Функция ХИ2.ТЕСТ
Возвращает критерий независимости. Функция ХИ2.ТЕСТ возвращает значение статистики для распределения хи-квадрат (χ2) и соответствующее число степеней свободы. Критерий χ2 можно использовать для определения того, подтверждается ли гипотеза экспериментом.
Синтаксис
Аргументы функции ХИ2.ТЕСТ описаны ниже.
- Фактический_интервал — обязательный аргумент. Интервал данных, который содержит результаты наблюдений, подлежащие сравнению с ожидаемыми значениями.
- Ожидаемый_интервал — обязательный аргумент. Интервал данных, который содержит отношение произведений итогов по строкам и столбцам к общему итогу.
Замечания
- Если фактический интервал и ожидаемый интервал имеют различное количество точек данных, функция ХИ2.ТЕСТ возвращает значение ошибки #Н/Д.
- Критерий χ2 сначала вычисляет статистику χ2 по формуле:
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу Enter. При необходимости измените ширину столбцов, чтобы видеть все данные.
Мужчины (фактически)
Женщины (фактически)
Как построить распределение хи-квадрат в Excel
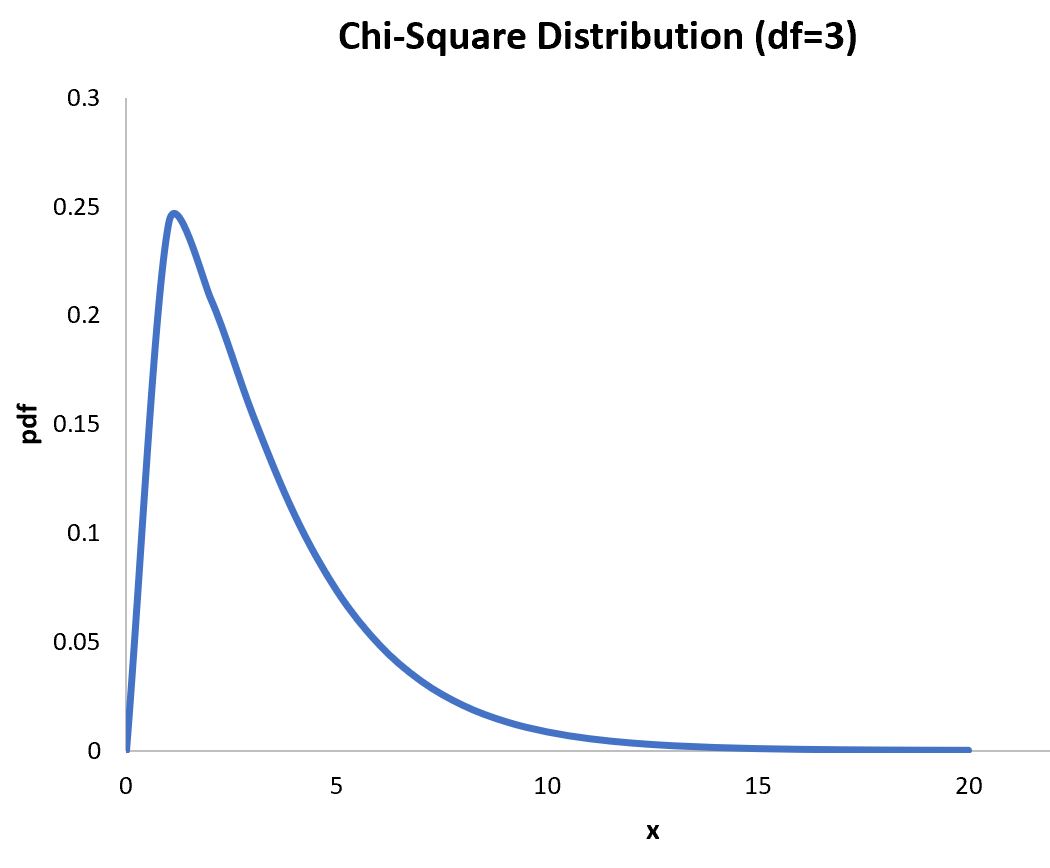
В этом пошаговом руководстве объясняется, как построить следующее распределение хи-квадрат в Excel:
Шаг 1: Определите значения X
Во-первых, давайте определим диапазон значений x для использования на нашем графике.
Для этого примера мы создадим диапазон от 0 до 20:

Шаг 2: Рассчитайте значения Y
Значения y на графике будут представлять значения PDF, связанные с распределением хи-квадрат.
Мы можем ввести следующую формулу в ячейку B2 , чтобы вычислить значение PDF распределения хи-квадрат, связанное со значением x, равным 0, и значением степеней свободы, равным 3:
=CHISQ.DIST( A2 , $E$1 , FALSE) Затем мы можем скопировать и вставить эту формулу в каждую оставшуюся ячейку в столбце B:

Шаг 3: Постройте распределение хи-квадрат
Затем выделите диапазон ячеек A2:B22 , затем щелкните вкладку « Вставка » на верхней ленте, затем щелкните параметр « Разброс » в группе « Диаграммы » и нажмите « Разброс с плавными линиями» :

Будет создана следующая диаграмма:

На оси x показаны значения случайной величины , которая соответствует распределению хи-квадрат с 3 степенями свободы, а на оси y показаны соответствующие значения PDF распределения хи-квадрат.
Обратите внимание, что если вы измените значение степеней свободы в ячейке E1 , диаграмма автоматически обновится.
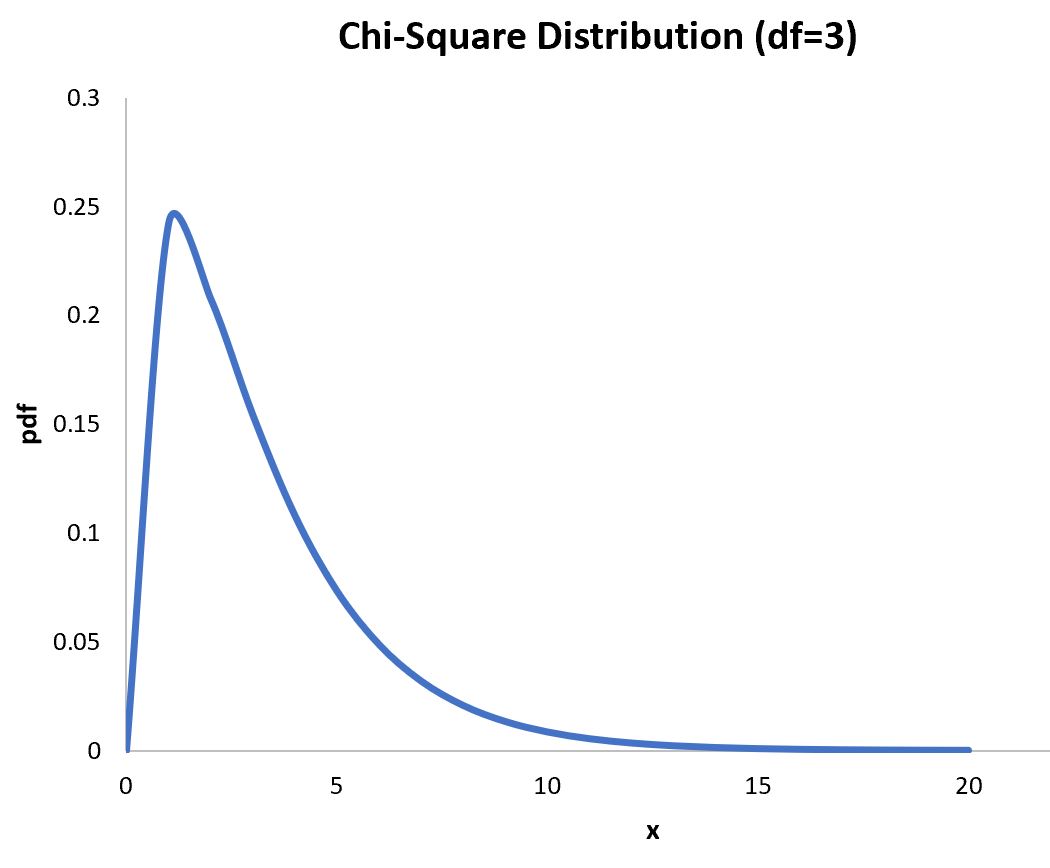
Например, мы могли бы изменить количество степеней свободы на 7:

Обратите внимание, что форма графика автоматически изменяется, отражая распределение хи-квадрат с 7 степенями свободы.
Шаг 4: Измените внешний вид графика
Не стесняйтесь добавлять заголовок, метки осей и удалять линии сетки, чтобы сделать график более эстетичным:
Дополнительные ресурсы
В следующих руководствах объясняется, как построить другие распространенные распределения в Excel:
Критерий независимости хи-квадрат в EXCEL
Критерий независимости хи-квадрат используется для определения связи между двумя категориальными переменными. Примерами пар категориальных переменных являются: Семейное положение vs. Уровень занятости респондента; Порода собак vs. Профессия хозяина, Уровень з/п vs. Специализация инженера и др. При вычислении критерия независимости проверяется гипотеза о том, что между переменными связи нет. Вычисления будем производить с помощью функции MS EXCEL 2010 ХИ2.ТЕСТ() и обычными формулами.
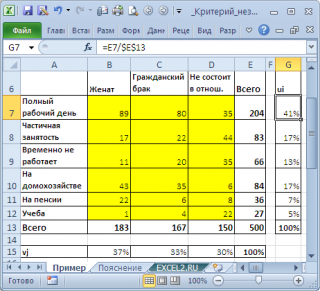
Предположим у нас есть выборка данных, представляющая результат опроса 500 человек. Людям задавалось 2 вопроса: про их семейное положение (женаты, гражданский брак, не состоят в отношениях) и их уровень занятости (полный рабочий день, частичная занятость, временно не работает, на домохозяйстве, на пенсии, учеба). Все ответы поместили в таблицу:
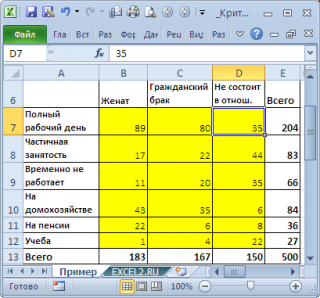
Данная таблица называется таблицей сопряжённости признаков (или факторной таблицей, англ. Contingency table). Элементы на пересечении строк и столбцов таблицы обычно обозначают O ij (от англ. Observed, т.е. наблюденные, фактические частоты).
Нас интересует вопрос «Влияет ли Семейное положение на Занятость?», т.е. существует ли зависимость между двумя методами классификации выборки ?
При проверке гипотез такого вида обычно принимают, что нулевая гипотеза утверждает об отсутствии зависимости способов классификации.
Рассмотрим предельные случаи. Примером полной зависимости двух категориальных переменных является вот такой результат опроса:
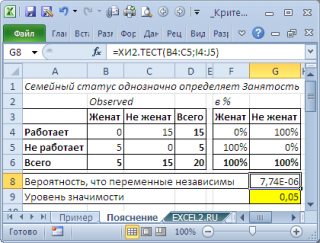
В этом случае семейное положение однозначно определяет занятость (см. файл примера лист Пояснение ). И наоборот, примером полной независимости является другой результат опроса:
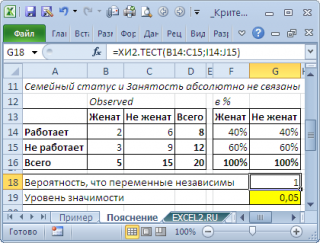
Обратите внимание, что процент занятости в этом случае не зависит от семейного положения (одинаков для женатых и не женатых). Это как раз совпадает с формулировкой нулевой гипотезы . Если нулевая гипотеза справедлива, то результаты опроса должны были бы так распределиться в таблице, что процент занятых был бы одинаковым независимо от семейного положения. Используя это, вычислим результаты опроса, которые соответствуют нулевой гипотезе (см. файл примера лист Пример ).
Сначала вычислим оценку вероятности, того, что элемент выборки будет иметь определенную занятость (см. столбец u i ):
где с – количество столбцов (columns), равное количеству уровней переменной «Семейное положение».
Затем вычислим оценку вероятности, того, что элемент выборки будет иметь определенное семейное положение (см. строку v j ).
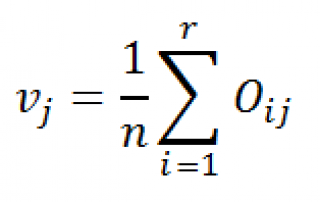
где r – количество строк (rows), равное количеству уровней переменной «Занятость».
Теоретическая частота для каждой ячейки E ij (от англ. Expected, т.е. ожидаемая частота) в случае независимости переменных вычисляется по формуле: E ij =n* u i * v j
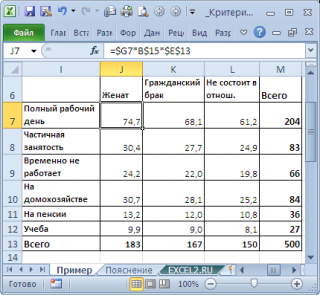
Известно, что статистика Х 2 0 при больших n имеет приблизительно ХИ2-распределение с (r-1)(c-1) степенями свободы (df – degrees of freedom):
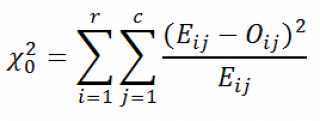
Примечание : Вышеуказанная статистика при с=1 используется для вычисления критерия согласия Пирсона ХИ-квадрат (см. статью Проверка гипотез критерием хи-квадрат Пирсона в MS EXCEL ).
Если вычисленное на основе выборки значение этой статистики «слишком большое» (больше порогового), то нулевая гипотеза отвергается. Пороговое значение вычисляется на основании уровня значимости , например с помощью формулы =ХИ2.ОБР.ПХ(0,05; df) .
Примечание : Уровень значимости обычно принимается равным 0,1; 0,05; 0,01.
При проверке гипотезы также удобно вычислять p-значение , которое мы сравниваем с уровнем значимости . p -значение рассчитывается с использованием ХИ2-распределения с (r-1)*(c-1)=df степеней свободы.
Если вероятность, того что случайная величина имеющая ХИ2-распределение с (r-1)(c-1) степенями свободы примет значение больше вычисленной статистики Х 2 0 , т.е. P (r-1)*(c-1) >Х 2 0 >, меньше уровня значимости , то нулевая гипотеза отклоняется.
В MS EXCEL p-значение можно вычислить с помощью формулы =ХИ2.РАСП.ПХ(Х 2 0 ;df) , конечно, вычислив непосредственно перед этим значение статистики Х 2 0 (это сделано в файле примера ). Однако, удобнее всего воспользоваться функцией ХИ2.ТЕСТ() . В качестве аргументов этой функции указываются ссылки на диапазоны содержащие фактические (Observed) и вычисленные теоретические частоты (Expected).
Если уровень значимости > p -значения , то означает это фактические и теоретические частоты, вычисленные из предположения справедливости нулевой гипотезы , серьезно отличаются. Поэтому, нулевую гипотезу нужно отклонить.
Использование функции ХИ2.ТЕСТ() позволяет ускорить процедуру проверки гипотез , т.к. не нужно вычислять значение статистики . Теперь достаточно сравнить результат функции ХИ2.ТЕСТ() с заданным уровнем значимости .
Примечание : Функция ХИ2.ТЕСТ() , английское название CHISQ.TEST, появилась в MS EXCEL 2010. Ее более ранняя версия ХИ2ТЕСТ() , доступная в MS EXCEL 2007 имеет тот же функционал. Но, как и для ХИ2.ТЕСТ() , теоретические частоты нужно вычислить самостоятельно.
СОВЕТ : О проверке других видов гипотез см. статью Проверка статистических гипотез в MS EXCEL .
Хи квадрат как считать эксель
Argument ‘Topic id’ is null or empty
Сейчас на форуме
© Николай Павлов, Planetaexcel, 2006-2023
info@planetaexcel.ru
Использование любых материалов сайта допускается строго с указанием прямой ссылки на источник, упоминанием названия сайта, имени автора и неизменности исходного текста и иллюстраций.
| ООО «Планета Эксел» ИНН 7735603520 ОГРН 1147746834949 |
ИП Павлов Николай Владимирович ИНН 633015842586 ОГРНИП 310633031600071 |