Нормализация данных (Data normalization)
В машинном обучении нормализацией называют метод предобработки числовых признаков в обучающих наборах данных с целью приведения их к некоторой общей шкале без потери информации о различии диапазонов.
Иногда нормализацию данных называют стандартизацией, однако это неверно. Стандартизация это более широкое понятие и подразумевает предобработку с целью приведению данных к единому формату и представлению, наиболее удобному для использования определённого вида обработки. В отличии от нормализации, стандартизация может применяться и к категориальным данным.
Необходимость нормализации вызвана тем, что разные признаки обучающего набора данных могут быть представлены в разных масштабах и изменяться в разных диапазонах. Например, возраст, который изменяется от 0 до 100, и доход, изменяющийся от нескольких тысяч до нескольких миллионов. То есть диапазоны изменения признаков «Возраст» и «Доход» различаются в тысячи раз.
В этом случае возникает нарушение баланса между влиянием входных переменных, представленных в разных масштабах, на выходную переменную. Т.е. это влияние обусловлено не реальной зависимостью, а изменением масштаба. В результате, обучаемая модель может выявить некорректные зависимости.
Существует несколько основных методов нормализации.
Десятичное масштабирование (decimal scaling)
В данном методе нормализация производится путём перемещения десятичной точки на число разрядов, соответствующее порядку числа: x ′ i = x i / 10 n , где n — число разрядов в наибольшем наблюдаемом значении. Например, пусть имеется набор значений: -10, 201, 301, -401, 501, 601, 701. Поскольку n=3, то получим x ′ i = x i / 10 3 . Иными словами, каждое наблюдаемое значение делим на 1000 и получаем: -0.01, 0.201, 0.301, -0.401, 0.501, 0.601, 0.701.
Минимаксная нормализация
Несложно увидеть недостаток предыдущего метода: результирующие значения всегда будут занимать не весь диапазон [0,1], а только его часть, в зависимости от наибольшего и наименьшего наблюдаемых значений. Если исходный диапазон мал (скажем, 400 — 500), то получим, что в результате десятичного масштабирование нормализованные значения будут лежать в диапазоне [0.4,0.5], т.е. его изменчивость окажется очень низкой, что плохо сказывается на качестве построенной модели.
Решить проблему можно путём применения минимаксной нормализации, которая реализуется по формуле:
X ′ = X − X m i n X m a x − X m i n .
Эту формулу можно обобщить на привидение исходного набора значений к произвольному диапазону [ a , b ] :
X ′ = a + X − X m i n X m a x − X m i n ( b − a ) .
Наиболее часто используется приведение к диапазонам [0,1] и [-1,1]
Нормализация средним (Z-нормализация)
Недостаткам минимаксной нормализации является наличие аномальных значений данных, которые «растягивают» диапазон, что приводит к тому, что нормализованные значения опять же концентрируются в некотором узком диапазоне вблизи нуля. Чтобы избежать этого, следует определять диапазон не с помощью максимальных и минимальных значений, а с помощью «типичных» — среднего и дисперсии:
x ′ i = ( x i − ¯ ¯¯¯ ¯ X ) / σ x .
Величины, полученные по данной формуле, в статистике называют Z-оценками. Их Абсолютное значение представляет собой оценку (в единицах стандартного отклонения) расстояния между x и его средним значением ¯ ¯¯¯ ¯ X в общей совокупности. Если z меньше нуля, то x ниже средней, а если z больше нуля, то x выше средней.
Отношение
В этом методе каждое значение исходных данных делиться на некоторое, заданное пользователем число, или на значение статистического показателя, вычисленного по набору данных, например, среднее, стандартное отклонение, дисперсию, вариационный размах и др.
Нормализация компонента данных
В этой статье описывается компонент в конструкторе Машинного обучения Azure.
Используйте этот компонент для преобразования набора данных посредством нормализации.
Нормализация — это метод, который часто применяется как часть подготовки данных для машинного обучения. Цель нормализации — изменить значения числовых столбцов в наборе данных для использования общей шкалы без искажения различий в диапазонах значений или потери информации. Нормализация также требуется для некоторых алгоритмов для правильного моделирования данных.
Например, предположим, что ваш входной набор данных содержит один столбец со значениями от 0 до 1 и другой столбец со значениями от 10 000 до 100 000. Большая разница в масштабе чисел может вызвать проблемы, когда вы попытаетесь объединить значения как функции во время моделирования.
Нормализация позволяет избежать этих проблем, создавая новые значения, которые поддерживают общее распределение и соотношения в исходных данных, сохраняя при этом значения в пределах шкалы, применяемой ко всем числовым столбцам, используемым в модели.
Этот компонент предлагает несколько вариантов преобразования числовых данных:
- Вы можете изменить все значения на шкалу 0–1 или преобразовать значения, представив их как процентильные ранги, а не абсолютные значения.
- Нормализацию можно применить к одному столбцу или к нескольким столбцам в одном наборе данных.
- Если вам нужно повторить конвейер или применить те же шаги нормализации к другим данным, вы можете сохранить эти шаги как преобразование нормализации и применить его к другим наборам данных с такой же схемой.
Для некоторых алгоритмов требуется, чтобы данные были нормализованы до обучения модели. Другие алгоритмы выполняют собственное масштабирование или нормализацию данных. Поэтому, когда вы выбираете алгоритм машинного обучения для использования при построении прогнозной модели, обязательно ознакомьтесь с требованиями алгоритма к данным, прежде чем применять нормализацию к обучающим данным.
Настройка нормализации данных
С помощью этого компонента вы можете применять только один метод нормализации за раз. Таким образом, ко всем выбранным столбцам применяется один и тот же метод нормализации. Чтобы использовать другие методы нормализации, используйте второй экземпляр Нормализации данных.
- Добавьте компонент Нормализация данных в свой конвейер. Вы можете найти компонент в Машинном обучении Azure в разделе Преобразование данных в категории Масштабирование и уменьшение.
- Подключите набор данных, содержащий хотя бы один столбец всех чисел.
- Используйте селектор столбцов, чтобы выбрать числовые столбцы для нормализации. Если вы не выбираете отдельные столбцы, по умолчанию включаются все столбцы числового типа во входных данных, и ко всем выбранным столбцам применяется один и тот же процесс нормализации. Это может привести к странным результатам, если вы включите числовые столбцы, которые не следует нормализовать! Всегда внимательно проверяйте колонки. Если числовые столбцы не обнаружены, проверьте метаданные столбца, чтобы убедиться, что тип данных столбца является поддерживаемым числовым типом.
Совет Чтобы гарантировать, что столбцы определенного типа предоставляются в качестве входных данных, попробуйте использовать компонент Выбрать столбцы в наборе данных перед Нормализацией данных.
- Zscore: преобразует все значения в z-оценку. Значения в столбце преобразуются по следующей формуле:
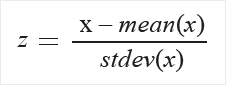 Среднее и стандартное отклонения вычисляются для каждого столбца отдельно. Используется стандартное отклонение совокупности.
Среднее и стандартное отклонения вычисляются для каждого столбца отдельно. Используется стандартное отклонение совокупности. - MinMax: нормализатор min-max линейно изменяет масштаб каждой функции до интервала [0,1]. Масштабирование в интервале [0,1] осуществляется путем сдвига значений каждого компонента таким образом, чтобы минимальное значение было равно 0, а затем деления на новое максимальное значение (которое представляет собой разницу между первоначальными максимальными и минимальными значениями). Значения в столбце преобразуются по следующей формуле:
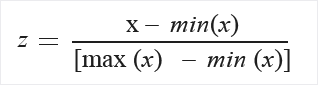
- Логистика: значения в столбце преобразуются по следующей формуле:
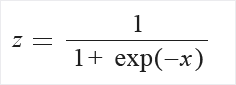
- LogNormal: значения в столбце преобразуются по следующей формуле. Значения в столбце преобразуются по следующей формуле:
 AML_normalization Здесь μ и σ — параметры распределения, вычисленные эмпирически на основе данных как оценки максимального правдоподобия для каждого столбца отдельно.
AML_normalization Здесь μ и σ — параметры распределения, вычисленные эмпирически на основе данных как оценки максимального правдоподобия для каждого столбца отдельно. - TanH: все значения преобразуются в гиперболический тангенс. Значения в столбце преобразуются по следующей формуле:
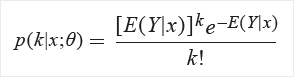
Результаты
Компонент Нормализации данных генерирует два вывода:
- Чтобы просмотреть преобразованные значения, щелкните компонент правой кнопкой мыши и выберите Визуализировать. По умолчанию значения преобразуются на месте. Если вы хотите сравнить преобразованные значения с исходными значениями, используйте компонент Добавить столбцы, чтобы повторно объединить наборы данных и просмотреть столбцы рядом.
- Чтобы сохранить преобразование, чтобы можно было применить тот же метод нормализации к другому набору данных, выберите компонент и выберите Зарегистрировать набор данных на вкладке Выходные данные на правой панели. Затем вы можете загрузить сохраненные преобразования из группы Преобразования на левой панели навигации и применить их к набору данных с той же схемой, используя Применить преобразование.
Дальнейшие действия
Ознакомьтесь с набором доступных компонентов для Машинного обучения Azure.
Что такое нормализация базы данных?
![]()
Нормализация базы данных (БД) — это метод проектирования реляционных БД, который помогает правильно структурировать таблицы данных. Процесс направлен на создание системы с четким представлением информации и взаимосвязей, без избыточности и потери данных.
В данной статье рассказывается, что такое нормализация базы данных, и объясняются принципы ее работы на практическом примере.
Что такое нормализация базы данных?
Нормализация базы данных — это метод создания таблиц БД со столбцами и ключами путем разделения (или декомпозиции) таблицы большего размера на небольшие логические единицы. В данном методе учитываются требования, предъявляемые к среде БД.
Нормализация — это итеративный процесс. Как правило, нормализация БД выполняется через серию тестов. Каждый последующий шаг разбивает таблицу на более легкую в управлении информацию, чем повышается общая логичность системы и простота работы с ней.
Зачем нужна нормализация базы данных?
Нормализация позволяет разработчику БД оптимально распределять атрибуты по таблицам. Данная методика избавляет от:
- атрибутов с несколькими значениями;
- задвоения или повторяющихся атрибутов;
- атрибутов, не поддающихся классификации;
- атрибутов с избыточной информацией;
- атрибутов, созданных из других признаков.
Необязательно выполнять полную нормализацию БД. Однако она гарантирует полноценно функционирующую информационную среду. Этот метод:
- позволяет создать структуру базы данных, подходящую для общих запросов;
- сводит к минимуму избыточность данных, что повышает эффективность использования памяти на сервере БД;
- гарантирует максимальную целостность данных, устраняя аномалий вставки, обновления и удаления.
Нормализация базы данных преобразует общую целостность данных в удобную для пользователя среду.
Избыточность баз данных и аномалии
Когда вы вносите изменения в таблицу избыточностью, вам придется корректировать все повторяющиеся экземпляры данных и связанные с ними объекты. Если этого не сделать, то таблица станет несогласованной, и при внесении изменений возникнут аномалии.
Так выглядит таблица без нормализации:

Для таблицы характерна избыточность данных, а при изменении этих данных возникают 3 аномалии:
- Аномалия вставки. При добавлении нового «Сотрудника» (employee) в «Отдел» (sector) Finance, обязательно указывается его «Руководитель» (manager). Иначе вы не сможете вставить данные в таблицу.
- Аномалия обновления. Когда сотрудник переходит в другой отдел, поле «Руководитель» содержит ошибочные данные. К примеру, Джейкоб (Jacob) перешел в отдел Finance, но его руководителем по-прежнему показывается Адам (Adam).
- Аномалия удаления. Если Джошуа (Joshua) решит уволиться из компании, то при удалении строки с его записью потеряется информация о том, что отдел Finance вообще существует.
Для устранения подобных аномалий используется нормализация базы данных.
Основные понятия в нормализации базы данных
Простейшие понятия, используемые в нормализации базы данных:
- ключи — атрибуты столбцов, которые однозначно (уникально) определяют запись в БД;
- функциональные зависимости — ограничения между двумя взаимосвязанными атрибутами;
- нормальные формы — этапы для достижения определенного качества БД.
Нормальные формы базы данных
Нормализация базы данных выполняется с помощью набора правил. Такие правила называются нормальными формами. Основная цель данных правил — помочь разработчику БД в достижении нужного качества реляционной базы.
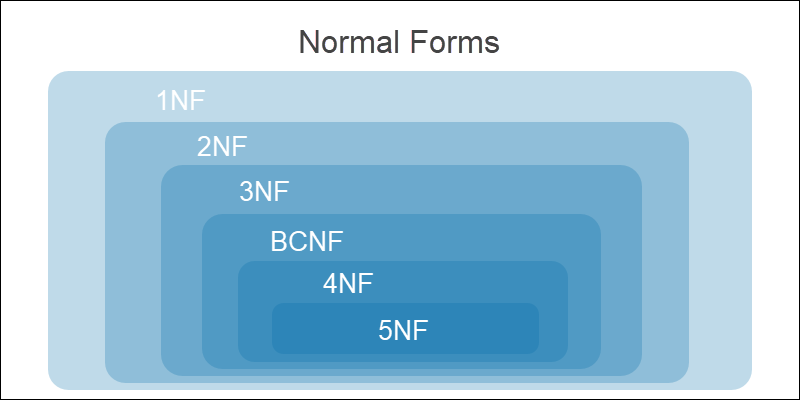
Все уровни нормализации считаются кумулятивными, или накопительными. Прежде чем перейти к следующему этапу, выполняются все требования к текущей форме.
Аномалии избыточности
Ненормализованная (нулевая) форма (UNF)
Это состояние перед любой нормализацией. В таблице присутствуют избыточные и сложные значения
Первая нормальная форма (1NF)
Разбиваются повторяющиеся и сложные значения; все экземпляры становятся атомарными
Вторая нормальная форма (2NF)
Частичные зависимости разделяются на новые таблицы. Все строки функционально зависимы от первичного ключа
Третья нормальная форма (3NF)
Транзитивные зависимости разбиваются на новые таблицы. Не ключевые атрибуты зависят от первичного ключа
Нормальная форма Бойса-Кода (BCNF)
Транзитивные и частичные функциональные зависимости для всех потенциальных ключей разбиваются на новые таблицы
Четвертая нормальная форма (4NF)
Удаляются многозначные зависимости
Пятая нормальная форма (5NF)
Удаляются JOIN-зависимости (зависимости соединения)
База данных считается нормализованной после достижения третьей нормальной формы. Дальнейшие этапы нормализации усложняю структуру БД и могут нарушить функционал системы.
Что такое Ключ?
Ключ БД (key) — это атрибут или группа признаков, которые однозначно описывают сущность в таблице. В нормализации используются следующие типы ключей:
- суперключ (Super Key) — набор признаков, которые уникально определяют каждую запись в таблице;
- потенциальный ключ (Candidate Key) — выбирается из набора суперключей с минимальным количеством полей;
- первичный ключ (Primary Key) — самый подходящий кандидат из набора потенциальных ключей; служит первичным ключом таблицы;
- внешний ключ (Foreign Key) — первичный ключ другой таблицы;
- составной ключ (Composite Key) — уникальный ключ, образованный двумя и более атрибутами, каждый из которых по отдельности не является ключом.
Поскольку таблицы разделяются на несколько более простых единиц, именно ключи определяют точку ссылки для объекта БД.
Например, в следующей структуре базы данных:

Примерами суперключей являются:
Все суперключи служат уникальным идентификатором каждой строки. К примеру, имя сотрудника и его возраст не считаются уникальными идентификаторами, поскольку несколько людей могут быть тезками и одногодками.
Потенциальные ключи выбираются из набора суперключей с минимальным количеством полей. В нашем примере это:
Оба параметра содержат минимальное количество полей, поэтому они хорошо подходят на роль потенциальных ключей. Самый логичный выбор для первичного ключа — поле employeeID, поскольку почта сотрудника может измениться. На такой первичный ключ легко ссылаться в другой таблице, для которой он будет считаться внешним ключом.
Функциональные зависимости базы данных
Функциональная зависимость БД отражает взаимосвязь между двумя атрибутами таблицы. Функциональные зависимости бывают следующих типов:
- тривиальная функциональная зависимость — зависимость между атрибутом и группой признаков; исходный элемент является частью группы;
- нетривиальная функциональная зависимость — зависимость между атрибутом и группой признаков; признак не является частью группы;
- транзитивная зависимость — функциональная зависимость между тремя атрибутами: второй атрибут зависит от первого, а третий — от второго. Благодаря транзитивности, третий атрибут зависит от первого;
- многозначная зависимость — зависимость, в которой несколько значений зависят от одного атрибута.
Функциональные зависимости — это важный этап в нормализации БД. В долгосрочной перспективе такие зависимости помогают оценить общее качество базы данных.
Примеры нормализации базы данных. Как нормализовать базу данных?
Общие этапы в нормализации базы данных подходят для всех таблиц. Конкретные методы разделения таблицы, а также вариант прохождения или не прохождения через третью нормальную форму (3NF) зависят от примеров использования.
Пример ненормализованной базы данных
В одном столбце ненормализованной таблицы содержится несколько значений. В худшем случае в ней присутствует избыточная информация.
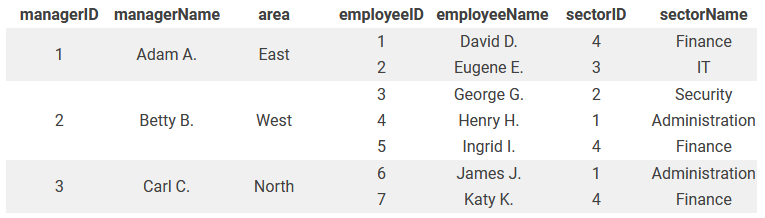
Добавление, обновление и удаление данных — все это сложные задачи. Выполнение любых изменений текущих данных сопряжено с высоким риском потери информации.
Шаг 1: Первая нормальная форма (1NF)
Для преобразования таблицы в первую нормальную форму значения полей должны быть атомарными. Все сложные сущности таблицы разделяются на новые строки или столбцы.
Чтобы не потерять информацию, для каждого сотрудника дублируются значения столбцов managerID, managerName и area.
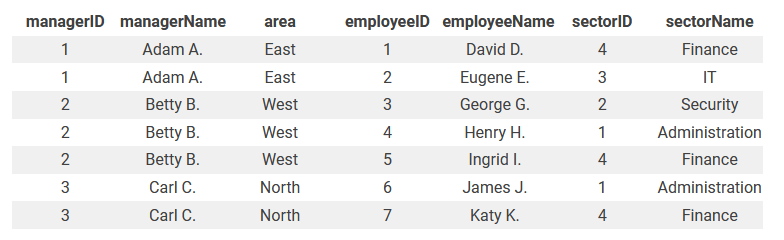
Доработанная таблица соответствует первой нормальной форме.
Шаг 2: Вторая нормальная форма (2NF)
Во второй нормальной форме каждая строка таблицы должна зависеть от первичного ключа.
Чтобы таблица соответствовала критериям этой формы, ее необходимо разделить на 2 части:
Manager (managerID, managerName, area)

Employee (employeeID, employeeName, managerID, sectorID, sectorName)
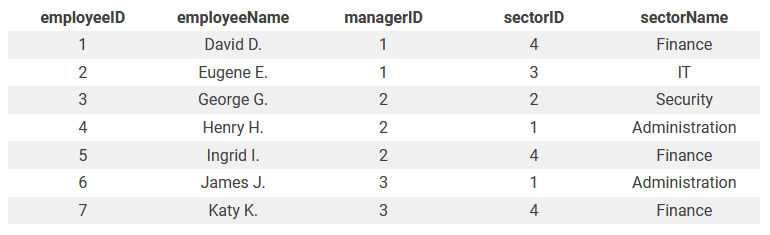
Итоговая таблица во второй нормальной форме представляет собой 2 таблицы без частичных зависимостей.
Шаг 3: третья нормальная форма (3NF)
Третья нормальная форма разделяет любые транзитивные функциональные зависимости. В нашем примере транзитивная зависимость есть у таблицы Employee; она разбивается на 2 новых таблицы:
Employee (employeeID, employeeName, managerID, sectorID)
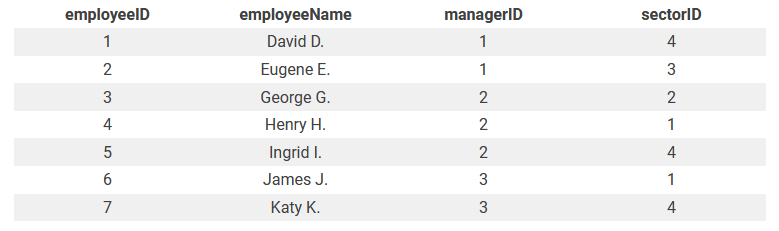
Sector (sectorID, sectorName)

Теперь таблица соответствует третьей нормальной форме с тремя взаимосвязями. Конечная структура выглядит так:

Теперь база данных считается нормализованной. Дальнейшая нормализация зависит от ваших конкретных целей.
Заключение
В статье рассказывалось, как с помощью нормализации БД можно сократить избыточность информации. В долгосрочной перспективе нормализация БД позволяет свести к минимуму потерю данных и улучшить их общую структуру.
Если же вы хотите повысить производительность доступа к данным, то воспользуйтесь денормализацией БД.
А если вы испытываете трудности с нормализацией базы данных, то рассмотрите возможность перехода на другой тип БД.
Что такое нормализация баз данных?
Статья расскажет о том, что такое нормализация баз данных, для чего она нужна, и какие виды нормализации существуют. Для наилучшего понимания отношений между таблицами в нормализованной базе данных будут приведены практические примеры.
При создании базы нужно учитывать некоторые правила. Исходя из вышесказанного, можно привести следующую формулировку: нормализация БД — это процесс организации данных определенным образом и рекомендации по проектированию. То есть таблицы и связи между ними (отношения) создаются в соответствии с правилами. В результате обеспечивается нужный уровень безопасности данных, а сама база становится более гибкой. Также устраняются несогласованные зависимости и избыточность.
Плюсы
Нормализация не является обязательной, но приносит следующие преимущества: — упрощается процесс выборки. Речь идет об упрощении работы по составлению запросов, то есть пользователь сможет получать нужную информацию относительно простыми запросами; — обеспечивается целостность данных. Можно говорить о минимизации искажения информации и снижении вероятности потери данных; — улучшается масштабируемость. При соблюдении правил нормализации формируются благоприятные предпосылки к росту БД; — отсутствует избыточность (data redundancy). Избыточность — известная проблема непродуктивного использования свободного места на жестком диске, затрудняющая обслуживание БД. В отдельных случаях эту проблему усугубляет и то, что в случае необходимости изменения записей однотипных данных, хранимых в нескольких местах (таблицах), пользователю придется вносить требуемые изменения везде, что весьма трудоемкое занятие. Гораздо проще сделать так, чтобы, к примеру, данные о городах хранились только в таблице Cities и нигде больше. Если подытожить вышесказанное, избыточность предполагает дублирование данных, а это не только усложняет работу с БД, но и увеличивает ее размер; — отсутствие несогласованных зависимостей. Несогласованные зависимости затрудняют доступ к данным, ведь путь к такой информации может быть неправилен и нелогичен. В той же таблице Cities логично искать города, количество жителей и т. п., но не адреса и имена жителей — для этой информации уже нужна другая таблица — Citizens.
Как выполнить нормализацию?
Чтобы привести БД к нормальной форме, необходимо: 1. Объединить имеющиеся данные в группы. 2. Выяснить логические связи между группами. Чтобы обеспечить правильность связей, связываемые поля должны иметь один тип.
Если таблица не нормализована, она может хранить информацию о нескольких сущностях и включать в себя повторяющиеся столбцы, а они, в свою очередь, могут хранить дублируемые значения. Если же нормализована, то каждая таблица хранит информацию лишь об одной сущности.
При нормализации предполагается использование нормальных форм по отношению к структуре имеющихся данных. Есть несколько правил нормализации. Каждое из них носит название «нормальная форма» (НФ). Каждая такая форма, кроме первой, предполагает, что к данным уже применили предыдущую нормальную форму. При выполнении первого правила БД представлено в первой нормальной форме (1НФ), при выполнении трех правил — в третьей нормальной форме (3НФ).
Таких форм (уровней) — семь, однако на практике для большей части приложений вполне достаточно нормализовать БД до третьей нормальной формы (строго говоря, БД и будет считаться нормализованной, когда к ней применяется 3НФ и выше).
Да, обеспечить полное соответствие правилам и спецификациям — задача не всегда выполнимая, ведь для нормализации придется создавать дополнительные таблицы, а это не всегда приемлемо или не находит отклика у клиентов. Но если правила приходится нарушать, надо понимать, что все, связанные с этим проблемы, включая несогласованные зависимости и избыточность, будут учтены, и что это допустимо для приложения, не нарушит его работоспособность.
Правила нормализации на примерах
Первая нормальная форма (1НФ)
Согласно правилам, все атрибуты в такой таблице должны быть простыми, все сохраняемые данные на пересечении столбцов и строк — содержать лишь скалярные значения. Также не должно быть повторяющихся строк.
Для примера возьмем таблицу с автомобилями:

Обратите внимание на нарушение нормализации в моделях BMW — в одной ячейке находится перечень из трех элементов: M5, X5M, M1, то есть можно говорить об отсутствии атомарности. После преобразования в 1НФ таблица меняет вид:
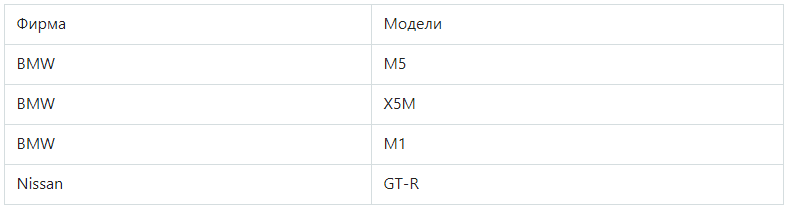
Вторая нормальная форма (2НФ)
Отношения будут соответствовать 2НФ, если сама БД находится в 1НФ, а каждый столбец, который не является ключом, зависит от первичного ключа.
Рассмотрим очередную таблицу:
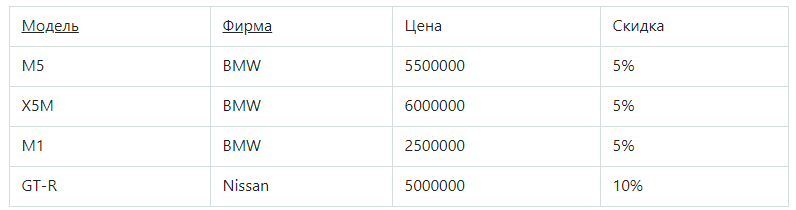
Она в 1НФ, но не во 2НФ. Стоимость авто зависит от модели и производителя. Размер скидки зависит от производителя, поэтому функциональная зависимость от первичного ключа является неполной. Исправить это можно, выполнив декомпозицию на 2 отношения, где неключевые атрибуты будут зависеть от первичного ключа.
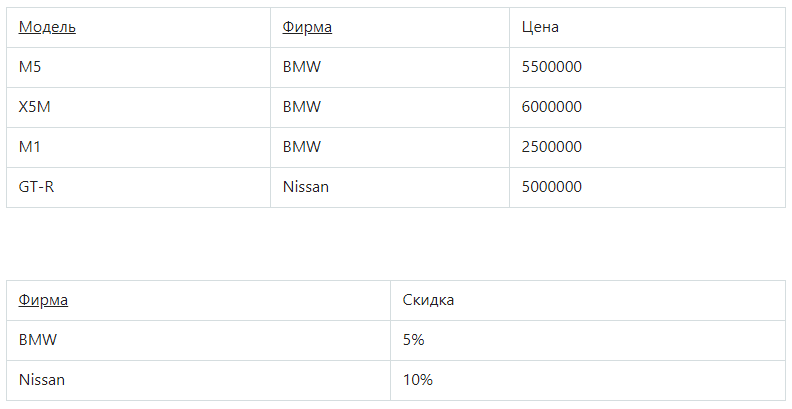
Третья нормальная форма (3НФ)
Таблица должна находиться во 2НФ, плюс любой столбец, который не является ключом, должен зависеть лишь от первичного ключа.
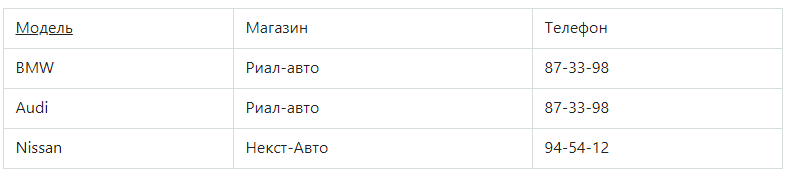
В таблице в отношении атрибут первичным ключом является «Модель». Так как собственные телефоны у автомашин отсутствуют, телефон зависит только от магазина.
В результате можно говорить о наличии в связях следующих функциональных зависимостей:
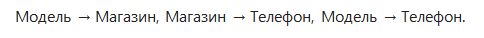
Зависимость «Модель → Телефон» — транзитивна, поэтому отношение не находится в 3НФ.
Разделив исходное отношение, можно получить 2 отношения, и они уже будут находиться в 3НФ:
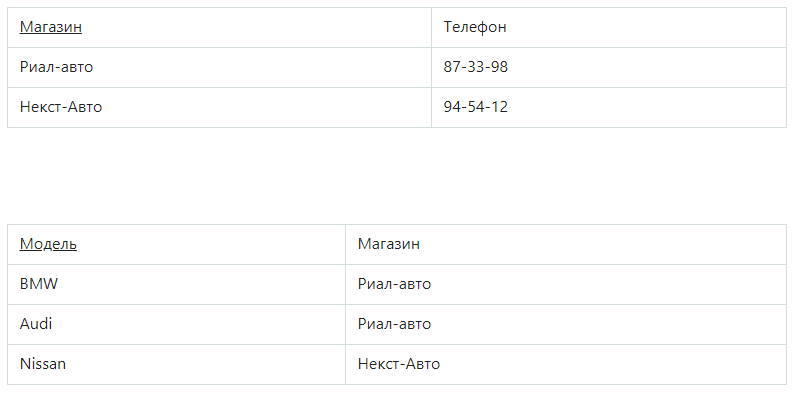
Остальные виды соотношений и правил, можно посмотреть по ссылкам ниже: — https://ru.wikipedia.org/wiki/Нормальная_форма; — https://habr.com/ru/post/254773/.
P. S. Очень надеемся, что теперь у вас сложилось представление о том, что такое нормализация базы данных. Если же вы хотите освоить работу с БД на профессиональном уровне, добро пожаловать на курсы OTUS!