную ранее;
- оценивает модель с помощью score.py файла; и
- использует пользовательскую среду (созданную ранее) для вывода.
from azure.ai.ml.entities import ManagedOnlineDeployment, CodeConfiguration model = registered_model # create an online deployment. blue_deployment = ManagedOnlineDeployment( name="keras-blue-deployment", endpoint_name=online_endpoint_name, model=model, # code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"), instance_type="Standard_DS3_v2", instance_count=1, ) blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Ожидается, что это развертывание займет немного времени.
Тестирование развернутой модели
Теперь, когда модель развернута в конечной точке, можно спрогнозировать выходные данные развернутой модели с помощью invoke метода в конечной точке.
Для тестирования конечной точки требуются тестовые данные. Давайте скачивать тестовые данные, которые использовались в нашем сценарии обучения, локально.
import urllib.request data_folder = os.path.join(os.getcwd(), "data") os.makedirs(data_folder, exist_ok=True) urllib.request.urlretrieve( "https://azureopendatastorage.blob.core.windows.net/mnist/t10k-images-idx3-ubyte.gz", filename=os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"), ) urllib.request.urlretrieve( "https://azureopendatastorage.blob.core.windows.net/mnist/t10k-labels-idx1-ubyte.gz", filename=os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"), )Загрузите их в тестовый набор данных.
from src.utils import load_data X_test = load_data(os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"), False) y_test = load_data( os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"), True ).reshape(-1)Выберите 30 случайных выборок из тестового набора и запишите их в JSON-файл.
import json import numpy as np # find 30 random samples from test set n = 30 sample_indices = np.random.permutation(X_test.shape[0])[0:n] test_samples = json.dumps() # test_samples = bytes(test_samples, encoding='utf8') with open("request.json", "w") as outfile: outfile.write(test_samples)Затем можно вызвать конечную точку, распечатать возвращенные прогнозы и отобразить их вместе с входными изображениями. Используйте красный цвет шрифта и инвертированное изображение (белое на черном), чтобы выделить неправильно классифицированные примеры.
import matplotlib.pyplot as plt # predict using the deployed model result = ml_client.online_endpoints.invoke( endpoint_name=online_endpoint_name, request_file="./request.json", deployment_name="keras-blue-deployment", ) # compare actual value vs. the predicted values: i = 0 plt.figure(figsize=(20, 1)) for s in sample_indices: plt.subplot(1, n, i + 1) plt.axhline("") plt.axvline("") # use different color for misclassified sample font_color = "red" if y_test[s] != result[i] else "black" clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color) plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map) i = i + 1 plt.show()Так как точность модели высока, может потребоваться выполнить ячейку несколько раз, прежде чем увидеть неправильно классифицированный образец.
Очистка ресурсов
Если вы не будете использовать конечную точку, удалите ее, чтобы прекратить использование ресурса. Прежде чем удалять конечную точку, убедитесь, что другие развертывания не используют конечную точку.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Ожидается, что эта очистка займет немного времени.
Дальнейшие действия
В этой статье вы обучили и зарегистрировали модель Keras. Вы также развернули модель в подключенной конечной точке. Подробные сведения о Машинном обучении Azure см. в следующих статьях.
- Отслеживание метрик выполнения во время обучения
- Настройка гиперпараметров
- Эталонная архитектура для распределенного обучения с глубоким обучением в Azure
Модули Keras: типы и примеры / keras 7
Модули Keras предоставляют различные классы и алгоритмы глубокого обучения. Дальше о них и пойдет речь.
Модули Keras
В Keras представлены следующие модули:
- Бэкенд
- Утилиты
- Обработка изображений
- Последовательная последовательности
- Обработка текста
- Обратный вызов
Модуль бэкенда в Keras
Keras — это высокоуровневый API, который не заостряет внимание на вычислениях на бэкенде. Однако он позволяет пользователям изучать свой бэкенд и делать изменения на этом уровне. Для этого есть специальный модуль.
Его конфигурация по умолчанию хранится в файле $Home/keras/keras.json .
Он выглядит вот так:
"image_data_format": "channels_last", "epsilon": 1e-07, "floatx": "float32", "backend": "tensorflow" >Можно дописать код, совместимый с этим бэкендом.
from Keras import backend as K b=K.random_uniform_variable(shape=(3,4),low=0,high=1) c=K.random_uniform_variable(shape=(3,4),mean=0,scale=1) d=K.random_uniform_variable(shape=(3,4),mean=0,scale=1) a=b + c * K.abs(d) c=K.dot(a,K.transpose(b)) a=K.sum(b,axis=1) a=K.softmax(b) a=K.concatenate([b,c],axis=1)Модуль утилит в Keras
Этот модуль предоставляет утилиты для операций глубокого обучения. Вот некоторые из них.
HDF5Matrix
Для преобразования входящих данных в формат HDF5.
from.utils import HDF5Matrix data=HDF5Matrix('data.hdf5','data')to_categorical
Для унитарной кодировки (one hot encoding) векторов класса.
from keras.utils import to_categorical labels = [0,1,2,3,4,5] to_categorical(labels)print_summary
Для вывода сводки по модели.
from keras.utils import print_summary print_summary(model)Модуль обработки изображений в Keras
Содержит методы для конвертации изображений в массивы NumPy. Также есть функции для представления данных.
Класс ImageDataGenerator
Используется для дополнения данных в реальном времени.
keras.preprocessing.image.ImageDataGenerator(featurewise_center, samplewise_center, featurewise_std_normalization, samplewise_std_normalization, zca_whitening, zca_epsilon=1e-06, rotation_range=0, width_shift_range=0.0, height_shift_range=0.0, brightness_range, shear_range=0.0, zoom_range=0.0, channel_shift_range=0.0, fill_mode='nearest', cval=0.0, horizontal_flip, vertical_flip)Методы ImageDataGenerator
apply_transform:
Для применения изменений к изображению
apply_transform(x, transform_parameters)flow
Для генерации серий дополнительных данных.
flow(x, y, batch_size=32, shuffle, sample_weight, seed, save_to_dir, save_prefix='', save_format='png', subset)standardize
Для нормализации входящего пакета.
standardize(x)Модуль обработки последовательности
Методы для генерации основанных на времени данных из ввода. Также есть функции для представления данных.
TimeseriesGenerator
Для генерации временных данных.
keras.preprocessing.sequence.TimeseriesGenerator(data, targets, length, sampling_rate, stride, start_index, end_index)skipgrams
Конвертирует последовательность слов в кортежи слов.
keras.preprocessing.sequence.skipgrams(sequence, vocabulary_size, window_size=4, negative_samples=1.0, shuffle, categorical, sampling_table, seed)Модуль предварительной обработки текста
Методы для конвертации текста в массивы NumPy. Есть также методы для подготовки данных.
Tokenizer
Используется для конвертации основного текста в векторы.
keras.preprocessing.text.Tokenizer(num_words, filters='!"#$%&()*+,-./:;?@[\\]^_`<|>~\t\n', lower, split=' ', char_level, oov_token=, document_count=0)one_hot
Для кодировки текста в список слов.
keras.preprocessing.text.one_hot(text, n, filters='!"#$%&()*+,-./:;?@[\\]^_`<|>~\t\n', lower, split=' ')text_to_word_sequence
Для конвертации текста в последовательность слов.
keras.preprocessing.text.text_to_word_sequence(text, filters='!"#$%&()*+,-./:;?@[\\]^_`<|>~\t\n', lower, split=' ')Модуль обратного вызова
Предоставляет функции обратного вызова. Используется для изучения промежуточных результатов.
Callback
Для создания новых обратных вызовов.
keras.callbacks.callbacks.Callback()BaseLogger
Для вычисления среднего значения метрик.
keras.callbacks.callbacks.BaseLogger(stateful_metrics)History
Для записи событий.
keras.callbacks.callbacks.History()ModelCheckpoint
Для сохранения модели после каждого временного промежутка.
keras.callbacks.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only, save_weights_only, mode='auto', period=1)Выводы
Теперь вы знакомы с разными модулями Keras и знаете, для чего они нужны.
Keras
Keras — это библиотека для языка программирования Python, которая предназначена для глубокого машинного обучения. Она позволяет быстрее создавать и настраивать модели — схемы, по которым распространяется и подсчитывается информация при обучении. Но сложных математических вычислений Keras не выполняет и используется как надстройка над другими библиотеками.


Освойте профессию «Data Scientist»
Keras с версии 2.3 — это надстройка над библиотекой TensorFlow, которая нужна для машинного обучения. TensorFlow выполняет все низкоуровневые вычисления и преобразования и служит своеобразным движком, математическим ядром. Keras же управляет моделями, по которым проходят вычисления.
До версии 2.3 Keras мог использовать в качестве движка вычислительные библиотеки Theano или CNTK. Но в новых версиях поддержка прекратилась, теперь библиотека работает только с TensorFlow.
Профессия / 8 месяцев
IT-специалист с нуляПопробуйте 9 профессий за 2 месяца и выберите подходящую вам


Keras создавалась как гибкая модульная библиотека, которую легко настраивать и модифицировать. Она бесплатная, у нее открытый исходный код, который может посмотреть любой желающий.
Название читается как «Керас» и с греческого языка означает «рог». Это отсылка к строкам из «Одиссеи».
Keras имеет узкую специализацию. Это инструмент для специалистов по машинному обучению, которые работают с языком Python: именно его чаще всего используют благодаря удобству математических вычислений. Keras применяют разработчики, которые создают, настраивают и тестируют системы машинного обучения и искусственного интеллекта, в первую очередь нейронные сети.
Для чего нужен Keras
- Удобное построение моделей, по которым будет проходить обучение.
- Настройка слоев в моделях — обычно подбор нужного количества слоев требуется для точности.
- Обработка ввода и вывода информации из модели.
- Преобразование входных данных, которые поступают в обучаемую модель.
- Удобный подбор датасетов для обучения.
- Визуализация модели.
- Подготовка модели к работе, определение ее функций ошибки и оптимизаторов.
- Обучение и тестирование модели.
- Сборка и первичный запуск программы машинного обучения.
Все перечисленное можно делать и без Keras, но дольше и сложнее. Keras выступает как программный интерфейс, который упрощает действия. Некоторые называют его API.
Читайте также Кто такой специалист по машинному обучению
Что такое модель
Keras работает с моделями — схемами, по которым распространяется и преобразуется информация. Машинное обучение — по сути, обработка информации с помощью запрограммированной сети, где на основе определенных данных делаются те или иные выводы. Структура сети называется моделью. Часто ее представляют в виде графа, схемы или таблицы.
Как работает глубокое обучение
Глубокое обучение — это метод машинного обучения, который позволяет предсказывать результат по набору входных данных — например, распознавать объекты. Обычно используются нейронные сети со множеством уровней.
Нейронные сети
Нейронная сеть — программная модель, основанная на структуре человеческой нервной системы. Элементы, которые называются нейронами, соединяются между собой с помощью алгоритмов, передают друг другу данные и изменяются в зависимости от того, что получили на вход. В результате информация интерпретируется тем или иным образом.
Перед началом работы с нейронной сетью ее обучают: подают на вход разные данные и указывают программе, какие выводы нужно сделать из информации. В результате сеть устанавливает соответствие между определенными характеристиками данных и выводами.
Вот пример: при обучении нейронной сети, которая распознает изображения, показали 50 000 картинок, где присутствуют кошки, и указали, что на этих картинках есть кот. Также ей показали столько же картинок, где котов нет, и указали это. Обучение сработало как настройка, и программа накопила достаточно характеристик, чтобы распознавать котов уже на других картинках.
Многослойность
Особенность глубокого обучения в том, что при этом методе используются многослойные сети — это значит, что у них большое количество уровней. На каждом уровне, или слое, находится определенное количество нейронов. Разные слои могут выполнять разные функции.
Например, первый слой получает на вход данные, обрабатывает их определенным образом и отправляет полученный результат на второй слой. Второй слой получит уже не исходные данные, а результат вычислений на первом слое — это обычно набор числовых значений, которые так или иначе отражают характеристики входных данных. Затем процесс повторяется с третьим и последующими слоями вплоть до выхода.
Чаще всего выходные данные — это вероятность, высчитанная нейронной сетью. Она показывает, насколько велик шанс того, что на картинке тот или иной объект.

Станьте аналитиком данных и получите востребованную специальность
Роль библиотек для машинного обучения
Самостоятельные расчеты по такой модели невозможны, а создавать слои вручную — долгий процесс. В современных сетях могут использоваться десятки слоев и тысячи нейронов, и их будет сложно описать самостоятельно. Поэтому для работы с нейронными сетями и глубоким обучением применяют различные инструменты, позволяющие делать это в несколько строчек. Один из таких инструментов — Keras, который быстро создает, визуализирует и запускает сети с заданными параметрами.
Например, вместо того чтобы вручную описывать свойства каждого нейрона, а потом создавать сотню таких элементов в цикле и повторять это для каждого слоя, можно один раз написать инициализацию в Keras. Это несколько строк, которые описывают свойства целевой модели: ее глубину, плотность, механику расчетов и другие параметры. После этого модель можно обучать и собирать.
Читайте также Как написать свою первую нейросеть на Python
Как работать с глубоким обучением в Keras
Создание модели
Описать модель можно двумя способами:
- последовательно — написать несколько команд, каждая из которых добавляет к модели новый параметр. Например, сначала описывается плотность, потом формула для расчетов, потом другие характеристики;
- с помощью функционального API — создать объект и присвоить ему характеристики, описанные и рассчитанные заранее с помощью других функций.
Оба метода довольно удобны, и выбор зависит только от предпочтений программиста.
Обучение
После создания модели ее обучают: подают на вход датасет (набор данных) для обучения. Обычно это два пакета: в одном — подготовленные данные, в другом — метка, то есть «подпись» к данным. Она указывает, что именно представляет собой информация.
Чтобы модель качественно обучилась, нужны большие датасеты — десятки и сотни тысяч примеров, каждому из которых соответствует метка. Создать и подготовить датасет тоже можно с помощью Keras.
Обучение проходит в автоматизированном режиме и может занять много времени. В результате получится обученная модель: сеть «запомнит» ключевые признаки объекта для распознавания. Это сложная система: нейронам присваиваются те или иные коэффициенты в зависимости от того, что именно поступило на вход. Потом коэффициентам определяется вероятность.
Тестирование и запуск
Тестирование — это запуск модели, уже обученной на тестовой выборке. Так называется датасет, в котором данные не повторяют те, что были при обучении. Например, это совершенно другие картинки, на которых тоже присутствуют или отсутствуют кошки. Разработчики смотрят, какие вероятности нейронная сеть указала для тестовых данных, и по результату определяют точность ее работы.
Особенности Keras
- Написана на чистом Python, чтобы код был понятнее и легче поддерживался.
- Работает на большинстве существующих платформ: не только в ОС Windows и Linux, но и на микрокомпьютерах, мобильных устройствах, в облаке или в браузере.
- Поддерживает работу с CPU и GPU — с обычным или графическим процессором. Последний часто используют для сложных вычислений, когда CPU не справляется.
- Поддерживает разные виды нейронных сетей: классические перцептроны, сверточные и рекуррентные сети, их комбинации.
- Совместима с Python начиная с версии 2.7 вплоть до современных.
Преимущества Keras
Keras позиционируется как библиотека, основная цель которой — удобство для человека, а не для машины. Все ее ключевые преимущества вытекают из этой идеи.
Гибкая работа с бэкендом
В старых версиях движок можно было выбирать, сейчас таких возможностей меньше. Но Keras тем не менее полностью сочетается с популярной библиотекой TensorFlow, программисту не нужно придумывать что-то новое, чтобы заставить ее работать как надо. Keras хорошо оптимизирована под TensorFlow, а это облегчает работу программы. Это важно, потому что машинное обучение — очень ресурсоемкое направление, для расчетов нужно много вычислительных мощностей.
Удобство
С Keras удобно работать: она серьезно упрощает создание и настройку моделей. Ее функции и инструменты имеют понятные названия, поэтому код легко читается — по взгляду на него разработчик может понять, что он делает, даже если не слишком хорошо знаком с Keras. Библиотека устроена таким образом, что для решения частых задач нужно выполнить минимальное количество действий — это снимает с разработчика лишнюю нагрузку.
Модульность
Keras состоит из модулей, своеобразных «блоков», у каждого из которых своя функциональность. Эти модули — типовые слои нейронных сетей, функции и схемы. Они представлены в виде уже готовых «элементов», и разработчик собирает из них модель, как в конструкторе. Все, что ему остается, — выбрать модули, назначить им настройки и связать друг с другом. Keras допускает гибкие конфигурации модулей, вариантов построения сетей очень много.
Расширяемость
Функциональность самой библиотеки можно расширять с помощью пользовательских модулей. Если вам понадобится собственный «блок», его легко можно написать самостоятельно и связать с остальными. Keras дает разработчикам такую возможность.
У библиотеки открытый исходный код, поэтому ее можно модифицировать под собственные задачи. Но на практике уже существующие исходники трогают редко; чаще дописывают что-то свое.
Высокая скорость работы
Мы уже частично упомянули это преимущество, когда говорили про упрощение задач. Скорость обеспечивается благодаря двум моментам:
- работать с нейронными сетями становится проще, поэтому разработчик быстрее создает функционирующую модель, обучает и запускает ее. Ему не приходится тратить лишнее время на типовые действия, потому что они сводятся к нескольким строкам кода;
- библиотека быстро развертывает и собирает модели. У ранних версий Keras были проблемы с быстродействием при использовании TensorFlow в качестве движка, но специалисты Google исправили их.
Популярность
У Keras обширное сообщество, это популярная и известная библиотека. Это значит, что у новичка всегда есть возможность пообщаться с единомышленниками, получить от них совет, проконсультироваться на тематическом ресурсе. Мануалов по Keras тоже много, а его документацию энтузиасты перевели на русский язык.
Недостатки Keras
Неуниверсальность
Несмотря на гибкость и расширяемость, разработчикам так и не удалось сделать библиотеку полностью универсальной. Есть задачи, для которых она неоптимальна, в том числе довольно сложные.
Отсутствие обратной совместимости
Старые версии были популярны во многом благодаря возможности выбирать движок самостоятельно. Сейчас возможность убрали, а старые версии не поддерживаются. Функции в новых версиях меняют и переименовывают, поэтому говорить об обратной совместимости нет смысла.
Зависимость от движка
Keras сейчас — это высокоуровневая настройка для TensorFlow. Ее нельзя использовать без движка, в роли которого выступает TensorFlow. Самостоятельно библиотека не сможет провести расчеты — для этого понадобится бэкенд, без которого Keras бесполезна.
Сложность обучения
Это особенность не столько библиотеки, сколько машинного обучения в целом. Сфера сложная и трудоемкая, для ее изучения нужно хорошее понимание математики и теоретических основ. Поэтому машинное обучение имеет высокий порог входа.
Как начать работу с Keras
Основная библиотека
Саму библиотеку можно скачать с помощью одной команды в консоли:
· pip install keras
На компьютере должен быть установлен Python актуальной версии и TensorFlow — бэкенд, без которого Keras не будет работать. Скачать TensorFlow можно на официальном сайте или также с помощью pip.
Для корректной работы TensorFlow понадобятся еще две библиотеки. Это NumPy и SciPy. Они нужны для математических вычислений.
Дополнительные компоненты
Чтобы некоторые возможности Keras работали как надо, нужны дополнительные компоненты. Это другие библиотеки, на которых Keras опирается в работе:
- cuDNN — библиотека от NVIDIA, которая позволяет использовать для расчетов графический процессор. Обычно он отвечает за расчет сложной графики, поэтому лучше подходит для ресурсоемких вычислений машинного обучения;
- Graphviz и Pydot — инструменты, которые нужны для визуализации графов и таблиц. Ими пользуются модули Keras, отвечающие за визуальное отображение моделей. Graphviz — библиотека, Pydot — интерфейс для нее;
- HDF5 и h5py — форматы файлов и соответствующие им библиотеки. В этих форматах хранятся модели. С их помощью Keras сохраняет созданные и настроенные модели.
После установки всех компонентов можно начинать работу с собственными проектами.
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.

Статьи по теме:
Делимся подборкой IT-профессий для креативщиков и математиков, а также лайфхаками, как выбрать подходящую именно вам
Обзор Keras для TensorFlow

tf.keras является реализацией TensorFlow спецификации Keras API. Это высокоуровневый API для построения и обучения моделей включающий первоклассную поддержку для TensorFlow-специфичной функциональности, такой как eager execution, конвейеры tf.data , и Estimators. tf.keras делает использование TensorFlow проще не жертвуя при этом гибкостью и, производительностью.
Для начала, импортируйте tf.keras как часть установки вашей TensorFlow:
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf from tensorflow import kerastf.keras может выполнять любой Keras-совместимый код, но имейте ввиду:
- Версия tf.keras в последнем релизе TensorFlow может отличаться от последней версии keras в PyPI. Проверьте tf.keras.__version__ .
- Когда сохраняете веса моделей, tf.keras делает это по умолчанию в формате checkpoint. Передайте параметр save_format='h5' для использования HDF5 (или добавьте к имени файла расширение .h5 ).
Постройте простую модель
Последовательная модель
В Keras, вы собираете слои (layers) для построения моделей (models). Модель это (обычно) граф слоев. Наиболее распространенным видом модели является стек слоев: модель tf.keras.Sequential .
Построим простую полносвязную сеть (т.е. многослойный перцептрон):
from tensorflow.keras import layers model = tf.keras.Sequential() # Добавим к модели полносвязный слой с 64 узлами: model.add(layers.Dense(64, activation='relu')) # Добавим другой слой: model.add(layers.Dense(64, activation='relu')) # Добавим слой softmax с 10 выходами: model.add(layers.Dense(10, activation='softmax'))Настройте слои
Доступно много разновидностей слоев tf.keras.layers . Большинство из них используют общий конструктор аргументов:
- activation : Установка функции активации для слоя. В этом параметре указывается имя встроенной функции или вызываемый объект. У параметра нет значения по умолчанию.
- kernel_initializer и bias_initializer : Схемы инициализации создающие веса слоя (ядро и сдвиг). В этом параметре может быть имя или вызываемый объект. По умолчанию используется инициализатор "Glorot uniform" .
- kernel_regularizer и bias_regularizer : Схемы регуляризации добавляемые к весам слоя (ядро и сдвиг), такие как L1 или L2 регуляризации. По умолчанию регуляризация не устанавливается.
# Создадим слой с сигмоидой: layers.Dense(64, activation='sigmoid') # Или: layers.Dense(64, activation=tf.keras.activations.sigmoid) # Линейный слой с регуляризацией L1 с коэфициентом 0.01 примененной к матрице ядра: layers.Dense(64, kernel_regularizer=tf.keras.regularizers.l1(0.01)) # Линейный слой с регуляризацией L2 с коэффициентом 0.01 примененной к вектору сдвига: layers.Dense(64, bias_regularizer=tf.keras.regularizers.l2(0.01)) # Линейный слой с ядром инициализированным случайной ортогональной матрицей: layers.Dense(64, kernel_initializer='orthogonal') # Линейный слой с вектором сдвига инициализированным значениями 2.0: layers.Dense(64, bias_initializer=tf.keras.initializers.Constant(2.0))Обучение и оценка
Настройка обучения
После того как модель сконструирована, настройте процесс ее обучения вызовом метода compile :
model = tf.keras.Sequential([ # Добавляем полносвязный слой с 64 узлами к модели: layers.Dense(64, activation='relu', input_shape=(32,)), # Добавляем другой: layers.Dense(64, activation='relu'), # Добавляем слой softmax с 10 выходами: layers.Dense(10, activation='softmax')]) model.compile(optimizer=tf.keras.optimizers.Adam(0.01), loss='categorical_crossentropy', metrics=['accuracy'])tf.keras.Model.compile принимает три важных аргумента:
- optimizer : Этот объект определяет процедуру обучения. Передайте в него экземпляры оптимизатора из модуля tf.keras.optimizers , такие как tf.keras.optimizers.Adam или tf.keras.optimizers.SGD . Если вы просто хотите использовать параметры по умолчанию, вы также можете указать оптимизаторы ключевыми словами, такими как 'adam' или 'sgd' .
- loss : Это функция которая минимизируется в процессе обучения. Среди распространенных вариантов среднеквадратичная ошибка ( mse ), categorical_crossentropy , binary_crossentropy . Функции потерь указываются по имени или передачей вызываемого объекта из модуля tf.keras.losses .
- metrics : Используются для мониторинга обучения. Это строковые имена или вызываемые объекты из модуля tf.keras.metrics .
- Кроме того, чтобы быть уверенным, что модель обучается и оценивается eagerly, проверьте что вы передали компилятору параметр run_eagerly=True
# Сконфигурируем модель для регрессии со среднеквадратичной ошибкой. model.compile(optimizer=tf.keras.optimizers.Adam(0.01), loss='mse', # mean squared error metrics=['mae']) # mean absolute error # Сконфигурируем модель для категориальной классификации. model.compile(optimizer=tf.keras.optimizers.RMSprop(0.01), loss=tf.keras.losses.CategoricalCrossentropy(), metrics=[tf.keras.metrics.CategoricalAccuracy()])Обучение на данных NumPy
Для небольших датасетов используйте помещающиеся в память массивы NumPy для обучения и оценки модели. Модель «обучается» на тренировочных данных, используя метод `fit`:
import numpy as np data = np.random.random((1000, 32)) labels = np.random.random((1000, 10)) model.fit(data, labels, epochs=10, batch_size=32)tf.keras.Model.fit принимает три важных аргумента:
- epochs : Обучение разбито на *эпохи*. Эпоха это одна итерация по всем входным данным (это делается небольшими партиями).
- batch_size : При передаче данных NumPy, модель разбивает данные на меньшие блоки (batches) и итерирует по этим блокам во время обучения. Это число указывает размер каждого блока данных. Помните, что последний блок может быть меньшего размера если общее число записей не делится на размер партии.
- validation_data : При прототипировании модели вы хотите легко отслеживать её производительность на валидационных данных. Передача с этим аргументом кортежа входных данных и меток позволяет модели отображать значения функции потерь и метрики в режиме вывода для передаваемых данных в конце каждой эпохи.
import numpy as np data = np.random.random((1000, 32)) labels = np.random.random((1000, 10)) val_data = np.random.random((100, 32)) val_labels = np.random.random((100, 10)) model.fit(data, labels, epochs=10, batch_size=32, validation_data=(val_data, val_labels))Обучение с использованием наборов данных tf.data
Используйте Datasets API для масштабирования больших баз данных или обучения на нескольких устройствах. Передайте экземпляр `tf.data.Dataset` в метод fit :
# Создает экземпляр учебного датасета: dataset = tf.data.Dataset.from_tensor_slices((data, labels)) dataset = dataset.batch(32) model.fit(dataset, epochs=10)Поскольку Dataset выдает данные пакетами, этот кусок кода не требует аргумента batch_size .
Датасеты могут быть также использованы для валидации:
dataset = tf.data.Dataset.from_tensor_slices((data, labels)) dataset = dataset.batch(32) val_dataset = tf.data.Dataset.from_tensor_slices((val_data, val_labels)) val_dataset = val_dataset.batch(32) model.fit(dataset, epochs=10, validation_data=val_dataset)Оценка и предсказание
Методы tf.keras.Model.evaluate и tf.keras.Model.predict могут использовать данные NumPy и tf.data.Dataset .
Вот так можно оценить потери в режиме вывода и метрики для предоставленных данных:
# С массивом Numpy data = np.random.random((1000, 32)) labels = np.random.random((1000, 10)) model.evaluate(data, labels, batch_size=32) # С датасетом dataset = tf.data.Dataset.from_tensor_slices((data, labels)) dataset = dataset.batch(32) model.evaluate(dataset)А вот как предсказать вывод последнего уровня в режиме вывода для предоставленных данных в виде массива NumPy:
Построение сложных моделей
The Functional API
Модель tf.keras.Sequential это простой стек слоев с помощью которого нельзя представить произвольную модель. Используйте Keras functional API для построения сложных топологий моделей, таких как:
- Модели с несколькими входами,
- Модели с несколькими выходами,
- Модели с общими слоями (один и тот же слой вызывается несколько раз),
- Модели с непоследовательными потоками данных (напр. остаточные связи).
- Экземпляр слоя является вызываемым и возвращает тензор.
- Входные и выходные тензоры используются для определения экземпляра tf.keras.Model
- Эта модель обучается точно так же как и `Sequential` модель.
inputs = tf.keras.Input(shape=(32,)) # Возвращает входной плейсхолдер # Экземпляр слоя вызывается на тензор и возвращает тензор. x = layers.Dense(64, activation='relu')(inputs) x = layers.Dense(64, activation='relu')(x) predictions = layers.Dense(10, activation='softmax')(x)Создайте экземпляр модели с данными входами и выходами.
model = tf.keras.Model(inputs=inputs, outputs=predictions) # Шаг компиляции определяет конфигурацию обучения. model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001), loss='categorical_crossentropy', metrics=['accuracy']) # Обучение за 5 эпох model.fit(data, labels, batch_size=32, epochs=5)Сабклассинг моделей
Создайте полностью настраиваемую модель с помощью сабклассинга tf.keras.Model и определения вашего собственного прямого распространения. Создайте слои в методе __init__ и установите их как атрибуты экземпляра класса. Определите прямое распространение в методе call .
Сабклассинг модели особенно полезен когда включен eager execution, поскольку он позволяет написать прямое распространение императивно.
Примечание: если вам нужно чтобы ваша модель всегда выполнялась императивно, вы можете установить dynamic=True когда вызываете конструктор super .
Ключевой момент: Используйте правильный API для работы. Хоть сабклассинг модели обеспечивает гибкость, за нее приходится платить большей сложностью и большими возможностями для пользовательских ошибок. Если это возможно выбирайте functional API.
Следующий пример показывает сабклассированную модель tf.keras.Model использующую пользовательское прямое распространение, которое не обязательно выполнять императивно:
class MyModel(tf.keras.Model): def __init__(self, num_classes=10): super(MyModel, self).__init__(name='my_model') self.num_classes = num_classes # Определим свои слои тут. self.dense_1 = layers.Dense(32, activation='relu') self.dense_2 = layers.Dense(num_classes, activation='sigmoid') def call(self, inputs): # Определим тут свое прямое распространение, # с использованием ранее определенных слоев (в `__init__`). x = self.dense_1(inputs) return self.dense_2(x)Создайте экземпляр класса новой модели:
model = MyModel(num_classes=10) # Шаг компиляции определяет конфигурацию обучения. model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001), loss='categorical_crossentropy', metrics=['accuracy']) # Обучение за 5 эпох. model.fit(data, labels, batch_size=32, epochs=5)Пользовательские слои
Создайте пользовательский слой сабклассингом tf.keras.layers.Layer и реализацией следующих методов:
- __init__ : Опционально определите подслои которые будут использоваться в этом слое.
- * build : Создайте веса слоя. Добавьте веса при помощи метода add_weight
- call : Определите прямое распространение.
- Опционально, слой может быть сериализован реализацией метода get_config и метода класса from_config .
class MyLayer(layers.Layer): def __init__(self, output_dim, **kwargs): self.output_dim = output_dim super(MyLayer, self).__init__(**kwargs) def build(self, input_shape): # Создадим обучаемую весовую переменную для этого слоя. self.kernel = self.add_weight(name='kernel', shape=(input_shape[1], self.output_dim), initializer='uniform', trainable=True) def call(self, inputs): return tf.matmul(inputs, self.kernel) def get_config(self): base_config = super(MyLayer, self).get_config() base_config['output_dim'] = self.output_dim return base_config @classmethod def from_config(cls, config): return cls(**config)Создайте модель с использованием вашего пользовательского слоя:
model = tf.keras.Sequential([ MyLayer(10), layers.Activation('softmax')]) # Шаг компиляции определяет конфигурацию обучения model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001), loss='categorical_crossentropy', metrics=['accuracy']) # Обучение за 5 эпох. model.fit(data, labels, batch_size=32, epochs=5)Колбеки
Колбек это объект переданный модели чтобы кастомизировать и расширить ее поведение во время обучения. Вы можете написать свой пользовательский колбек или использовать встроенный tf.keras.callbacks который включает в себя:
tf.keras.callbacks.ModelCheckpoint : Сохранение контрольных точек модели за регулярные интервалы.
tf.keras.callbacks.LearningRateScheduler : Динамичное изменение шага обучения.
tf.keras.callbacks.EarlyStopping : Остановка обучения в том случае когда результат при валидации перестает улучшаться.
tf.keras.callbacks.TensorBoard: Мониторинг поведения модели с помощью
TensorBoardДля использования tf.keras.callbacks.Callback , передайте ее методу модели fit :
callbacks = [ # Остановить обучение если `val_loss` перестанет улучшаться в течение 2 эпох tf.keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'), # Записать логи TensorBoard в каталог `./logs` directory tf.keras.callbacks.TensorBoard(log_dir='./logs') ] model.fit(data, labels, batch_size=32, epochs=5, callbacks=callbacks, validation_data=(val_data, val_labels))Сохранение и восстановление
Сохранение только значений весов
Сохраните и загрузите веса модели с помощью tf.keras.Model.save_weights :
model = tf.keras.Sequential([ layers.Dense(64, activation='relu', input_shape=(32,)), layers.Dense(10, activation='softmax')]) model.compile(optimizer=tf.keras.optimizers.Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])# Сохраним веса в файл TensorFlow Checkpoint model.save_weights('./weights/my_model') # Восстановим состояние модели # для этого необходима модель с такой же архитектурой. model.load_weights('./weights/my_model')По умолчанию веса модели сохраняются в формате TensorFlow checkpoint. Веса могут быть также сохранены в формате Keras HDF5 (значение по умолчанию для универсальной реализации Keras):
# Сохранение весов в файл HDF5 model.save_weights('my_model.h5', save_format='h5') # Восстановление состояния модели model.load_weights('my_model.h5')Сохранение только конфигурации модели
Конфигурация модели может быть сохранена — это сериализует архитектуру модели без всяких весов. Сохраненная конфигурация может восстановить и инициализировать ту же модель, даже без кода определяющего исходную модель. Keras поддерживает форматы сериализации JSON и YAML:
# Сериализация модели в формат JSON json_string = model.to_json() json_stringimport json import pprint pprint.pprint(json.loads(json_string))Восстановление модели (заново инициализированной) из JSON:
fresh_model = tf.keras.models.model_from_json(json_string)Сериализация модели в формат YAML требует установки `pyyaml` перед тем как импортировать TensorFlow:
yaml_string = model.to_yaml() print(yaml_string)Восстановление модели из YAML:
fresh_model = tf.keras.models.model_from_yaml(yaml_string)Внимание: сабклассированные модели не сериализуемы, потому что их архитектура определяется кодом Python в теле метода `call`.
Сохранение всей модели в один файл
Вся модель может быть сохранена в файл содержащий значения весов, конфигурацию модели, и даже конфигурацию оптимизатора. Это позволит вам установить контрольную точку модели и продолжить обучение позже с точно того же положения даже без доступа к исходному коду.
# Создадим простую модель model = tf.keras.Sequential([ layers.Dense(10, activation='softmax', input_shape=(32,)), layers.Dense(10, activation='softmax') ]) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(data, labels, batch_size=32, epochs=5) # Сохраним всю модель в файл HDF5 model.save('my_model.h5') # Пересоздадим в точности эту модель включая веса и оптимизатор. model = tf.keras.models.load_model('my_model.h5')Eager execution
Eager execution — это императивное программирование среда которая выполняет операции немедленно. Это не требуется для Keras, но поддерживается tf.keras и полезно для проверки вашей программы и отладки.
Все строящие модели API `tf.keras` совместимы eager execution. И хотя могут быть использованы `Sequential` и functional API, eager execution особенно полезно при сабклассировании модели и построении пользовательских слоев — эти API требуют от вас написание прямого распространения в виде кода (вместо API которые создают модели путем сборки существующих слоев).
Распределение
Множественные GPU
tf.keras модели можно запускать на множестве GPU с использованием tf.distribute.Strategy . Этот API обеспечивает распределенное обучение на нескольких GPU практически без изменений в существующем коде.
На данный момент, tf.distribute.MirroredStrategy единственная поддерживаемая стратегия распределения. MirroredStrategy выполняет репликацию в графах с
синхронным обучением используя all-reduce на одной машине. Для использования ` distribute.Strategy `, вложите инсталляцию оптимизатора, конструкцию и компиляцию модели в ` Strategy ` ` .scope() `, затем обучите модель.Следующий пример распределяет tf.keras.Model между множеством GPU на одной машине.
Сперва определим модель внутри области распределенной стратегии:
strategy = tf.distribute.MirroredStrategy() with strategy.scope(): model = tf.keras.Sequential() model.add(layers.Dense(16, activation='relu', input_shape=(10,))) model.add(layers.Dense(1, activation='sigmoid')) optimizer = tf.keras.optimizers.SGD(0.2) model.compile(loss='binary_crossentropy', optimizer=optimizer) model.summary()Затем обучим модель на данных как обычно:
x = np.random.random((1024, 10)) y = np.random.randint(2, size=(1024, 1)) x = tf.cast(x, tf.float32) dataset = tf.data.Dataset.from_tensor_slices((x, y)) dataset = dataset.shuffle(buffer_size=1024).batch(32) model.fit(dataset, epochs=1)После проверки перевод появится также на сайте Tensorflow.org. Если вы хотите поучаствовать в переводе документации сайта Tensorflow.org на русский, обращайтесь в личку или комментарии. Любые исправления и замечания приветствуются.
- keras
- tensorflow
- машинное обучение
- глубокое обучение
- Python
- Big Data
- Машинное обучение
- Искусственный интеллект
- TensorFlow
- Вычислительный экземпляр Машинного обучения Azure — скачивание или установка не требуется