Распознавание речи
С помощью функции распознавания речи можно вводить данные, указывать действия или команды и выполнять задачи.
Для распознавания речи используется специальная среда выполнения, API распознавания для программирования среды выполнения, готовые грамматики для диктовки и веб-поиска, а также системный пользовательский интерфейс по умолчанию, который помогает пользователям обнаруживать и использовать функции распознавания речи.
Настройка распознавания речи
Для поддержки распознавания речи в приложении пользователь должен подключить и включить микрофон на своем устройстве, а также принять политику конфиденциальности Майкрософт, предоставляющую вашему приложению разрешение на его использование.
Чтобы автоматически запрашивать у пользователя системное диалоговое окно, запрашивающее разрешение на доступ к звуковому каналу микрофона и его использование (пример из примера распознавания речи и синтеза речи, показанного ниже), просто задайте возможность устройстваМикрофон в манифесте пакета приложения. Дополнительные сведения см. в разделе Объявления возможностей приложений.

Если пользователь нажимает кнопку Да, чтобы предоставить доступ к микрофону, ваше приложение будет добавлено в список утвержденных приложений на странице Параметры —> Конфиденциальность —> Микрофон. Однако, так как пользователь может отключить этот параметр в любое время, необходимо убедиться, что приложение имеет доступ к микрофону, прежде чем пытаться использовать его.
Если вы также хотите поддерживать диктовку, Кортану или другие службы распознавания речи (например, предопределенную грамматику , определенную в ограничении темы), необходимо также убедиться, что функция распознавания речи в Интернете (Параметры —> Конфиденциальность —> Речь) включена.
В этом фрагменте кода показано, как приложение может проверка наличия микрофона и разрешения на его использование.
public class AudioCapturePermissions < // If no microphone is present, an exception is thrown with the following HResult value. private static int NoCaptureDevicesHResult = -1072845856; /// /// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle /// the Cortana/Dictation privacy check. /// /// You should perform this check every time the app gets focus, in case the user has changed /// the setting while the app was suspended or not in focus. /// /// True, if the microphone is available. public async static Task RequestMicrophonePermission() < try < // Request access to the audio capture device. MediaCaptureInitializationSettings settings = new MediaCaptureInitializationSettings(); settings.StreamingCaptureMode = StreamingCaptureMode.Audio; settings.MediaCategory = MediaCategory.Speech; MediaCapture capture = new MediaCapture(); await capture.InitializeAsync(settings); >catch (TypeLoadException) < // Thrown when a media player is not available. var messageDialog = new Windows.UI.Popups.MessageDialog("Media player components are unavailable."); await messageDialog.ShowAsync(); return false; >catch (UnauthorizedAccessException) < // Thrown when permission to use the audio capture device is denied. // If this occurs, show an error or disable recognition functionality. return false; >catch (Exception exception) < // Thrown when an audio capture device is not present. if (exception.HResult == NoCaptureDevicesHResult) < var messageDialog = new Windows.UI.Popups.MessageDialog("No Audio Capture devices are present on this system."); await messageDialog.ShowAsync(); return false; >else < throw; >> return true; > > /// /// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle /// the Cortana/Dictation privacy check. /// /// You should perform this check every time the app gets focus, in case the user has changed /// the setting while the app was suspended or not in focus. /// /// True, if the microphone is available. IAsyncOperation^ AudioCapturePermissions::RequestMicrophonePermissionAsync() < return create_async([]() < try < // Request access to the audio capture device. MediaCaptureInitializationSettings^ settings = ref new MediaCaptureInitializationSettings(); settings->StreamingCaptureMode = StreamingCaptureMode::Audio; settings->MediaCategory = MediaCategory::Speech; MediaCapture^ capture = ref new MediaCapture(); return create_task(capture->InitializeAsync(settings)) .then([](task previousTask) -> bool < try < previousTask.get(); >catch (AccessDeniedException^) < // Thrown when permission to use the audio capture device is denied. // If this occurs, show an error or disable recognition functionality. return false; >catch (Exception^ exception) < // Thrown when an audio capture device is not present. if (exception->HResult == AudioCapturePermissions::NoCaptureDevicesHResult) < auto messageDialog = ref new Windows::UI::Popups::MessageDialog("No Audio Capture devices are present on this system."); create_task(messageDialog->ShowAsync()); return false; > throw; > return true; >); > catch (Platform::ClassNotRegisteredException^ ex) < // Thrown when a media player is not available. auto messageDialog = ref new Windows::UI::Popups::MessageDialog("Media Player Components unavailable."); create_task(messageDialog->ShowAsync()); return create_task([] ); > >); > var AudioCapturePermissions = WinJS.Class.define( function () < >, <>, < requestMicrophonePermission: function () < /// /// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle /// the Cortana/Dictation privacy check. /// /// You should perform this check every time the app gets focus, in case the user has changed /// the setting while the app was suspended or not in focus. /// /// True, if the microphone is available. return new WinJS.Promise(function (completed, error) < try < // Request access to the audio capture device. var captureSettings = new Windows.Media.Capture.MediaCaptureInitializationSettings(); captureSettings.streamingCaptureMode = Windows.Media.Capture.StreamingCaptureMode.audio; captureSettings.mediaCategory = Windows.Media.Capture.MediaCategory.speech; var capture = new Windows.Media.Capture.MediaCapture(); capture.initializeAsync(captureSettings).then(function () < completed(true); >, function (error) < // Audio Capture can fail to initialize if there's no audio devices on the system, or if // the user has disabled permission to access the microphone in the Privacy settings. if (error.number == -2147024891) < // Access denied (microphone disabled in settings) completed(false); >else if (error.number == -1072845856) < // No recording device present. var messageDialog = new Windows.UI.Popups.MessageDialog("No Audio Capture devices are present on this system."); messageDialog.showAsync(); completed(false); >else < error(error); >>); > catch (exception) < if (exception.number == -2147221164) < // REGDB_E_CLASSNOTREG var messageDialog = new Windows.UI.Popups.MessageDialog("Media Player components not available on this system."); messageDialog.showAsync(); return false; >> >); > >) Распознавание речевого ввода
В ограничении определяются слова и фразы (словарь), которые приложение распознает в речевом вводе. Ограничения являются основой распознавания речи и дают приложению больший контроль над точностью распознавания речи.
Для распознавания речевых данных можно использовать следующие типы ограничений.
Предопределенные грамматики
Предопределенные грамматики диктовки и веб-поиска обеспечивают распознавание речи в приложении без необходимости создавать грамматику. Когда используются эти грамматики, распознавание речи выполняется удаленной веб-службой, а результаты возвращаются на устройство.
Стандартная грамматика для диктовки в свободной форме может распознавать большинство слов и фраз, произносимых пользователем на данном языке, и оптимизирована для распознавания коротких фраз. Предопределенная грамматика для диктовки используется, если для объекта SpeechRecognizer не заданы никакие ограничения. Диктовка в свободной форме удобна, если не нужно ограничивать область высказываний пользователя. Обычно она используется для создания текстов заметок и диктовки сообщений.
Грамматика веб-поиска, например грамматика диктовки, содержит большое количество слов и фраз, которые пользователь может произнести. Однако она оптимизирована для распознавания терминов, которыми люди обычно используются, выполняя поиск в Интернете.
Поскольку предопределенные грамматики для диктовки и веб-поиска могут иметь большой размер и размещаются в сети (а не на устройстве), они могут уступать в производительности настраиваемым грамматикам, установленным на устройстве.
Эти предопределенные грамматики можно использовать для распознавания до ввода речи продолжительностью до 10 секунд, и для этого не потребуется никаких доработок с вашей стороны. Однако потребуется подключение к сети.
Чтобы использовать ограничения веб-службы, необходимо включить поддержку голосового ввода и диктовки в параметрах , включив параметр «Знакомство со мной» в разделе Параметры —> конфиденциальность —> речь, рукописный ввод и ввод.
Здесь показано, как проверить, включен ли голосовой ввод, и если нет, как открыть страницу Параметры -> Конфиденциальность -> Голосовые функции, рукописный ввод и ввод с клавиатуры.
Сначала мы инициализируем глобальную переменную (HResultPrivacyStatementDeclined) до значения HResult 0x80045509. См . раздел Обработка исключений для в C# или Visual Basic.
private static uint HResultPrivacyStatementDeclined = 0x80045509; Затем мы отберем все стандартные исключения во время распознавания и проверим, равно ли значение HResult значению переменной HResultPrivacyStatementDeclined. При положительном результате мы отобразим предупреждение и вызовем await Windows.System.Launcher.LaunchUriAsync(new Uri(«ms-settings:privacy-accounts»)); , чтобы открыть страницу «Параметры».
catch (Exception exception) < // Handle the speech privacy policy error. if ((uint)exception.HResult == HResultPrivacyStatementDeclined) < resultTextBlock.Visibility = Visibility.Visible; resultTextBlock.Text = "The privacy statement was declined." + "Go to Settings ->Privacy -> Speech, inking and typing, and ensure you" + "have viewed the privacy policy, and 'Get To Know You' is enabled."; // Open the privacy/speech, inking, and typing settings page. await Windows.System.Launcher.LaunchUriAsync(new Uri("ms-settings:privacy-accounts")); > else < var messageDialog = new Windows.UI.Popups.MessageDialog(exception.Message, "Exception"); await messageDialog.ShowAsync(); >> Ограничения программных списков
Программные ограничения-списки представляют упрощенный подход к созданию простой грамматики с использованием списка слов или фраз. Для распознавания коротких четких фраз удобно использовать ограничения-списки. Явно указание всех слов в грамматике также повышается точность распознавания, так как подсистема распознавания речи должна обрабатывать голосовые данные только в рамках подтверждения соответствия. Список можно также обновлять программными средствами.
Ограничение-список состоит из массива строк, представляющих ввод речи, принимаемый приложением для операции распознавания. Чтобы создать ограничение-список в приложении, создайте объект ограничения-списка для распознавания речи и передайте ему массив строк. Затем добавьте этот объект в коллекцию ограничений распознавателя. Когда распознаватель речи распознает любую из строк в массиве, распознавание завершается успешно.
Грамматики SRGS
Грамматика SRGS – это статический документ, который, в отличие от программного ограничения-списка, использует формат XML, определенный в спецификации SRGS Version 1.0. Грамматика SRGS предоставляет больший контроль над распознаванием речи и позволяет создавать несколько семантических значений в одном распознавании.
Ограничения голосовых команд
С помощью XML-файлов определения голосовых команд можно задать команды, которые пользователь может произносить, чтобы выполнять определенные действия при активации вашего приложения. Дополнительные сведения см. в статье Активация приложения переднего плана с помощью голосовых команд через Кортану.
Примечание Тип используемого типа ограничения зависит от сложности создаваемого интерфейса распознавания. Каждый может оказаться наилучшим для конкретной задачи распознавания, и в приложении может найтись место всем типам ограничений. Сведения об ограничениях см. в статье Определение настраиваемых ограничений распознавания.
Предопределенная грамматика универсального приложения для Windows для диктовки распознает большинство слов и коротких фраз в заданном языке. По умолчанию она активируется, когда создается экземпляр объекта распознавателя речи без настраиваемых ограничений.
В этом разделе мы покажем, как:
- Создать распознаватель речи.
- Скомпилировать ограничения универсального приложения для Windows по умолчанию (в набор грамматик распознавателя речи не добавлены грамматики).
- Начать прослушивание речи с помощью простого интерфейса распознавания и результатов преобразования текста в речь, передаваемых методом RecognizeWithUIAsync. Если пользовательский интерфейс по умолчанию не требуется, используйте метод RecognizeAsync.
private async void StartRecognizing_Click(object sender, RoutedEventArgs e) < // Create an instance of SpeechRecognizer. var speechRecognizer = new Windows.Media.SpeechRecognition.SpeechRecognizer(); // Compile the dictation grammar by default. await speechRecognizer.CompileConstraintsAsync(); // Start recognition. Windows.Media.SpeechRecognition.SpeechRecognitionResult speechRecognitionResult = await speechRecognizer.RecognizeWithUIAsync(); // Do something with the recognition result. var messageDialog = new Windows.UI.Popups.MessageDialog(speechRecognitionResult.Text, "Text spoken"); await messageDialog.ShowAsync(); >Настройка пользовательского интерфейса распознавания
Когда ваше приложение пытается распознать речь при помощи вызова SpeechRecognizer.RecognizeWithUIAsync, отображаются несколько экранов в следующем порядке.
Если вы используете ограничение на базе предварительно заданной грамматики (диктовки или веб-поиска):
Если вы используете ограничение на базе списка слов или фраз или ограничение на базе грамматического файла SRGS:
- Экран Слушаю.
- Экран Вы сказали, если сказанное пользователем можно интерпретировать по-разному.
- Экран Я услышал или экран ошибки.
На следующем изображении представлен пример потока между экранами распознавателя речи, использующего ограничение на базе грамматического файла SRGS. В этом примере распознавание речи прошло успешно.
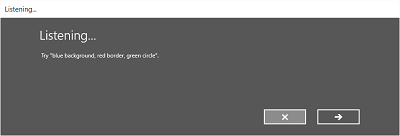
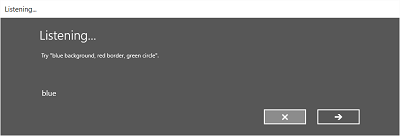
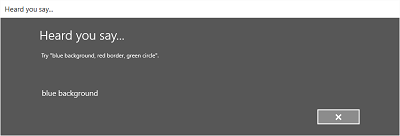
Экран Слушаю может предоставлять примеры слов или фраз, которые приложение может распознать. Здесь мы покажем, как использовать свойства класса SpeechRecognizerUIOptions (его можно получить, вызвав свойство SpeechRecognizer.UIOptions) для настройки содержимого на экране Слушаю.
private async void WeatherSearch_Click(object sender, RoutedEventArgs e) < // Create an instance of SpeechRecognizer. var speechRecognizer = new Windows.Media.SpeechRecognition.SpeechRecognizer(); // Listen for audio input issues. speechRecognizer.RecognitionQualityDegrading += speechRecognizer_RecognitionQualityDegrading; // Add a web search grammar to the recognizer. var webSearchGrammar = new Windows.Media.SpeechRecognition.SpeechRecognitionTopicConstraint(Windows.Media.SpeechRecognition.SpeechRecognitionScenario.WebSearch, "webSearch"); speechRecognizer.UIOptions.AudiblePrompt = "Say what you want to search for. "; speechRecognizer.UIOptions.ExampleText = @"Ex. 'weather for London'"; speechRecognizer.Constraints.Add(webSearchGrammar); // Compile the constraint. await speechRecognizer.CompileConstraintsAsync(); // Start recognition. Windows.Media.SpeechRecognition.SpeechRecognitionResult speechRecognitionResult = await speechRecognizer.RecognizeWithUIAsync(); //await speechRecognizer.RecognizeWithUIAsync(); // Do something with the recognition result. var messageDialog = new Windows.UI.Popups.MessageDialog(speechRecognitionResult.Text, "Text spoken"); await messageDialog.ShowAsync(); >Похожие статьи
Примеры
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.
SpeechRecognition
Экспериментальная возможность: Это экспериментальная технология
Так как спецификация этой технологии ещё не стабилизировалась, смотрите таблицу совместимости по поводу использования в различных браузерах. Также заметьте, что синтаксис и поведение экспериментальной технологии может измениться в будущих версиях браузеров, вслед за изменениями спецификации.
Интерфейс Распознавание голоса Web Speech API является интерфейсом контроллера для сервиса распознавания; который так же перехватывает событие SpeechRecognitionEvent (en-US), отправленное сервисом распознавания.
Конструктор
Создаёт новый объект SpeechRecognition .
Свойства
SpeechRecognition наследует свойства от своего родительского интерфейса, EventTarget .
Возвращает и устанавливает коллекцию объектов SpeechGrammar грамматики которые будут понятны текущему SpeechRecognition .
Задаёт и возвращает язык текущего SpeechRecognition . Если данное свойство не указано по умолчанию, то используется из HTML кода значение атрибута lang , или настройки языка агента текущего пользователя.
Проверяет возвращается ли непрерывные результаты или вернулся только один. По умолчанию для одиночного значение ( false .)
Контроллирует, следует ли возвращать промежуточные результаты ( true ) или нет ( false .) Промежуточные результаты это результаты которые ещё не завершены ( например SpeechRecognitionResult.isFinal (en-US) свойство ложно.)
Устанавливает максимальное количество предоставленных результатов SpeechRecognitionAlternative (en-US). По умолчанию значение 1.
Определяет местоположение службы распознавания речи, используемой текущим SpeechRecognition, для обработки фактического распознавания. По умолчанию используется речевая служба агента пользователя.
Обработчики событий
Вызывается когда пользовательский агент начал захват аудио.
Вызывается когда пользовательский агент закончил захват аудио.
Вызывается когда служба распознавания речи отключилась.
Вызывается когда произошла ошибка распознавания речи.
Вызывается, когда служба распознавания речи возвращает окончательный результат без существенного распознавания. Это может включать определённую степень признания confidence (en-US) которая не соответствует пороговому значению или превышает его.
Вызывается когда возвращает результат — слово или фраза были распознаны положительно, и это было передано обратно в приложение.
Вызывается при обнаружении любого звука — не важно, распознана речь или нет.
Вызывается когда любой звук — распознаваемая речь или нет — перестала распознаваться.
Вызывается, когда обнаружен звук, распознаваемый службой распознавания речи как речевой сигнал.
Вызывается, когда прекращается обнаружение речи, распознанной службой распознавания речи.
Вызывается, когда служба распознавания речи начинает обрабатывать входящий звук с намерением распознать грамматики, связанные с текущим распознаванием речи.
Методы
Распознавание речи также наследует методы от своего родительского интерфейса, EventTarget .
Останавливает обработку входящего аудио службой распознавания речи и не пытается вернуть SpeechRecognitionResult (en-US).
Запускает службу распознавания речи, прослушивая входящее аудио с целью распознавания грамматик, связанных с текущим распознаванием речи.
Останавливает обработку входящего аудио службой распознавания речи и пытается вернуть SpeechRecognitionResult (en-US) Используя уже записанный звук.
Примеры
В нашем простом примере Speech color changer , мы создаём новый объект экземпляра SpeechRecognition используя этот конструктор SpeechRecognition() (en-US) , создание нового SpeechGrammarList (en-US), И установить его в качестве грамматики, которая будет распознаваться экземпляром распознавание речи с использованием свойства SpeechRecognition.grammars (en-US).
После определения некоторых других значений мы затем устанавливаем их так, чтобы служба распознавания началась когда произошло событие по клику ( SpeechRecognition.start() (en-US).) Когда результат был успешно распознан, the SpeechRecognition.onresult (en-US) обработчик извлекаем цвет, который был произнесён из события, а затем меняем цвет фона на данный цвет .
var grammar = "#JSGF V1.0; grammar colors; public = aqua | azure | beige | bisque | black | blue | brown | chocolate | coral | crimson | cyan | fuchsia | ghostwhite | gold | goldenrod | gray | green | indigo | ivory | khaki | lavender | lime | linen | magenta | maroon | moccasin | navy | olive | orange | orchid | peru | pink | plum | purple | red | salmon | sienna | silver | snow | tan | teal | thistle | tomato | turquoise | violet | white | yellow ;"; var recognition = new SpeechRecognition(); var speechRecognitionList = new SpeechGrammarList(); speechRecognitionList.addFromString(grammar, 1); recognition.grammars = speechRecognitionList; //recognition.continuous = false; recognition.lang = "en-US"; recognition.interimResults = false; recognition.maxAlternatives = 1; var diagnostic = document.querySelector(".output"); var bg = document.querySelector("html"); document.body.onclick = function () recognition.start(); console.log("Ready to receive a color command."); >; recognition.onresult = function (event) var color = event.results[0][0].transcript; diagnostic.textContent = "Result received: " + color; bg.style.backgroundColor = color; >;
Спецификации
| Specification |
|---|
| Web Speech API # speechreco-section |
Совместимость с браузерами
BCD tables only load in the browser
Что такое преобразование речи в текст?

Преобразование речи в текст – это программное обеспечение для распознавания речи, которое позволяет распознавать и переводить устную речь в текст с помощью компьютерной лингвистики. Сервис также известен как «распознавание речи» или «компьютерное распознавание речи». Определенные приложения, инструменты и устройства могут расшифровывать аудиопотоки в режиме реального времени для отображения текста и выполнения с ним каких-либо действий.
Как работает преобразование речи в текст?
Преобразование речи в текст – это ПО, которое после прослушивания аудио предоставляет редактируемую дословную расшифровку на используемом устройстве. Для этого сервис использует функцию распознавания речи. Компьютерная программа использует лингвистические алгоритмы для сортировки звуковых сигналов из произнесенных слов и преобразования этих сигналов в текст с использованием символов, называемых «Юникод». Преобразование речи в текст осуществляется с помощью сложной модели машинного обучения, состоящей из нескольких шагов. Подробное описание см. ниже.
- Звуки, произносимые человеком, создает ряд вибраций. Технология преобразования речи в текст улавливает эти вибрации и переводит их на цифровой язык с помощью аналого-цифрового преобразователя.
- Аналого-цифровой преобразователь извлекает звуки из аудиофайла, тщательно измеряет волны и фильтрует их, чтобы вычленить соответствующие звуки.
- Затем звуки сегментируются на сотые или тысячные доли секунды, после чего сопоставляются с фонемами. Фонема – это звуковая единица, которая отличает одно слово от другого в любом используемом языке. Например, в английском языке около 40 фонем.
- Затем фонемы пропускаются через сеть на основе математической модели, которая сравнивает их с хорошо известными предложениями, словами и фразами.
- Затем текст представляется в виде текста или компьютерного запроса на основе наиболее вероятной версии аудио.
Какие типы преобразования речи в текст существуют?
Существует два основных типа преобразования речи в текст.
- Зависимое от диктора: используется в основном для ПО для диктовки.
- Независимое от диктора: часто используется для мобильных приложений.
Две описанные системы распознавания речи основаны на ПО и сервисы для надлежащего функционирования при этом главным типом является встроенная технология диктовки. Многие современные устройства, такие как ноутбуки, смартфоны и планшеты, оснащены встроенными инструментами для диктовки, такие как ноутбуки, смартфоны и планшеты.
Где используется преобразование речи в текст?
Преобразование речи в текст быстро перешло от рутинного использования на телефонах в бытовых условиях к приложениям в таких отраслях, как маркетинг, банковское дело и медицина. Приложения для распознавания речи демонстрируют, как технология преобразования речи в текст может повысить эффективность простых задач и применяться к тем задачам, которые традиционно выполнялись человеком.
Аналитика звонка и помощь операторам
Использование такого инструмента, как Transcribe Call Analytics, позволяет быстро извлекать полезную информацию из разговоров с клиентами, что усовершенствует взаимодействие с клиентами и повышает производительность агентов.
Поиск медиаконтента
Приложение Amazon Transcribe преобразует аудио- и видеоресурсы в доступные для поиска архивы. Кроме того, таким образом пользователи могут расширить охват и доступность контента за счет создания локализованных субтитров в сочетании с Amazon Translate.
Маркетинг является одной из ведущих отраслей, использующих преобразование речи в текст посредством поиска по медиаконтенту. Внедрение голосового поиска позволяет маркетологам получать информацию о поведении потребителей и тенденциях в данных.
Например, распознавание речи предоставляет информацию об акцентах и словарном запасе людей, интерпретируя возраст, местонахождение и другие важные демографические данные. Разговорная речь также является гораздо более диалоговым режимом поиска, позволяющим маркетологам использовать диалоговые ключевые слова, чтобы прогнозировать тенденции.
Медиасубтитры
Сервис Amazon Transcribe также позволяет записывать встречи и беседы с помощью функции цифровой записи, повышая производительность, доступность и оптимизируя важные примечания.
Клинические документы
Сервис Amazon Transcribe Medical – это инструмент для быстрой и эффективной записи разговоров с пациентами, чтобы анализировать или вносить данные в электронную карту здоровья. Например, в банковском деле преобразование речи в текст используется для голосового обслуживания клиентов. В сфере здравоохранения преобразование речи в текст помогает повысить эффективность, обеспечивая немедленный доступ к информации и вводу данных.
Для чего необходимо использовать преобразование речи в текст?
Как и все виды технологий, преобразование речи в текст имеет множество преимуществ, которые помогают улучшать рутинные процессы. Примеры некоторых основных преимуществ см. ниже.
- Экономия времени. Технология автоматического распознавания речи позволяет экономить время путем предоставления точных расшифровок в режиме реального времени.
- Рентабельность. Большинство программ для преобразования речи в текст предусматривают плату за подписку, тогда как некоторые услуги предоставляются бесплатно. Однако стоимость подписки гораздо более рентабельна, чем использование услуг ручной расшифровки.
- Повышение качества аудио- и видеоконтента. Возможности преобразования речи в текст означают, что аудио- и видеоданные могут быть преобразованы в режиме реального времени для субтитров и быстрой расшифровки видео.
- Оптимизация пользовательского опыта. За счет обработки текстов на естественном языке пользовательский опыт трансформируется: процесс становится более простым, доступным и плавным.
Какие ограничения актуальны для преобразования речи в текст?
Новые технологии, такие как преобразование речи в текст, не лишены недостатков, и это одни из основных ограничений преобразования речи в текст.
- Несовершенство процесса. Хотя технология диктовки является мощным инструментом, она все еще находится на ранней стадии развития, а это означает, что в общей производительности есть некоторые пробелы. Поскольку система воспроизводит только дословный текст, расшифровка может быть неточной или неправильной, при этом некоторые цитаты могут быть пропущены.
- Требуется ручной ввод данных. Поскольку преобразование речи в текст не является абсолютно точным, для оптимального использования требуется ручное редактирование речевых данных.
- Необходимы чистые записи. Чтобы получить качественную расшифровку с помощью ПО для распознавания речи, аудиозапись должна быть четкой и разборчивой. Это означает отсутствие фонового шума и акцентов, обязательно правильное произношение, при этом говорить должен один человек. Кроме того, необходимы голосовые команды для соблюдения пунктуации.
Как выбрать между бесплатным и платным ПО преобразования речи в текст?
Бесплатное ПО преобразования речи в текст пригодится в случае ограниченного бюджета. Однако при необходимости расшифровки большого объема аудиофайлов в текст понадобится более надежное ПО. Платное ПО преобразования речи в текст часто является более точным, быстрым и имеет дополнительные функции и поддержку.
Большинство ПО преобразования речи в текст:
- не имеют качественной технической поддержки;
- не предусматривают высокой скорости и точности;
- обладают ограниченной производительностью;
- требуют дополнительного ручного редактирования.
Как выбрать лучшее ПО преобразования речи в текст?
Ввиду широкого ассортимента выбор лучшего ПО для преобразования речи в текст может быть сложной задачей. Используйте приведенный ниже контрольный список, чтобы оценить различное ПО для преобразования речи в текст и сделать лучший выбор.
- Отсутствие необходимости в дополнительном ПО. Наиболее доступное ПО преобразования речи в текст зависит от подключения к Интернету, а не от дополнительного ПО.
- Гарантированный уровень качества. Все сервисы преобразования речи в текст гарантируют различные степени точности. Некоторые сервисы больше ориентированы на расшифровку, что обеспечивает дополнительную точность.
- Поддержка на нескольких языках. При необходимости поддержки на нескольких языках нужно выбрать ПО преобразования речи в текст, соответствующее применимым языковым требованиям.
- Совместимость приложения. Некоторые сервисы преобразования речи в текст можно добавлять в приложения, что важно для использования ПО на нескольких платформах.
Как использовать Amazon Transcribe для преобразования речи в текст?
С помощью автоматического распознавания речи (ASR) Amazon Transcribe преобразует речь в текст быстро и точно. Сервис Amazon Transcribe предлагает ряд доступных инструментов для различных целей, включая аналитику звонков, медицинские расшифровки, создание субтитров и метаданных для медиаресурсов. Чтобы начать, зарегистрируйте бесплатный аккаунт AWS и приступите к расшифровке с помощью бесплатного преобразования речи в текст уже сегодня.
Распознавание речи
Распознавание речи (англ. Speech Recognition) — процесс преобразования речевого сигнала в цифровую информацию.
Задачей распознавания является сопоставление набору акустических признаков речевого сигнала или наблюдений [math]X(x_1 . x_n)[/math] последовательности слов [math]W(w_1 . w_k)[/math] , имеющих наибольшую вероятность правдоподобия среди всех кандидатов. Для этого используется формула Байеса:
Причем, в процессе распознавания вероятность уже полученных признаков Р(Х) не подлежит оптимизации и знаменатель в формуле не испльзуется:
Классификация систем распознавания речи
Системы распознавания речи классифицируются [1] :
- по размеру словаря (ограниченный набор слов, словарь большого размера);
- по зависимости от диктора (дикторозависимые и дикторонезависимые системы);
- по типу речи (слитная или раздельная речь);
- по назначению (системы диктовки, командные системы);
- по используемому алгоритму (нейронные сети, скрытые Марковские модели, динамическое программирование);
- по типу структурной единицы (фразы, слова, фонемы, дифоны, аллофоны);
- по принципу выделения структурных единиц (распознавание по шаблону, выделение лексических элементов).
Структура систем распознавания речи
Системы распознавания речи впервые появились в 1952 году. С тех пор методы распознавания не раз менялись. Ранее использовались такие методы и алгоритмы, как:
- Динамическое программирование (Dynamic Time Warping) — временные динамические алгоритмы, выполняющие классификацию на основе сравнения с эталоном.
- Методы дискриминантного анализа, основанные на Байесовской дискриминации (Bayesian discrimination).
- Скрытые Марковские Модели (Hidden Markov Model).
- Нейронные сети (Neural Networks).
В настоящее время, перечисленные выше методы как правило комбинируются. Их сочетание позволяет получить более высокое качество распознавания, чем использование каждой модели отдельно.
Системы распознавания речи имеют следующие основные модули:
- Акустическая модель
- Языковая модель
- Декодер
Акустическая модель
Фонема (phoneme) — элементарная единица человеческой речи. Примерами фонем являются транскрипции в формате IPA — так, слово hello состоит из фонем [hɛˈləʊ].
Акустическая модель — это функция, принимающая на вход признаки на небольшом участке акустического сигнала (фрейме) и выдающая распределение вероятностей различных фонем на этом фрейме. Таким образом, акустическая модель дает возможность по звуку восстановить, что было произнесено — с той или иной степенью уверенности.
Самой популярной реализацией акустической модели является скрытая Марковская модель (СММ), в которой скрытыми состояниями являются фонемы, а наблюдениями — распределения вероятностей признаков на фрейме.
Рассмотрим подробнее акустическую модель на основе СММ для слова six:
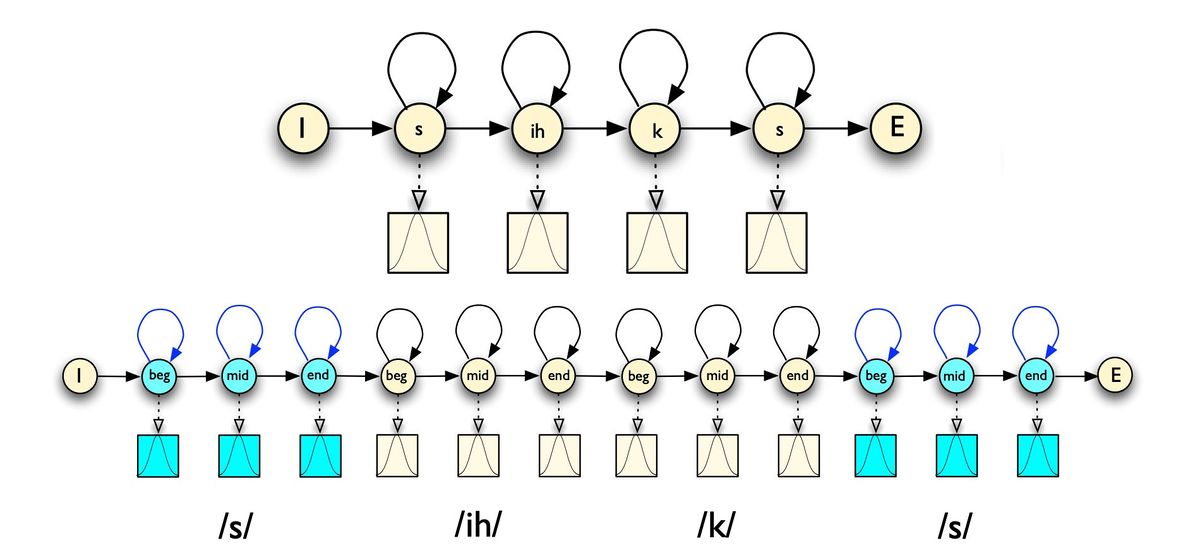
Рисунок 1. Акустическая модель для слова six. Источник
В круглых (скрытых) состояниях изображены фонемы, а в квадратных (наблюдениях) — распределения вероятностей признаков (для упрощения, здесь изображено одномерное распределение). Фонемы часто разбивают на 3 этапа — начало, середину и конец, — потому что фонема может звучать по-разному в зависимости от момента времени её произнесения. Каждое скрытое состояние содержит переход само в себя, так как время произнесения одной фонемы может занять несколько фреймов. Вероятности перехода между фонемами в СММ являются обучаемыми параметрами, и для их настройки используют алгоритм Баума-Велша. Последовательность фонем по набору распределений на фреймах восстанавливают по алгоритму Витерби.
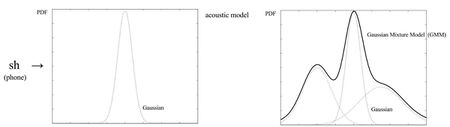
Рисунок 2. Отличие нормального распределения от GMM. Источник
В качестве функции распределения вероятностей признаков часто выбирают смешанную гауссову модель (англ. Gaussian Mixture Model, GMM): дело в том, что одна и та же фонема может звучать по-разному, например, в зависимости от акцента. Так как эта функция является по сути суммой нескольких нормальных распределений, она позволяет учесть различные звучания одной и той же фонемы.
Языковая модель
Языковая модель — позволяет узнать, какие последовательности слов в языке более вероятны, а какие менее. Здесь в самом простом случае требуется предсказать следующее слово по известным предыдущим словам. В традиционных системах применялись модели типа N-грамм, в которых на основе большого количества текстов оценивались распределения вероятности появления слова в зависимости от N предшествующих слов. Для получения надежных оценок распределений параметр N должен быть достаточно мал: одно, два или три слова — модели униграмм, биграмм или триграмм соответственно. Внедрение языковой модели в систему распознавания речи позволило значительно повысить качество распознавания за счет учета контекста.
Декодер
В ходе работы системы автоматического распознавания речи задача распознавания сводится к определению наиболее вероятной последовательности слов, соответствующих содержанию речевого сигнала. Наиболее вероятный кандидат должен определяться с учетом как акустической, так и лингвистической информации. Это означает, что необходимо производить эффективный поиск среди возможных кандидатов с учетом различной вероятностной информации. При распознавании слитной речи число таких кандидатов огромно, и даже использование самых простых моделей приводит к серьезным проблемам, связанным с быстродействием и памятью систем. Как результат, эта задача выносится в отдельный модуль системы автоматического распознавания речи, называемый декодером. Декодер должен определять наиболее грамматически вероятную гипотезу для неизвестного высказывания – то есть определять наиболее вероятный путь по сети распознавания, состоящей из моделей слов (которые, в свою очередь, формируются из моделей отдельных фонов). Правдоподобие (likelihood) гипотезы определяется двумя факторами, а именно вероятностями последовательности фонов, приписываемыми акустической моделью, и вероятностями следования слов друг за другом, определяемыми моделью языка.
Рассмотрим математическую основу декодеров.
Отбрасывая несущественный на этапе распознавания знаменатель, запишем:
[math]W = argmax [P(W)P(XW)][/math]
где [math]X = x_1^T = x_1 . x_N[/math] – последовательность векторов признаков входного сигнала, [math]W = w_1^n = w_1 . w_n[/math] – последовательность слов, принадлежащих словарю размером [math]N_W[/math] . Первый множитель P(W) описывает вклад лингвистического модуля, второй P(X|W) – лексического, фонетического и акустического источников знаний. В соответствии с концепцией марковских цепей, второй множитель представляет собой сумму вероятностей всех возможных последовательностей состояний, что приводит к уравнению:
[math]W = argmax [P(W)\sum_ P(x_1^T, s_1^T | w_1^N)][/math]
где [math]s_1^T[/math] – одна из последовательностей состояний, порождаемых последовательностью слов [math]w_1^n[/math] . На практике применяется критерий Витерби [2] . – ищется последовательность состояний, дающая максимальный вклад в сумму:
[math]W = argmax[P(W)^aMax[P(x_1^T, s_1^T | w_1^N)]][/math]
Различают систему раннего и систему позднего предсказания. В первой выполняется предсказание для акустической и языковой модели независимо, а затем оба предсказания поступают в декодер. При позднем предсказании, вычисленные признаки речи в акустической и языковой моделях без предсказания поступают в декодер и уже на основе их совместного декодирования выполняется предсказание.
- Обработка речи начинается с оценки качества речевого сигнала. На этом этапе определяется уровень помех и искажений.
- Результат оценки поступает в модуль акустической адаптации, который управляет модулем расчета параметров речи, необходимых для распознавания.
- В сигнале выделяются участки, содержащие речь, и происходит оценка параметров речи. Происходит выделение фонетических и просодических вероятностных характеристик для синтаксического, семантического и прагматического анализа. (Оценка информации о части речи, форме слова и статистические связи между словами.)
- Далее параметры речи поступают в основной блок системы распознавания — декодер. Это компонент, который сопоставляет входной речевой поток с информацией, хранящейся в акустических и языковых моделях, и определяет наиболее вероятную последовательность слов, которая и является конечным результатом распознавания.
Признаки
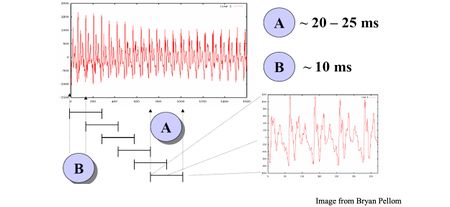
Рисунок 3. Разделение осциллограммы на фреймы. Источник
Входные данные представляют собой непрерывную осциллограмму звуковой волны. В задачах распознавания речи эту осциллограмму разбивают на фреймы — фрагменты звукового потока длительностью около 20 мс и шагом 10 мс. Такой размер соответствует скорости человеческой речи: если человек говорит по 3 слова в секунду, каждое из которых состоит примерно из 4 звуков и каждый звук разбивается на 3 этапа, то на этап выходит около 28 мс. Каждый фрейм независимо трансформируется и подвергается извлечению признаков, тем самым образуя векторизированный набор данных для задачи машинного обучения.
Признаки речевых событий, используемые при распознавании речи:
- Спектр Фурье.
- Спектр Фурье в шкале мел.
- Коэффициенты линейного предсказания.
- Кепстр.
Спектр Фурье
Спектр Фурье получают, используя алгоритм БПФ (Быстрого Преобразования Фурье) с длиной окна равной 2-4 периода основного тона, что составляет около 20 мс. При частоте квантования 10-16 кГц выбирается окно 256 отсчетов.
Для ослабления искажений сигнала, вызванных применением к непрерывному сигналу конечного окна анализа, чаще всего используется окно Хэмминга по формуле:
[math]S'(n) = [0.54 — 0.46cos\left(\frac<2\pi n>\right)]*S(n)[/math]
где n = 1..N, N – размерность окна, S(n) – отсчеты речевого сигнала.
Спектр Фурье в шкале мел
К каждому кадру, полученного Фурье спектра применяется блок мел-фильтров — треугольных пересекающихся фильтров, расположенных наиболее плотно в области нижних частот. Количество фильтров — 26. Для расчета фильтров выбирается верхняя и нижняя частота. Затем осуществляется переход от частотной шкалы к мел-шкале по формуле:
[math]M(f) = 1127*ln\left(1 + \frac\right)[/math]
На мел-шкале выбираются линейно расположенные точки (28 точек для 26 фильтров), после чего, производится обратный переход в частотную область.
Коэффициенты линейного предсказания
Модель линейного предсказания речи предполагает, что передаточная функция голосового тракта представляется полюсным фильтром с передаточной функцией:
где p – число полюсов и [math]a_0 = 1[/math] ; Фильтр с такой передаточной функцией позволяет описать поведение сглаженного спектра речевого сигнала с хорошей точностью, за исключением назализованных звуков. Коэффициенты фильтра < [math]a_i[/math] >– выбираются путем минимизации среднеквадратичной ошибки предсказания, просуммированной на окне анализа.
Кепстр (cepstrum) сигнала на основе спектра Фурье вычисляется путем применения косинусного Фурье преобразования к логарифму спектра:
где [math]s_i[/math] – логарифм спектра, N – количество отсчётов спектра, [math]C_[/math] – унитарная матрица косинусного преобразования.
Кепстральные коэффициенты, полученные приведённым способом из мел спектра Фурье, широко используются для распознавания с помощью марковских моделей и носят название MFCC (Mel-frequency cepstral coefficients).
Показатели оценки качества распознавания речи
Существуют различные по сложности и прикладному значению задачи распознавания: изолированных слов (команд); ключевых слов в потоке речи; связанной речи (тщательное проговаривание текста с паузами между словами); слитной речи (разделяют диктовку в узкой тематической области, и спонтанную речь, например, в диалоге между людьми).
Оценка системы, распознающей отдельные команды, не представляет каких-либо трудностей – количество неправильно распознанных команд делится на общее количество испытаний и получается процент ошибки. Для систем, распознающих слитную речь, ситуация не столь проста.
Основными показателями качества распознавания слитной речи являются:
- процент правильно распознанных слов (WRR — Word Recognition Rate);
- процент неправильно распознанных слов (WER — Word Error Rate);
- процент неправильно распознанных предложений/фраз (SER — Sentence Error Rate);
Поскольку с развитием речевых технологий показатель WER все более приближается к нулю, то значение улучшения WER более наглядно, чем улучшение точности распознавания слов.
[math]WER = \frac * 100%[/math]
где T — количество слов в распознаваемой фразе, S — количество замененных слов, D — количество удаленных слов, I — количество вставленных слов. Показатель WER может быть больше 100%.
Другим важным критерием оценки систем распознавания слитной речи является — скорость обработки речи. Она вычисляется с помощью показателя скорости (Real-Time Factor, Speed Factor):
[math]T_[/math] — длительность обрабатываемого аудиосигнала;
[math]T_[/math] — время, необходимое для обработки сигнала.
Если [math]RTF \leqslant 1.0[/math] — то распознавание речи ведется в режиме реального времени.
State of the Art в автоматическом распознавании речи
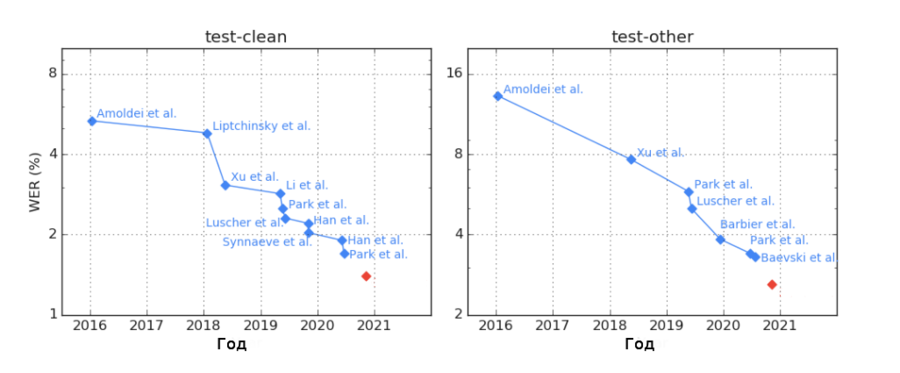
Рисунок 4. $WER$ SOTA алгоритмов на наборах данных LibriSpeech test-clean/test-other. $WER$ описываемого в статье алгоритма отмечен красной точкой. Источник
Для обучения современных систем распознавания речи требуются тысячи часов размеченной речи, однако получение размеченных данных в необходимом объеме (особенно с учетом разнообразия существующих языков) затруднительно. Это повлияло на то, что сейчас в машинном обучении для распознавания речи успешно используется обучение с частичным привлечением учителя, которое позволяет сначала обучать модель на большом объеме неразмеченных данных, а потом корректировать ее при помощи размеченных.
Одним из примеров обучения с частичным привлечением учителя для автоматического распознавания речи является подход, впервые представленный в статье [3] , основанный на комбинации алгоритмов noisy student, wav2vec и использовании модели Конформера. Такой метод позволил уменьшить $WER$ на наборах данных LibriSpeech test-clean/test-other с $1.7\%/3.3\%$ (предыдущий state-of-the-art) до $1.4\%/2.6\%$ (Рисунок 4). $WER$ человека — $5.9\%$ [4]
Основная идея состоит в том, что множество моделей Конформеров при помощи алгоритма wav2vec предварительно обучается на неразмеченных данных, при этом одновременно с этим на основе них генерируются размеченные. Таким образом, неразмеченные данные используются для двух целей: для обучения модели и для генерации размеченных данных, которые используются для дальнейшего обучения модели алгоритмом noisy student.
Конформер
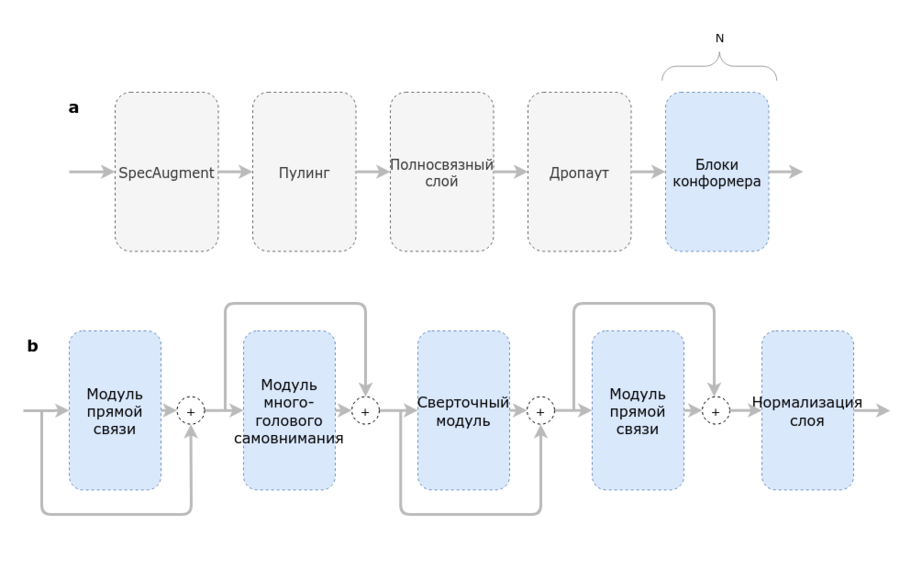
Рисунок 5. Общая схема Конформера (a) и схема блоков Конформера (b)
Трансформер [на 21.01.21 не создан] , использующий механизм самовнимания, хорошо захватывает глобальный контекст, однако не очень хорошо извлекает локальные признаки. Сверточные нейронные сети, наоборот, эффективно используют локальные признаки, но требуют большого числа слоев для захвата глобального контекста. Конформер (англ. Conformer) комбинирует сверточные слои с механизмом самовнимания. $WER$ на LibriSpeech test-clean/test-other составляет $1.9\%/3.9\%$.
Сначала данные, подающиеся на вход Конформеру, проходят аугментацию. В применении к распознаванию речи, используется метод аугментации SpecAugment. SpecAugment применяет к мел спектрограмме три вида деформаций: искажение времени (удлинение или сжатие некоторого промежутка записи), удаление некоторого временного промежутка из записи, и удаление некоторого промежутка частот. Таким образом, при обучении на зашумленных с помощью SpecAugment данных сеть обучается на признаках, устойчивых к деформации во времени, частичной потере частотной информации и потере небольших сегментов речи. Конформер обрабатывает итоговые аугментированные входные данные с помощью сверточной нейронной сети, состоящей из слоя пулинга, полносвязного слоя и дропаута, а затем с помощью последовательности блоков Конформера.
Блоки Конформера — это последовательность из двух модулей прямой связи (англ. feed forward), между которыми расположены модуль многоголового самовнимания (англ. Multi-Head Self Attention) и сверточный модуль, с последующей нормализацией слоя (англ. layer normalization).

Рисунок 6. Модуль многоголового самовнимания
Модуль многоголового самовнимания
В модуле используется блок многоголового внимания с относительным позиционным кодированием (англ. Multi-Head Attention with Relative Positional Encoding). Такой блок (изначально часть архитектуры Трансформер-XL [5] ) используется с целью исправить два недостатка Трансформера: ограничение на длину входа (что не позволяет модели, например, использовать слово, которое появилось несколько предложений назад) и фрагментацию контекста (последовательность разбивается на несколько блоков, каждый из которых обучается независимо). Для достижения этой цели используются два механизма: механизм повторения (англ. reccurence mechanism) и относительное позиционное кодирование (англ. relative positional encoding). Механизм повторения позволяет использовать информацию из предыдущих сегментов. Как и в оригинальной версии, Трансформер-XL обрабатывает первый сегмент токенов, но сохраняет выходные данные скрытых слоев. При обработке следующего сегмента каждый скрытый слой получает два входа: результат предыдущего скрытого слоя этого сегмента, как в Трансформере, и результат предыдущего скрытого слоя из предыдущего сегмента, который позволяет модели создавать зависимости от далеких сегментов.
Однако, с использованием механизма повторения возникает новая проблема: при использовании исходного позиционного кодирования каждый сегмент кодируется отдельно, и в результате токены из разных сегментов закодированы одинаково.
Относительное позиционное кодирование почти полностью совпадает с абсолютным позиционным кодированием из оригинального Трансформера, но вместо позиции внутри сегмента используется расстояние между сегментами. Кроме того, добавляются два вектора параметров, задающие важность расстояния и содержания второго токена относительно первого.
Использование модуля многоголового самовнимания с относительным позиционным кодированием позволяет сети лучше обучаться при различной длине ввода, а результирующая архитектура получается более устойчивой к неоднородности длины высказывания.
Сверточный модуль

Рисунок 7. Сверточный модуль
Последовательность слоев в сверточном модуле начинается с управляемого модуля [6] : сверточного слоя с ядром $1 \times 1$ (англ. pointwise convolution) и управляемого линейного блока (англ. gated linear unit). Управляемый линейный блок — слой нейронной сети, определяемый как покомпонентное произведение двух линейных преобразований входных данных, функция активации одного из которых — сигмоида. Использование управляемого линейного блока уменьшает проблему исчезающего градиента. После сверточного слоя используется пакетная нормализация.
В модуле используется функция активации swish [7] (до появления в статье Google Brain была известна как SiLU [8] и SiL [9] ): $swish(x) = \dfrac>$, $\beta$ — параметр.
Модули прямой связи

Рисунок 8. Схема модуля прямой связи
В отличие от Трансформера, в котором единственный модуль прямой связи следует за модулем внимания и состоит из двух линейных преобразований и нелинейной активации между ними, Конформер представляет собой два модуля прямой связи, состоящих из слоя нормализации и двух линейных слоев. Кроме того, для регуляризации используется функция активации swish и дропаут.
wav2vec
Подход wav2vec [10] основан на самообучении на мел спектрограммах.
- Энкодер признаков (англ. Feature Encoder) $f: X \to Z$ реализован на основе сверточного слоя. Преобразует мел спектрограммы $X$, разбитые на $T$ временных интервалов, в наборы признаков $\$, которые описывают исходные данные в каждом из $T$ интервалов.
- Контекстная сеть (англ. Context Network) $g: Z \to C$ реализована на основе линейного слоя и слоя, состоящего из $N$ блоков Конформера. Преобразует наборы признаков $\$, полученные в результате работы энкодера признаков, в контекстные вектора $\$.
- Модуль линейного слоя (англ. Linear Layer Module) $u: Z \to T$ реализован на основе линейного слоя. Преобразует наборы признаков $\$, полученные в результате работы энкодера признаков, в целевые вектора $\$.
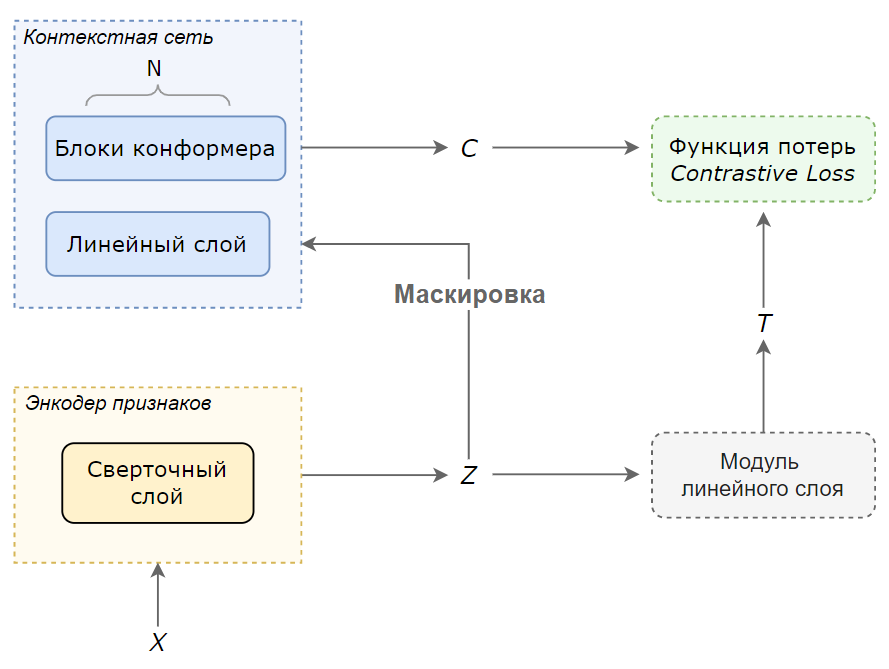
Рисунок 9. Схема обучения модели wav2vec
- Исходные мел спектрограммы $X$ проходят через через энкодер признаков $f$ и таким образом преобразуются в $T$ наборов признаков $\$.
- $\$ преобразуются в контекстные и целевые вектора:
- Случайное подмножество векторов $z_>$ маскируется, и каждый $z \in z_>$ заменяется на обученный вектор признаков. Полученное новое множество признаков $\$ подается на вход контекстной сети и преобразуется в контекстные вектора $\$.
- Множество $\$ без замаскированных наборов признаков подается на вход модуля линейного слоя $u$ и преобразуется в целевые вектора $\$.
Суть данного подхода состоит в том, что маскируются наборы признаков для некоторых из $T$ интервалов, и путем минимизации функции потерь модель на основе $N$ блоков Конформера учится подбирать наиболее похожий вектор, характеризующий признаки замаскированных участков. При этом модуль линейного слоя позволяет получить целевые вектора для замаскированных данных и таким образом модель обучается на размеченных данных.
Noisy student
Вариация классического алгоритма самообучения: на каждой итерации модель-ученик обучается на аугментированных данных.
1. Набор размеченных данных $S$.
2. Набор неразмеченных данных $U$.
3. Обученная языковая модель $LM$.
4. Набор предобученных с помощью wav2vec моделей $M_0, \dots, M_n$.1. Модель $M_0$ дообучается (англ. fine-tune) на наборе данных $S$ с использованием SpecAugment. $M = M_0$.
2. Модель $M$ сливается (англ. fuse) [11] с моделью $LM$.
3. Набор данных $U$ размечается с помощью $M$, получается новый набор данных $A$.
4. Наборы $S$ и $A$ объединяются, производится дообучение предобученной модели $M_i$ на объединенном наборе данных с использованием SpecAugment.
5. Если перебраны не все модели из набора, то $M = M_$, происходит возвращение к шагу $2$.Применение
Системы распознавания речи начали развиваться как специальные сервисы для людей с ограниченными возможностями, но также нашли применение в различных сферах бизнеса, таких как:
- Телефония: системы голосового самообслуживания;
- «Умный дом»: голосовой интерфейс управления;
- Роботы: голосовой интерфейс электронных роботов;
- РС, ноутбуки, телефоны: голосовой ввод команд, диктовка текста;
- Автомобили: голосовое управление в салоне автомобиля.
Основные отрасли применения:
- Голосовое управление
- Голосовые команды
- Голосовой ввод текста
- Голосовой поиск
См. также
- Байесовская классификация
- Распознавание образов
- Распознавание речи от Яндекса
- Субвокальное распознавание
Примечания
- ↑Федосин С.А., Еремин А. Ю. Классификация систем распознавания речи. — Саранск. : МГУ им. Н.П. Огарева, 2009. — С. 3.
- ↑Тампель И.Б, Карпов А.А. Автоматическое распознавание речи. — СПб. : Университет ИТМО, 2016. — С. 113.
- ↑Yu Zhang, James Qin, Daniel S. Park, Wei Han, Chung-Cheng Chiu, Ruoming Pang, Quoc V. Le, Yonghui Wu Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition[1]
- ↑W. Xiong, L. Wu, F. Alleva, J. Droppo, X. Huang, A. Stolcke The Microsoft 2017 Conversational Speech Recognition System[2]
- ↑Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context[3]
- ↑N. Dauphin, Angela Fan, Michael Auli, David Grangier Language Modeling with Gated Convolutional Networks[4]
- ↑Prajit Ramachandran, Barret Zoph, Quoc V. Le Searching for Activation Functions
- ↑Dan Hendrycks, Kevin Gimpel Gaussian Error Linear Units (GELUs)
- ↑Stefan Elfwing, Eiji Uchibe, Kenji Doya Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning
- ↑Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations[5]
- ↑Caglar Gulcehre, Orhan Firat. Kelvin Xu, Kyunghyun Cho, Loic Barrault, Huei-Chi Lin, Fethi Bougares, Holger Schwenk, Yoshua Bengio On Using Monolingual Corpora in Neural Machine Translation [6]
Источники информации
- [7] — статья на Википедии
- Тампель И.Б, Карпов А.А. Автоматическое распознавание речи. Учебное пособие. — СПб: Университет ИТМО, 2016. — 138 с.
- [8] — статья «Классификация систем распознавания речи».
- [9] — статья «Выделение границ фонем речевого сигнала с помощью мел-частотных спектральных коэффициентов».
- Машинное обучение
- Обработка естественного языка
- Распознавание речи