Python: как создать простейшего голосового помощника?
Для создания голосового помощника не нужно обладать большими знаниями в программировании, главное понимать каким функционалом он должен владеть. Многие компании создают их на первой линии связи с клиентом для удобства, оптимизации рабочих процессов и наилучшей классификации звонков.
В данной статье представлена программа, которая может стать основой для Вашего собственного чат-бота, а если точнее – голосового помощника для распознавания голоса и последующего выполнения команд. С ее помощью мы сможем понять принцип работы наиболее часто встречаемых голосовых помощников.
Для начала объявим необходимые нам библиотеки:
#Необходимые библиотеки import speech_recognition as sr import os import sys import webbrowser import pyttsx3 as p from datetime import datetime import time import datetime import random
Также не забудем вести лог файл, который понадобится нам, если же мы все-таки решим улучшить бота для работы с нейронной сетью. Многие компании использую нейронную сеть в своих голосовых помощниках для понимания эмоций клиента и соответствующего реагирования на них. Также стоит не забывать, что с помощью анализа логов, мы сможем понять слабые места алгоритма бота и улучшить взаимодействие с клиентами.
#Создаем лог chat_log = [[‘SESSION_ID’, ‘DATE’, ‘AUTHOR’, ‘TEXT’, ‘AUDIO_NUM’]] #Узнаем номер сессии i = 1 exit = 0 while exit == 0: session_id = str(i) if session_id not in os.listdir(): os.mkdir(session_id) exit = 1 else: i = i + 1 #Первое сообщение пишет bot author = ‘Bot’ text = ‘Привет! Чем я могу вам помочь?’
В лог файл мы записываем время сообщения, автора (бот или пользователь) и собственно сам сказанный текст.
#Добавляем данные к логу с помощью этой процедуры def log_me(author, text, audio): now = datetime.datetime.now() i = 1 exit = 0 while exit == 0: audio_num = str(i)+’.wav’ if audio_num not in os.listdir(session_id): exit = 1 else: i = i + 1 os.chdir(session_id) with open(audio_num , «wb») as file: file.write(audio.get_wav_data()) chat_log.append([now.strftime(«%Y-%m-%d %H:%M:%S»), author, text, audio_num])
Выводим первое сообщение за авторством бота: Привет! Чем я могу вам помочь?
# Выводим первое сообщение на экран и записываем в лог print(«Bot: «+ text) log_me(author, text, audio)
А с помощью такой процедуры в Jupyter Notebook мы можем озвучить через устройство воспроизведения, настроенное по умолчанию, сказанные слова:
#Произношение words def talk(words): engine.say(words) engine.runAndWait()
Как озвучивать текст мы рассмотрели выше, но как же мы свой голос сможем превратить в текст? Тут нам поможет распознавание речи от Google и некоторые манипуляции с микрофоном.
#Настройка микрофона def command(): rec = sr.Recognizer() with sr.Microphone() as source: #Бот ожидает нашего голоса print(‘Bot: . ‘) #Небольшая задержка в записи rec.pause_threshold = 1 #Удаление фонового шума с записи rec.adjust_for_ambient_noise(source, duration=1) audio = rec.listen(source) try: #Распознание теста с помощью сервиса GOOGLE text = rec.recognize_google(audio, language=»ru-RU»).lower() #Вывод сказанного текста на экран print(‘Вы: ‘ + text[0].upper() + text[1:]) log_me(‘User’, text, audio) #Если не распознался тест из аудио except sr.UnknownValueError: text = ‘Не понимаю. Повторите.’ print(‘Bot: ‘ + text) talk(text) #Начинаем заново слушать text = command() log_me(‘Bot’, text, , Null) return text
Что может сделать наш помощник кроме того, чтобы нас слушать? Все ограничено нашей фантазией! Рассмотрим несколько интересный примеров.
Начнем с простого, пусть при команде открыть сайт – он откроет сайт (не ожидали?).
#Тут расписаны действия, которые будут выполнятся при наличии некоторых словосочетаний def makeSomething(text): if ‘открой сайт’ in text: print(‘Bot: Открываю сайт NewTechAudit.’) talk(‘Открываю сайт NewTechAudit.’) log_me(‘Bot’,’Открываю сайт NewTechAudit.’, Null) webbrowser.open(‘https://newtechaudit.ru/’)
Иногда полезно послушать свои слова, да чужими устами. Пусть бот еще умеет и повторять за нами:
#Повторение фразы пользователя elif ‘произнеси’ in text or ‘скажи’ in text or ‘повтори’ in text: print(‘Bot: ‘ + text[10].upper() + text[11:]) talk(text[10:]) log_me(‘Bot’, text[10].upper() + text[11:] , Null)
Пусть еще и собеседником будет, но начнем мы пока только со знакомства:
#Ответ на вопрос elif ‘своё имя’ in text or ‘как тебя зовут’ in text or ‘назови себя’ in text: print(‘Bot: Меня зовут Bot.’) talk(‘Меня зовут Bot’) log_me(‘Bot’, ‘Меня зовут Bot’, Null)
Мы также можем попросить голосового помощника назвать случайное число в выбранных нами пределах в формате: Назови случайное число от (1ое число) до (2ое число).
#Определение случайного числа elif ‘случайное число’ in text: ot=text.find(‘от’) do=text.find(‘до’) f_num=int(text[ot+3:do-1]) l_num=int(text[do+3:]) r=str(random.randint(f_num, l_num)) print(‘Bot: ‘ + r) talk(r) log_me(‘Bot’, r, Null)
Для того, чтобы завершить программу, достаточно только попрощаться с ботом:
#Завершение программы elif ‘пока’ in text or ‘до свидания’ in text: print(‘Bot: До свидания!’) talk(‘До свидания’) log_me(‘Bot’, ‘Конец сессии’, Null) os.chdir(session_id) log_file = open( session_id + «.txt», «w») for row in chat_log: np.savetxt(log_file, row) log_file.close() sys.exit()
А чтобы все это работало беспрерывно, мы создаем бесконечный цикл.
#Бесконечный цикл для работы while True: makeSomething(command())
Проведем тестовый диалог:
Краткое руководство. Создание пользовательского голосового помощника
В этом кратком руководстве вы будете использовать пакет SDK для службы «Речь» для создания пользовательского приложения голосового помощника, которое подключается к боту, который вы уже создали и настроили. Если необходимо создать бот, см. дополнительные сведения в исчерпывающем руководстве.
После выполнения нескольких предварительных требований подключение пользовательского интерфейса пользователя займет всего несколько шагов:
- Создайте объект BotFrameworkConfig , содержащий ключ и регион подписки.
- Создайте объект DialogServiceConnector , используя приведенный выше объект BotFrameworkConfig .
- С помощью объекта DialogServiceConnector запустите процесс прослушивания для одного речевого фрагмента.
- Проверьте возвращенный результат ActivityReceivedEventArgs .
Пакет SDK службы «Речь» для C++, JavaScript, Objective-C, Python и Swift поддерживает пользовательские голосовые помощники, но здесь пока нет соответствующего руководства.
Вы можете просмотреть или скачать все примеры для пакета SDK службы «Речь» для C# на сайте GitHub.
Предварительные требования
Перед началом работы нужно сделать следующее:
- создавать ресурс службы «Речь»;
- Настройка среды разработки и создание пустого проекта
- Создание программы-робота, подключенной к Каналу Direct Line Speech
- Убедитесь, что у вас есть доступ к микрофону для аудиозахвата.
Ознакомьтесь со списком поддерживаемых регионов для голосовых помощников и убедитесь, что ваши ресурсы развернуты в одном из этих регионов.
Откройте проект в Visual Studio.
Сначала необходимо убедиться, что проект открыт в Visual Studio.
Добавление стандартного кода
Добавим код, который выступает в качестве основы для нашего проекта.
- Откройте MainPage.xaml в обозревателе решений.
- В представлении XAML конструктора замените все содержимое следующим фрагментом кода, который определяет элементарный пользовательский интерфейс:
" Margin="10,10,10,20" TextWrapping="Wrap" /> Конструктор обновляется для отображения пользовательского интерфейса приложения.
- В Обозревателе решений откройте исходный файл кода программной части MainPage.xaml.cs . (Он сгруппирован в MainPage.xaml .) Замените содержимое этого файла приведенным ниже, которое включает:
using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Dialog; using System; using System.Diagnostics; using System.IO; using System.Text; using Windows.Foundation; using Windows.Storage.Streams; using Windows.UI.Xaml; using Windows.UI.Xaml.Controls; using Windows.UI.Xaml.Media; namespace helloworld < public sealed partial class MainPage : Page < private DialogServiceConnector connector; private enum NotifyType < StatusMessage, ErrorMessage >; public MainPage() < this.InitializeComponent(); >private async void EnableMicrophone_ButtonClicked( object sender, RoutedEventArgs e) < bool isMicAvailable = true; try < var mediaCapture = new Windows.Media.Capture.MediaCapture(); var settings = new Windows.Media.Capture.MediaCaptureInitializationSettings(); settings.StreamingCaptureMode = Windows.Media.Capture.StreamingCaptureMode.Audio; await mediaCapture.InitializeAsync(settings); >catch (Exception) < isMicAvailable = false; >if (!isMicAvailable) < await Windows.System.Launcher.LaunchUriAsync( new Uri("ms-settings:privacy-microphone")); >else < NotifyUser("Microphone was enabled", NotifyType.StatusMessage); >> private void NotifyUser( string strMessage, NotifyType type = NotifyType.StatusMessage) < // If called from the UI thread, then update immediately. // Otherwise, schedule a task on the UI thread to perform the update. if (Dispatcher.HasThreadAccess) < UpdateStatus(strMessage, type); >else < var task = Dispatcher.RunAsync( Windows.UI.Core.CoreDispatcherPriority.Normal, () =>UpdateStatus(strMessage, type)); > > private void UpdateStatus(string strMessage, NotifyType type) < switch (type) < case NotifyType.StatusMessage: StatusBorder.Background = new SolidColorBrush( Windows.UI.Colors.Green); break; case NotifyType.ErrorMessage: StatusBorder.Background = new SolidColorBrush( Windows.UI.Colors.Red); break; >StatusBlock.Text += string.IsNullOrEmpty(StatusBlock.Text) ? strMessage : "\n" + strMessage; if (!string.IsNullOrEmpty(StatusBlock.Text)) < StatusBorder.Visibility = Visibility.Visible; StatusPanel.Visibility = Visibility.Visible; >else < StatusBorder.Visibility = Visibility.Collapsed; StatusPanel.Visibility = Visibility.Collapsed; >// Raise an event if necessary to enable a screen reader // to announce the status update. var peer = Windows.UI.Xaml.Automation.Peers.FrameworkElementAutomationPeer.FromElement(StatusBlock); if (peer != null) < peer.RaiseAutomationEvent( Windows.UI.Xaml.Automation.Peers.AutomationEvents.LiveRegionChanged); >> // Waits for and accumulates all audio associated with a given // PullAudioOutputStream and then plays it to the MediaElement. Long spoken // audio will create extra latency and a streaming playback solution // (that plays audio while it continues to be received) should be used -- // see the samples for examples of this. private void SynchronouslyPlayActivityAudio( PullAudioOutputStream activityAudio) < var playbackStreamWithHeader = new MemoryStream(); playbackStreamWithHeader.Write(Encoding.ASCII.GetBytes("RIFF"), 0, 4); // ChunkID playbackStreamWithHeader.Write(BitConverter.GetBytes(UInt32.MaxValue), 0, 4); // ChunkSize: max playbackStreamWithHeader.Write(Encoding.ASCII.GetBytes("WAVE"), 0, 4); // Format playbackStreamWithHeader.Write(Encoding.ASCII.GetBytes("fmt "), 0, 4); // Subchunk1ID playbackStreamWithHeader.Write(BitConverter.GetBytes(16), 0, 4); // Subchunk1Size: PCM playbackStreamWithHeader.Write(BitConverter.GetBytes(1), 0, 2); // AudioFormat: PCM playbackStreamWithHeader.Write(BitConverter.GetBytes(1), 0, 2); // NumChannels: mono playbackStreamWithHeader.Write(BitConverter.GetBytes(16000), 0, 4); // SampleRate: 16kHz playbackStreamWithHeader.Write(BitConverter.GetBytes(32000), 0, 4); // ByteRate playbackStreamWithHeader.Write(BitConverter.GetBytes(2), 0, 2); // BlockAlign playbackStreamWithHeader.Write(BitConverter.GetBytes(16), 0, 2); // BitsPerSample: 16-bit playbackStreamWithHeader.Write(Encoding.ASCII.GetBytes("data"), 0, 4); // Subchunk2ID playbackStreamWithHeader.Write(BitConverter.GetBytes(UInt32.MaxValue), 0, 4); // Subchunk2Size byte[] pullBuffer = new byte[2056]; uint lastRead = 0; do < lastRead = activityAudio.Read(pullBuffer); playbackStreamWithHeader.Write(pullBuffer, 0, (int)lastRead); >while (lastRead == pullBuffer.Length); var task = Dispatcher.RunAsync( Windows.UI.Core.CoreDispatcherPriority.Normal, () => < mediaElement.SetSource( playbackStreamWithHeader.AsRandomAccessStream(), "audio/wav"); mediaElement.Play(); >); > private void InitializeDialogServiceConnector() < // New code will go here >private async void ListenButton_ButtonClicked( object sender, RoutedEventArgs e) < // New code will go here >> > - Добавьте следующий фрагмент кода в текст метода InitializeDialogServiceConnector . Этот код создает DialogServiceConnector с помощью сведений о подписке.
// Create a BotFrameworkConfig by providing a Speech service subscription key // the botConfig.Language property is optional (default en-US) const string speechSubscriptionKey = "YourSpeechSubscriptionKey"; // Your subscription key const string region = "YourServiceRegion"; // Your subscription service region. var botConfig = BotFrameworkConfig.FromSubscription(speechSubscriptionKey, region); botConfig.Language = "en-US"; connector = new DialogServiceConnector(botConfig); Примечание Ознакомьтесь со списком поддерживаемых регионов для голосовых помощников и убедитесь, что ваши ресурсы развернуты в одном из этих регионов.
Примечание Для получения сведений о настройке бота см. документацию по Bot Framework для канала Direct Line Speech.
// ActivityReceived is the main way your bot will communicate with the client // and uses bot framework activities connector.ActivityReceived += (sender, activityReceivedEventArgs) => < NotifyUser( $"Activity received, hasAudio=activity="); if (activityReceivedEventArgs.HasAudio) < SynchronouslyPlayActivityAudio(activityReceivedEventArgs.Audio); >>; // Canceled will be signaled when a turn is aborted or experiences an error condition connector.Canceled += (sender, canceledEventArgs) => < NotifyUser($"Canceled, reason="); if (canceledEventArgs.Reason == CancellationReason.Error) < NotifyUser( $"Error: code=, details="); > >; // Recognizing (not 'Recognized') will provide the intermediate recognized text // while an audio stream is being processed connector.Recognizing += (sender, recognitionEventArgs) => < NotifyUser($"Recognizing! in-progress text="); >; // Recognized (not 'Recognizing') will provide the final recognized text // once audio capture is completed connector.Recognized += (sender, recognitionEventArgs) => < NotifyUser($"Final speech to text result: ''"); >; // SessionStarted will notify when audio begins flowing to the service for a turn connector.SessionStarted += (sender, sessionEventArgs) => < NotifyUser($"Now Listening! Session started, >; // SessionStopped will notify when a turn is complete and // it's safe to begin listening again connector.SessionStopped += (sender, sessionEventArgs) => < NotifyUser($"Listening complete. Session ended, >; if (connector == null) < InitializeDialogServiceConnector(); // Optional step to speed up first interaction: if not called, // connection happens automatically on first use var connectTask = connector.ConnectAsync(); >try < // Start sending audio to your speech-enabled bot var listenTask = connector.ListenOnceAsync(); // You can also send activities to your bot as JSON strings -- // Microsoft.Bot.Schema can simplify this string speakActivity = @""; await connector.SendActivityAsync(speakActivity); > catch (Exception ex) < NotifyUser($"Exception: ", NotifyType.ErrorMessage); > Создание и запуск приложения
Теперь можно приступать к созданию приложения и проверке пользовательского голосового помощника, используя службу «Речь».
- В строке меню выберите Сборка>Построить решение, чтобы создать приложение. Теперь код должен компилироваться без ошибок.
- Выберите Отладка>Начать отладку(или нажмите клавишу F5), чтобы запустить приложение. Откроется окно helloworld.
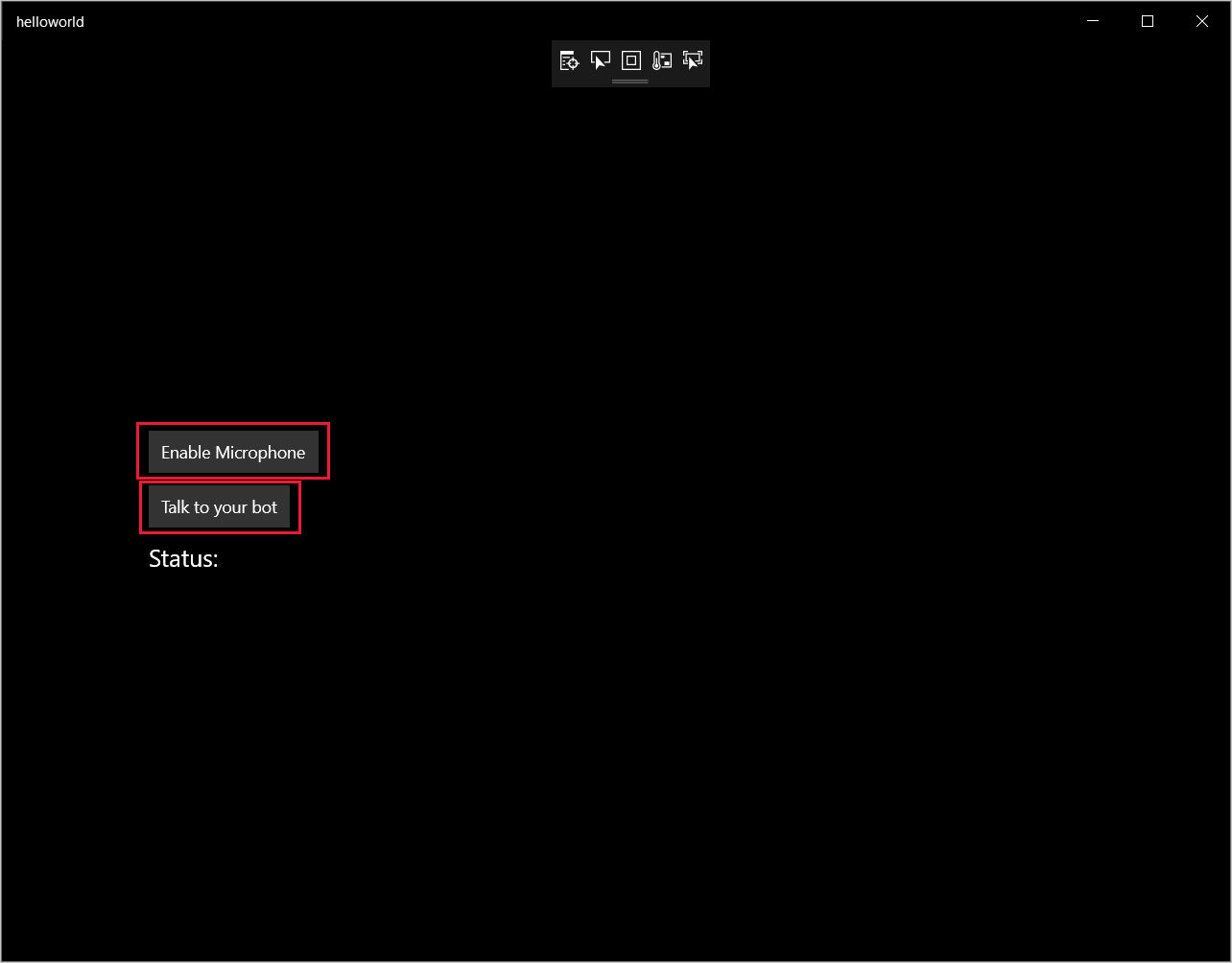
- Выберите Включить микрофон, а когда появится запрос на разрешение доступа, выберите Да.
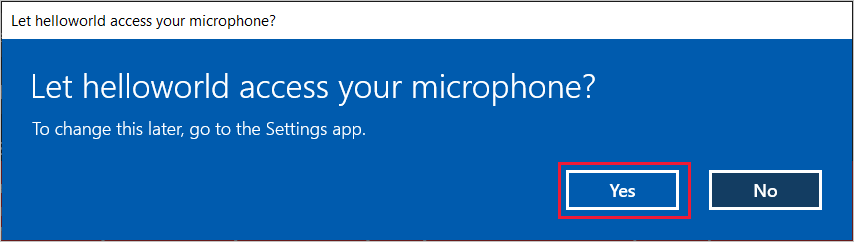
- Щелкните Talk to your bot (Разговор с ботом) и произнесите фразу или предложение на английском языке в микрофон устройства. Ваша речь передастся в канал «Речь Direct Line» и преобразуется в текст, который появится в том же окне.
Дальнейшие действия
Вы можете просмотреть или скачать все примеры для пакета SDK службы «Речь» для Java на сайте GitHub.
Выберите целевую среду
- Среда выполнения Java
- Android
Предварительные требования
Перед началом работы нужно сделать следующее:
- создавать ресурс службы «Речь»;
- Настройка среды разработки и создание пустого проекта
- Создание программы-робота, подключенной к Каналу Direct Line Speech
- Убедитесь, что у вас есть доступ к микрофону для аудиозахвата.
Ознакомьтесь со списком поддерживаемых регионов для голосовых помощников и убедитесь, что ваши ресурсы развернуты в одном из этих регионов.
Создание и настройка проекта
Кроме того, для включения ведения журнала обновите файл pom.xml, чтобы добавить следующие зависимости.
org.slf4j slf4j-simple 1.7.5
Добавление примеров кода
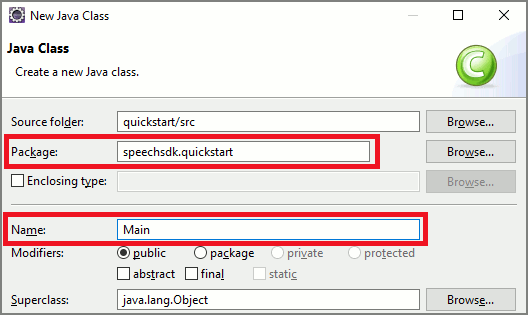
- Выберите Файл>Создать>Класс, чтобы добавить пустой класс в проект Java.
- В окне New Java Class (Новый класс Java) введите speechsdk.quickstart в поле Пакет и Main в поле Имя.
- Откройте только что созданный класс Main и замените содержимое файла Main.java следующим начальным кодом.
package speechsdk.quickstart; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import com.microsoft.cognitiveservices.speech.audio.PullAudioOutputStream; import com.microsoft.cognitiveservices.speech.dialog.BotFrameworkConfig; import com.microsoft.cognitiveservices.speech.dialog.DialogServiceConnector; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import javax.sound.sampled.AudioFormat; import javax.sound.sampled.AudioSystem; import javax.sound.sampled.DataLine; import javax.sound.sampled.SourceDataLine; import java.io.InputStream; public class Main < final Logger log = LoggerFactory.getLogger(Main.class); public static void main(String[] args) < // New code will go here >private void playAudioStream(PullAudioOutputStream audio) < ActivityAudioStream stream = new ActivityAudioStream(audio); final ActivityAudioStream.ActivityAudioFormat audioFormat = stream.getActivityAudioFormat(); final AudioFormat format = new AudioFormat( AudioFormat.Encoding.PCM_SIGNED, audioFormat.getSamplesPerSecond(), audioFormat.getBitsPerSample(), audioFormat.getChannels(), audioFormat.getFrameSize(), audioFormat.getSamplesPerSecond(), false); try < int bufferSize = format.getFrameSize(); final byte[] data = new byte[bufferSize]; SourceDataLine.Info info = new DataLine.Info(SourceDataLine.class, format); SourceDataLine line = (SourceDataLine) AudioSystem.getLine(info); line.open(format); if (line != null) < line.start(); int nBytesRead = 0; while (nBytesRead != -1) < nBytesRead = stream.read(data); if (nBytesRead != -1) < line.write(data, 0, nBytesRead); >> line.drain(); line.stop(); line.close(); > stream.close(); > catch (Exception e) < e.printStackTrace(); >> > - Замените строку YourSubscriptionKey ключом ресурса службы «Речь», который можно получить на портале Azure.
- Замените строку YourServiceRegion на регион, связанный с вашим ресурсом службы «Речь».
Ознакомьтесь со списком поддерживаемых регионов для голосовых помощников и убедитесь, что ваши ресурсы развернуты в одном из этих регионов.
final String subscriptionKey = "YourSubscriptionKey"; // Your subscription key final String region = "YourServiceRegion"; // Your speech subscription service region final BotFrameworkConfig botConfig = BotFrameworkConfig.fromSubscription(subscriptionKey, region); // Configure audio input from a microphone. final AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); // Create a DialogServiceConnector instance. final DialogServiceConnector connector = new DialogServiceConnector(botConfig, audioConfig); // Recognizing will provide the intermediate recognized text while an audio stream is being processed. connector.recognizing.addEventListener((o, speechRecognitionResultEventArgs) -> < log.info("Recognizing speech event text: <>", speechRecognitionResultEventArgs.getResult().getText()); >); // Recognized will provide the final recognized text once audio capture is completed. connector.recognized.addEventListener((o, speechRecognitionResultEventArgs) -> < log.info("Recognized speech event reason text: <>", speechRecognitionResultEventArgs.getResult().getText()); >); // SessionStarted will notify when audio begins flowing to the service for a turn. connector.sessionStarted.addEventListener((o, sessionEventArgs) -> < log.info("Session Started event id: <>", sessionEventArgs.getSessionId()); >); // SessionStopped will notify when a turn is complete and it's safe to begin listening again. connector.sessionStopped.addEventListener((o, sessionEventArgs) -> < log.info("Session stopped event id: <>", sessionEventArgs.getSessionId()); >); // Canceled will be signaled when a turn is aborted or experiences an error condition. connector.canceled.addEventListener((o, canceledEventArgs) -> < log.info("Canceled event details: <>", canceledEventArgs.getErrorDetails()); connector.disconnectAsync(); >); // ActivityReceived is the main way your bot will communicate with the client and uses Bot Framework activities. connector.activityReceived.addEventListener((o, activityEventArgs) -> < final String act = activityEventArgs.getActivity().serialize(); log.info("Received activity <>audio", activityEventArgs.hasAudio() ? "with" : "without"); if (activityEventArgs.hasAudio()) < playAudioStream(activityEventArgs.getAudio()); >>); connector.connectAsync(); // Start listening. System.out.println("Say something . "); connector.listenOnceAsync(); // connector.sendActivityAsync(. ) package com.speechsdk.quickstart; import com.microsoft.cognitiveservices.speech.audio.PullAudioOutputStream; import java.io.IOException; import java.io.InputStream; public final class ActivityAudioStream extends InputStream < /** * The number of samples played per second (16 kHz). */ public static final long SAMPLE_RATE = 16000; /** * The number of bits in each sample of a sound that has this format (16 bits). */ public static final int BITS_PER_SECOND = 16; /** * The number of audio channels in this format (1 for mono). */ public static final int CHANNELS = 1; /** * The number of bytes in each frame of a sound that has this format (2). */ public static final int FRAME_SIZE = 2; /** * Reads up to a specified maximum number of bytes of data from the audio * stream, putting them into the given byte array. * * @param b the buffer into which the data is read * @param off the offset, from the beginning of array b, at which * the data will be written * @param len the maximum number of bytes to read * @return the total number of bytes read into the buffer, or -1 if there * is no more data because the end of the stream has been reached */ @Override public int read(byte[] b, int off, int len) < byte[] tempBuffer = new byte[len]; int n = (int) this.pullStreamImpl.read(tempBuffer); for (int i = 0; i < n; i++) < if (off + i >b.length) < throw new ArrayIndexOutOfBoundsException(b.length); >b[off + i] = tempBuffer[i]; > if (n == 0) < return -1; >return n; > /** * Reads the next byte of data from the activity audio stream if available. * * @return the next byte of data, or -1 if the end of the stream is reached * @see #read(byte[], int, int) * @see #read(byte[]) * @see #available * */ @Override public int read() < byte[] data = new byte[1]; int temp = read(data); if (temp return data[0] & 0xFF; > /** * Reads up to a specified maximum number of bytes of data from the activity audio stream, * putting them into the given byte array. * * @param b the buffer into which the data is read * @return the total number of bytes read into the buffer, or -1 if there * is no more data because the end of the stream has been reached */ @Override public int read(byte[] b) < int n = (int) pullStreamImpl.read(b); if (n == 0) < return -1; >return n; > /** * Skips over and discards a specified number of bytes from this * audio input stream. * * @param n the requested number of bytes to be skipped * @return the actual number of bytes skipped * @throws IOException if an input or output error occurs * @see #read * @see #available */ @Override public long skip(long n) < if (n if (n long count = 0; for (long i = n; i > 0; i -= Integer.MAX_VALUE) < int size = (int) Math.min(Integer.MAX_VALUE, i); byte[] tempBuffer = new byte[size]; count += read(tempBuffer); >return count; > /** * Closes this audio input stream and releases any system resources associated * with the stream. */ @Override public void close() < this.pullStreamImpl.close(); >/** * Fetch the audio format for the ActivityAudioStream. The ActivityAudioFormat defines the sample rate, bits per sample, and the # channels. * * @return instance of the ActivityAudioFormat associated with the stream */ public ActivityAudioStream.ActivityAudioFormat getActivityAudioFormat() < return activityAudioFormat; >/** * Returns the maximum number of bytes that can be read (or skipped over) from this * audio input stream without blocking. * * @return the number of bytes that can be read from this audio input stream without blocking. * As this implementation does not buffer, this will be defaulted to 0 */ @Override public int available() < return 0; >public ActivityAudioStream(final PullAudioOutputStream stream) < pullStreamImpl = stream; this.activityAudioFormat = new ActivityAudioStream.ActivityAudioFormat(SAMPLE_RATE, BITS_PER_SECOND, CHANNELS, FRAME_SIZE, AudioEncoding.PCM_SIGNED); >private PullAudioOutputStream pullStreamImpl; private ActivityAudioFormat activityAudioFormat; /** * ActivityAudioFormat is an internal format which contains metadata regarding the type of arrangement of * audio bits in this activity audio stream. */ static class ActivityAudioFormat < private long samplesPerSecond; private int bitsPerSample; private int channels; private int frameSize; private AudioEncoding encoding; public ActivityAudioFormat(long samplesPerSecond, int bitsPerSample, int channels, int frameSize, AudioEncoding encoding) < this.samplesPerSecond = samplesPerSecond; this.bitsPerSample = bitsPerSample; this.channels = channels; this.encoding = encoding; this.frameSize = frameSize; >/** * Fetch the number of samples played per second for the associated audio stream format. * * @return the number of samples played per second */ public long getSamplesPerSecond() < return samplesPerSecond; >/** * Fetch the number of bits in each sample of a sound that has this audio stream format. * * @return the number of bits per sample */ public int getBitsPerSample() < return bitsPerSample; >/** * Fetch the number of audio channels used by this audio stream format. * * @return the number of channels */ public int getChannels() < return channels; >/** * Fetch the default number of bytes in a frame required by this audio stream format. * * @return the number of bytes */ public int getFrameSize() < return frameSize; >/** * Fetch the audio encoding type associated with this audio stream format. * * @return the encoding associated */ public AudioEncoding getEncoding() < return encoding; >> /** * Enum defining the types of audio encoding supported by this stream. */ public enum AudioEncoding < PCM_SIGNED("PCM_SIGNED"); String value; AudioEncoding(String value) < this.value = value; >> >
Создание и запуск приложения
Нажмите клавишу F11 или выберите Запустить>Отладка. На консоли отобразится сообщение Say something (Скажите что-нибудь). В этот момент вы можете произнести на английском языке фразу или предложение, которое бот сможет распознать. Ваша речь передается боту через канал «Речь Direct Line», где она распознается и обрабатывается ботом. Ответ возвратится в качестве действия. Если ваш бот в качестве ответа возвращает речь, аудио воспроизводится с помощью класса AudioPlayer .
Создание голосового ассистента на Python, часть 1
Добрый день. Наверное, все смотрели фильмы про железного человека и хотели себе голосового помощника, похожего на Джарвиса. В этом посте я расскажу, как сделать такого ассистента с нуля. Моя программа будет написана на python 3 в операционной системе windows. Итак, поехали!
Работать наш ассистент будет по такому принципу:
- Постоянно «слушать» микрофон
- Распознавать слова в google
- Выполнять команду, либо отвечать
Для начала мы установим в систему windows русские голоса. Для этого переходим по ссылке и скачиваем голоса в разделе SAPI 5 -> Russian. Там есть 4 голоса, можно выбрать любой, какой вам понравится. Устанавливаем и идём дальше.
Нам нужно поставить библиотеку pyttsx3 для синтеза речи:
pip install pyttsx3Затем можно запустить тестовую программу и проверить правильность её выполнения.
import pyttsx3 text = 'какой-нибудь текст' tts = pyttsx3.init() rate = tts.getProperty('rate') #Скорость произношения tts.setProperty('rate', rate-40) volume = tts.getProperty('volume') #Громкость голоса tts.setProperty('volume', volume+0.9) voices = tts.getProperty('voices') # Задать голос по умолчанию tts.setProperty('voice', 'ru') # Попробовать установить предпочтительный голос for voice in voices: if voice.name == 'Anna': tts.setProperty('voice', voice.id) tts.say(text) tts.runAndWait()2) Распознавание речи
Существует много инструментов для распознавания речи, но они все платные. Поэтому я пытался найти бесплатное решение для моего проекта и нашёл её! Это библиотека speech_recognition.
pip install SpeechRecognitionТакже для работы с микрофоном нам необходима библиотека PyAudio.
pip install PyAudioУ некоторых людей возникает проблема с установкой PyAudio, поэтому следует перейти по этой ссылке и скачать нужную вам версию PyAudio. Затем ввести в консоль:
pip instal название скачанного файлаЗатем запускаете тестовую программу. Но перед этим вы должны исправить в ней device_index=1 на своё значение индекса микрофона. Узнать индекс микрофона можно с помощью этой программы:
import speech_recognition as sr for index, name in enumerate(sr.Microphone.list_microphone_names()): print("Microphone with name \"\" found for `Microphone(device_index=)`".format(index, name))Тест распознавания речи:
import speech_recognition as sr def record_volume(): r = sr.Recognizer() with sr.Microphone(device_index = 1) as source: print('Настраиваюсь.') r.adjust_for_ambient_noise(source, duration=0.5) #настройка посторонних шумов print('Слушаю. ') audio = r.listen(source) print('Услышала.') try: query = r.recognize_google(audio, language = 'ru-RU') text = query.lower() print(f'Вы сказали: ') except: print('Error') while True: record_volume()Если всё отлично, переходим дальше.
Если вы хотите, чтобы ассистент просто общался с вами (без ИИ), то это можно сделать с помощью бесплатного инструмента DialogFlow от Google. После того, как вы залогинетесь, вы увидите экран, где уже можно создать своего первого бота. Нажмите Create agent. Придумайте боту имя (Agent name), выберете язык (Default Language) и нажмите Create. Бот создан!
Чтобы добавить новые варианты ответов на разные вопросы, нужно создать новый intent. Для этого в разделе intents нажмите Create intent. Заполните поля «Название» и Training phrases, а затем ответы. Нажмите Save. Вот и всё.
Чтобы управлять ботом на python, нужно написать такой код. В моей программе бот озвучивает все ответы.
import apiai, json, re import pyttsx3 import speech_recognition as sr tts = pyttsx3.init() rate = tts.getProperty('rate') tts.setProperty('rate', rate-40) volume = tts.getProperty('volume') tts.setProperty('volume', volume+0.9) voices = tts.getProperty('voices') tts.setProperty('voice', 'ru') for voice in voices: if voice.name == 'Anna': tts.setProperty('voice', voice.id) def record_volume(): r = sr.Recognizer() with sr.Microphone(device_index = 1) as source: print('Настраиваюсь.') r.adjust_for_ambient_noise(source, duration=1) print('Слушаю. ') audio = r.listen(source) print('Услышала.') try: query = r.recognize_google(audio, language = 'ru-RU') text = query.lower() print(f'Вы сказали: ') textMessage( text ) except: print('Ошибка распознавания.') def talk( text ): tts.say( text ) tts.runAndWait() def textMessage( text ): request = apiai.ApiAI('ваш токен').text_request() # Токен API к Dialogflow request.lang = 'ru' # На каком языке будет послан запрос request.session_id = 'ваш id' # ID Сессии диалога (нужно, чтобы потом учить бота) request.query = text # Посылаем запрос к ИИ с сообщением от юзера responseJson = json.loads(request.getresponse().read().decode('utf-8')) response = responseJson['result']['fulfillment']['speech'] # Разбираем JSON и вытаскиваем ответ # Если есть ответ от бота - присылаем пользователю, если нет - бот его не понял if response: request.audio_output = response talk(response) else: talk('Простите. Я Вас не совсем поняла.') while True: record_volume()На сегодня всё. В следующей части я расскажу как сделать умного бота, т.е. чтобы он мог не только отвечать, но и что-либо делать.
- голосовой ассистент
- голосовой помощник
- python
- Python
- Программирование
- Разработка под Windows
alex-pat / Article.md
Save alex-pat/f90a97f9ead839e299c11f00bcab512c to your computer and use it in GitHub Desktop.
Голосовой помощник
Делаем голосового помощника своими руками

С самого выхода Космической одиссеи Стенли Кубрика люди мечтали иметь компьютер, с которым можно было бы общаться так же, как с другим человеком. Прошло уже почти полвека с момента выхода сей культовой картины, а технологии лишь недавно позволили людям приблизиться к технологиям воображаемого будущего. И хотя космические корабли всё ещё слабо бороздят Большой театр просторы Вселенной, говорящие бездушные помощники уже более чем реальность. Такие компании как Google и Amazon уже торгуют своими Home и Echo, хотя далеко не каждый может себе позволить такую колонку. За Google Home компания просит $130, а Amazon за своё детище — все $180.
Не будем забывать, что существует огромный пласт активного населения, которые жить не могут, а им дай поиграть с конфигами заточить всё под себя, да добавлять новые фичи по мере потребности и оживления фантазии.
Параллельно с этим контингентом живут люди с обострённым чувством паранойи волнения за приватность своих данных и отсутствие слежки, которые хотели бы пользоваться чем-то новым и удобным, но отправлять данные на сервера корпорации Добра не хотят.
Как быть? Стало быть, нужен относительно дешёвый вариант, лекго конфигуриремый, с открытыми исходниками, и желательно не вылезающего в Интернет без необходимости. Из ближайшего, что подходит на эту роль — Raspberry PI. Благо, необходимости строить свой велосипед нет, так как уже нашлись умельцы, адаптировавшие всё это добро под Малину. А наша задача — разобраться с этим, настроить и дописать своё. Имя этому — легион Jasper
Железо
- Собственно Raspberry (3 в моём случае)
- Динамик
- Микрофон
- Внешняя звуковая карта
Дело в том, что Малина не имеет при себе ничего, что способно оцифровывать сигнал с микрофона, поэтому перед нами два варианта: USB-микрофон (дороговато), либо обычный микрофон с джеком + USBшная звуковая карта (дёшево, сердито).
Cофт
Если обратить внимание, то все обладатели RPI в сети имеют при себе лишнюю клавиатуру и монитор, чего студент не может себе позволить. Как минимум они считаются необходимыми для первоначальной настройки ОС, а именно, для поднятия wifi и ssh. Когда я изначально пытался настроить это без вышеписанных девайсов, т.е. только при помощи правки конфигов на карте — включения — проверки наличия в локальной сети нового устройства, я столкнулся с проблемой, что в случае отсутствия адекватного устройства вывода нереально сложно отлаживать скрипты конфигурации. В конце концов я добился своего, используя в качестве устройства ввода/вывода файловую систему, но потом оказалось, что.
. разработчики Jasper поставляют образы системы с уже настроенным ssh, так что необходимо было только прописать SSID и пароль в конфиге wpa_supplicant.
Мораль — не спеши, хотя иногда полученный в результате отрицательный опыт тоже бывает полезен
Итак, Официальная документация говорит нам скачать у них образ, записать его на microSD классическим dd, либо можно всё поставить руками, ибо есть даже пакет в AUR.
Подвох в том, что убийца — дворецкий на половине проделанной работы, в поисках ответа на очередную ошибку при установке пакета ты натыкаешься на подобный вопрос на форуме поддержки Jasper, а человеку отвечают загадочной фразой «Посмотрите, что написано на главной странице форума, выделено жёлтым». Следуем этой наводке и видим:
NOTICE TO NEW USERS: Jasper Documentation/Image has not been updated on their site in a LONG TIME Please DO NOT USE THE IMAGE ON THE SITE! Please use the community image above. В этом, я бы сказал, одна из больших проблем сего творения: разработчики маленько (на самом деле, довольно сильно) подзабили на поддержку инфраструктуры в актуальном состоянии. Они даже успели сломать обратную совместимость между версиями, поправив только несколько модулей, из-за чего заметную часть полезных пользовательских модулей нужно самому переписывать под новую версию.
Итак, теперь сносим всё и начинаем заново, если успели что-то предпринять раньше. В домашней директории образа нас ждёт папка со скриптами, обещающими установить весь нужный софт с зависимостями без регистрации и смс . Да, здесь тоже подвох, ибо кое-что придётся собирать руками. Но об этом по порядку.
Основной пакет ставится относительно без проблем, а со вспомогательными уже наблюдаются трудности.
Так как мы решили большую часть производить прямо на борту Малины, то и распознавание голоса должно по нашей задумке происходить там же. Нам предлагается несколько вариантов:
- PocketSphinx — локально, на Сях, адаптировано под ARM, создано в университете Карнеги Меллон
- Google STT — то же, что и в мобилках, но необходима сеть, так что отпадает в нашем случае
- AT&T STT — онлайновый
- Wit.ai STT — онлайновый
- Julius — высокопроизводительный, локальный, но нужно тренировать свою аккустическую модель, что настолько сложно и опасно, что сами разработчики Jasper советуют использоать его только самым смелым.
Со сфинксом тоже не всё гладко. Дело в том, зависимостей у него достаточно, а способные установиться пакеты есть не для всего, так что около получаса жизни придётся выделить на компиляцию зависимости.
Теперь для вывода — вариантов TTS предлагается достаточно, начиная от встроенного в Android 1.6 Donut, заканчивая Стивеном Хокингом поделкой от того же университета Карнеги Меллон. Здесь время уйдёт уже на выбор голоса по вкусу.
Как это работает
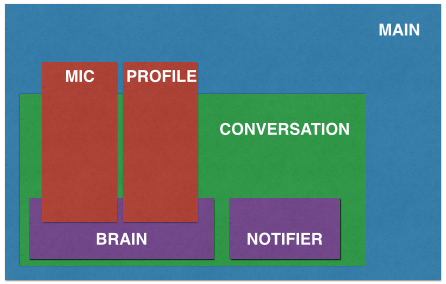
jasper.py организует вcю работу Джаспера. Он создает экземпляры микрофона, профиля и разговора. Затем экземпляр разговора получает микрофон и профиль в качестве входных данных, из которых он создает уведомитель и мозг. На самом деле, объект Mic отвечает здесь не только за микрофон, а за звук в принципе — через его метод say() можно дать указание машине зачитать текст.
Затем мозг получает микрофон и профиль, и загружает все интерактивные компоненты в память. Мозг по существу является интерфейсом между написанными разработчиком модулями и основной инфраструктурой.
Каждый модуль — файл в директории client/modules/ — должен реализовывать функции isValid() и handle(), а также определять список ключевых слов WORDS = [. ]. isValid() проверяет запрос на соответствие шаблону, handle — выполняет обработку запроса.
Например, модуль, отвечающий на вопрос о смысле жизни может быть таким:
import random import re WORDS = ["MEANING", "OF", "LIFE"] def handle(text, mic, profile): messages = ["It's 42, you idiot.", "It's 42. How many times do I have to tell you?"] message = random.choice(messages) mic.say(message) def isValid(text): return bool(re.search(r'\bmeaning of life\b', text, re.IGNORECASE))
Объект profile — настройки из файла ~/.jasper/profile.yml. Там могут быть как служебные данные (пути к файлам голосовых моделей, например), так и любая полезная информация (местоположение для модуля погоды).
Модули
Несмотря на то, что в глубинах гитхаба можно найти неплохие модули, большая часть из них либо не рабочая сама по себе, либо устарела и не соответствует API, поэтому всё равно нужно переписывать.
Некоторые полезные мои и переписанные чужие модули можно найти здесь.
/etc
Стоит отметить, что расширению легко поддаются не только собственно модули, но и внутрянняя кухня Джаспера. Однажды я понял, что мне не хватает тех двух способов запуска: голосового и текстового, а мне нужнен ещё один: ввод с клавиатуры, ответ в виде текста и звука. И сделать это оказалось очень легко, ведь во время парсинга агрументов командной строки просто импоритруеются «микрофоны» из разных файлов, но с разной реализацией методов.
if args.local: from client.local_mic import Mic else: from client.mic import Mic
такой вот своеобразный способ реализации паттернов, но вполне себе рабочий.
Локальное распознавание голоса. Оно, честно говоря, слабовато, то ли из-за самой используемой техники, то ли из-за дешёвого микрофона.
Итоги
Две с половиной недели назад Google совместно с Raspberry создали то же самое, только с Google Assistant на борту, и практически за те же деньги. Интересное ощущение, когда сначала ты начинаешь делать курсовую, а потом её делает Google.