SQL. Обобщенное табличное выражение и способы его использования
Обобщенное табличное выражение является общим инструментов для многих баз данных. Рассмотрим конкретнее, что же это такое и как с ним работать на примере средств MS SQL.
Common Table Expression (CTE) — результаты запроса, которые можно использовать множество раз в других запросах. То есть, запросом мы достаем данные, и они помещаются в пространство памяти, аналогично временному представлению, которое физически не сохраняется в виде объектов. Далее мы работаем с получившейся конструкцией как с таблицей, используя такие конструкции как select, update, insert и delete.
Выведем количество сотрудников, устроившихся на работу, в разбивке по годам:
WITH TABLE_CTE (FIO, ID_DEPART, BEGIN_YEAR) AS ( SELECT FIO, ID_DEPART, YEAR(DATE_BEGIN) as BEGIN_YEAR FROM EMPL ) SELECT count(FIO) as COUNT_SOTR, BEGIN_YEAR FROM TABLE_CTE group by BEGIN_YEAR
Еще обобщенное табличное выражение можно составить из результатов нескольких запросов. Последний результирующий запрос обращается к данным нижнего CTE(TABLE_CTE2), но может и к любому из них:
WITH TABLE_CTE1(FIO, YEAR_EMPL) AS ( SELECT FIO, YEAR(DATE_BEGIN) as YEAR_EMPL FROM EMPL ), TABLE_CTE2 (COUNT_FIO, YEAR_EMPL) AS ( SELECT count(FIO) as COUNT_FIO, YEAR_EMPL FROM TABLE_CTE1 group by YEAR_EMPL ) SELECT * FROM TABLE_CTE2
Основные способы использования:
- для улучшения читаемости запроса в случае сложных запросов (разительно уменьшают размер кода);
- в случаях, когда нужно много раз обращаться к одним и тем же таблицам/выборкам из таблиц;
- для создания представлений (VIEW) в части select;
- для написания рекурсивных запросов.
Отличия от вложенного запроса:
- вложенный запрос повторяется для каждой строки из нашей выборки, что повышает стоимость выполнения запроса.
Отличия от временной таблицы:
- заполнение временной таблицы при больших объемах создает нагрузку на диск;
- исполнение запросов с использованием временной таблицы увеличивает время их выполнения из-за места хранения данного типа таблиц (tempdb).
Мы познакомились с обобщенными табличными выражениями и убедились в том, что использование данного инструмента, совместно с остальными методами оптимизации запросов, помогает увеличить эффективность извлечения и обработки данных.
Есть ли разница в производительности между CTE, подзапросом, временной таблицей или табличной переменной?
Часто пользовался хранимыми процедурами, так как они выглядят более читабельными, чем множество вложенных подзапросов. Не рекурсивные CTE очень хорошо инкапсулируют наборы данных и тоже очень удобочитаемы.
Но есть ли конкретные обстоятельства, когда можно сказать, что тот или иной подход всегда будет работать производительней? Или надо постоянно выбирать на ощупь из разных подходов, чтобы найти наиболее производительное решение?
PS
Недавно узнал, что с точки зрения производительности, временные таблицы являются хорошим первым выбором, поскольку они имеют связанную с ними статистику.
Отслеживать
задан 19 апр 2020 в 12:58
51.6k 203 203 золотых знака 65 65 серебряных знаков 250 250 бронзовых знаков
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
SQL является декларативным языком, а не процедурным языком. То есть, создается запрос SQL для описания желаемых результатов, но при этом движку SQL не указывается, как ему выполнить запрос.
Как правило, желательно, чтобы оптимизатор в движке SQL нашёл сам лучший план выполнения запроса. На разработку движка SQL уходит очень много человеко-лет, поэтому положитесь на многолетний опыт разработчиков, который они накопили выполняя эту работу.
Несомненно, бывают ситуации, когда план запроса не является оптимальным. В этом случае надлежит использовать хинты запроса, реструктурировать запрос, обновлять статистику, использовать временные таблицы, добавлять индексы и т.д., чтобы повысить производительность.
Теоретически производительность CTE и подзапросов должна быть одинаковой, поскольку оба предоставляют одинаковую информацию оптимизатору запросов. Одно из отличий состоит в том, что CTE, использованный более одного раза, можно легко идентифицировать и выполнить один раз, то есть результаты могут быть сохранены и прочитаны несколько раз. К сожалению это не всегда так. SQL Server, например, не использует похоже преимущества этого базового метода оптимизации (назовём это общим устранением подзапроса).
Временные таблицы — это другое дело, потому что имеется больше информации о том, как должен выполняться запрос. Одно из основных отличий заключается в том, что оптимизатор может использовать статистику из временной таблицы для составления плана запроса. Это может привести к повышению производительности. Кроме того, если у вас есть сложный CTE (или подзапрос), который используется более одного раза, то сохранение его во временной таблице часто дает повышение производительности. Запрос выполняется только один раз.
И собственно ответ на вопрос заключается в том, что нужно попробовать различные варианты запроса, чтобы получить ожидаемую производительность, особенно для сложных запросов, которые выполняются на регулярной основе. Идеально было бы, чтобы оптимизатор SQL нашёл бы идеальный путь выполнения. Хотя это часто так и есть, но всегда остаётся возможность найти способ повысить производительность.
Common Table Expressions
Common Table Expressions (CTE) или обобщенное табличное выражение, впервые появилось в версии SQL Server 2005, и это простой способ разбить сложный запрос T-SQL на несколько запросов, что придаёт больше гибкости и управляемости. CTE во многом очень похожи на представления. В отличие от представления, которое можно создать один раз и потом использовать в других запросах, CTE привязан только к одному запросу. В Books Online есть несколько отличных примеров CTE, включая и рекурсивные CTE. Вместо того, чтобы продемонстрировать их устройство на своих примерах, в этой статье будут использоваться примеры из Books Online. Чтобы попробовать эти примеры у себя, используйте один из ранних образов базы данных AdventureWorks.
Начнем со следующего простого примера:
WITH DirReps(ManagerID, DirectReports) AS ( SELECT ManagerID, COUNT(*) FROM HumanResources.Employee AS e WHERE ManagerID IS NOT NULL GROUP BY ManagerID ) SELECT ManagerID, DirectReports FROM DirReps ORDER BY ManagerIDЭтот запрос идентичен более простому запросу:
SELECT ManagerID, COUNT(*) AS DirectReports FROM HumanResources.Employee AS e WHERE ManagerID IS NOT NULL GROUP BY ManagerID ORDER BY ManagerIDSQL Server фактически избавляется от CTE, и оба запроса создают один и тот же план исполнения:
|--Compute Scalar(DEFINE:([Expr1002]=CONVERT_IMPLICIT(int,[Expr1005],0))) |--Stream Aggregate(GROUP BY:([e].[ManagerID]) DEFINE:([Expr1005]=Count(*))) |--Index Seek(OBJECT:([HumanResources].[Employee].[IX_Employee_ManagerID] AS [e]), SEEK:([e].[ManagerID] IsNotNull) ORDERED FORWARD)
CTE бывают полезны, когда запрос включает несколько экземпляров одного и того же подзапроса. Например, запрос ниже вернёт количество заказов и дату последнего заказа по каждому сотруднику Adventure Works, а затем выдаст ту же информацию для менеджера каждого из сотрудников. Вместо повторения подзапроса, который возвращает количество заказов и дату последнего заказа, можно использовать CTE, что делает запрос более простым и понятным:
WITH Sales_CTE (SalesPersonID, NumberOfOrders, MaxDate) AS ( SELECT SalesPersonID, COUNT(*), MAX(OrderDate) FROM Sales.SalesOrderHeader GROUP BY SalesPersonID ) SELECT E.EmployeeID, OS.NumberOfOrders, OS.MaxDate, E.ManagerID, OM.NumberOfOrders, OM.MaxDate FROM HumanResources.Employee AS E JOIN Sales_CTE AS OS ON E.EmployeeID = OS.SalesPersonID LEFT OUTER JOIN Sales_CTE AS OM ON E.ManagerID = OM.SalesPersonID ORDER BY E.EmployeeIDЭтот запрос можно написать и без CTE:
SELECT E.EmployeeID, OS.NumberOfOrders, OS.MaxDate, E.ManagerID, OM.NumberOfOrders, OM.MaxDate FROM HumanResources.Employee AS E JOIN ( SELECT SalesPersonID, COUNT(*) AS NumberOfOrders, MAX(OrderDate) AS MaxDate FROM Sales.SalesOrderHeader GROUP BY SalesPersonID ) AS OS ON E.EmployeeID = OS.SalesPersonID LEFT OUTER JOIN ( SELECT SalesPersonID, COUNT(*) AS NumberOfOrders, MAX(OrderDate) AS MaxDate FROM Sales.SalesOrderHeader GROUP BY SalesPersonID ) AS OM ON E.ManagerID = OM.SalesPersonID ORDER BY E.EmployeeIDВ качестве альтернативы можно использовать представление, хотя для этого потребуется явно его создать (и потом удалить, если не нужно его хранить). Представления менее удобны и более затратны (DDL не бесплатен), чем CTE. Если вы создаёте и удаляете представления «на лету», вы должны быть осторожны, и не использовать имя, которое будет конфликтовать с другими сеансами, в которых также может в это время создаваться такое же представление.
CREATE VIEW Sales_View (SalesPersonID, NumberOfOrders, MaxDate) AS SELECT SalesPersonID, COUNT(*), MAX(OrderDate) FROM Sales.SalesOrderHeader GROUP BY SalesPersonID GO SELECT E.EmployeeID, OS.NumberOfOrders, OS.MaxDate, E.ManagerID, OM.NumberOfOrders, OM.MaxDate FROM HumanResources.Employee AS E JOIN Sales_View AS OS ON E.EmployeeID = OS.SalesPersonID LEFT OUTER JOIN Sales_View AS OM ON E.ManagerID = OM.SalesPersonID ORDER BY E.EmployeeID; GO DROP VIEW Sales_View GOВсе три варианта создают один и тот же план запроса:
|--Nested Loops(Left Outer Join, WHERE:([E].[ManagerID]=[Sales].[SalesOrderHeader].[SalesPersonID])) |--Sort(ORDER BY:([E].[EmployeeID] ASC)) | |--Nested Loops(Inner Join, OUTER REFERENCES:([Sales].[SalesOrderHeader].[SalesPersonID])) | |--Compute Scalar(DEFINE:([Expr1005]=CONVERT_IMPLICIT(int,[Expr1021],0))) | | |--Hash Match(Aggregate, HASH:([Sales].[SalesOrderHeader].[SalesPersonID]), RESIDUAL:(. ) DEFINE:([Expr1021]=COUNT(*), [Expr1006]=MAX([Sales].[SalesOrderHeader].[OrderDate]))) | | |--Clustered Index Scan(OBJECT:([Sales].[SalesOrderHeader].[PK_SalesOrderHeader_SalesOrderID])) | |--Clustered Index Seek(OBJECT:([HumanResources].[Employee].[PK_Employee_EmployeeID] AS [E]), SEEK:([E].[EmployeeID]=[Sales].[SalesOrderHeader].[SalesPersonID]) ORDERED FORWARD) |--Table Spool |--Compute Scalar(DEFINE:([Expr1010]=[Expr1010], [Expr1011]=[Expr1011])) |--Compute Scalar(DEFINE:([Expr1010]=CONVERT_IMPLICIT(int,[Expr1022],0))) |--Hash Match(Aggregate, HASH:([Sales].[SalesOrderHeader].[SalesPersonID]), RESIDUAL:(. ) DEFINE:([Expr1022]=COUNT(*), [Expr1011]=MAX([Sales].[SalesOrderHeader].[OrderDate]))) |--Clustered Index Scan(OBJECT:([Sales].[SalesOrderHeader].[PK_SalesOrderHeader_SalesOrderID]))
Обратите внимание, что в плане запроса результат CTE вычисляется дважды (по одному разу для каждой ссылки). Там есть два просмотра таблицы SalesOrderHeader и два хэш-агрегата. Даже при использовании CTE (или представления) SQL Server будет вычислять результат дважды. Не дайте ввести вас в заблуждение этому Table Spool. Эта буферизация просто кэширует результат CTE, чтобы избежать вычисления всего агрегата один раз для каждого сотрудника.
Можно заставить SQL Server вычислить результат CTE только один раз, явно материализовав его с помощью табличной переменной, временной таблицы или индексированного представления. Вот пример использования табличной переменной:
DECLARE @Sales_Data TABLE (SalesPersonID INT, NumberOfOrders INT, MaxDate DATETIME) INSERT @Sales_Data SELECT SalesPersonID, COUNT(*), MAX(OrderDate) FROM Sales.SalesOrderHeader GROUP BY SalesPersonID SELECT E.EmployeeID, OS.NumberOfOrders, OS.MaxDate, E.ManagerID, OM.NumberOfOrders, OM.MaxDate FROM HumanResources.Employee AS E JOIN @Sales_Data AS OS ON E.EmployeeID = OS.SalesPersonID LEFT OUTER JOIN @Sales_Data AS OM ON E.ManagerID = OM.SalesPersonID ORDER BY E.EmployeeIDЭтот вариант запроса состоит из двух операторов и, следовательно, имеет два плана. Первый план материализует результат CTE в табличную переменную, а второй план дважды её читает.
|--Table Insert(OBJECT:(@Sales_Data), SET:([SalesPersonID] = [Sales].[SalesOrderHeader].[SalesPersonID],[NumberOfOrders] = [Expr1007],[MaxDate] = [Expr1008])) |--Top(ROWCOUNT est 0) |--Compute Scalar(DEFINE:([Expr1007]=CONVERT_IMPLICIT(int,[Expr1012],0))) |--Hash Match(Aggregate, HASH:([Sales].[SalesOrderHeader].[SalesPersonID]), RESIDUAL:(. ) DEFINE:([Expr1012]=COUNT(*), [Expr1008]=MAX([Sales].[SalesOrderHeader].[OrderDate]))) |--Clustered Index Scan(OBJECT:([Sales].[SalesOrderHeader].[PK_SalesOrderHeader_SalesOrderID])) |--Nested Loops(Left Outer Join, WHERE:([E].[ManagerID]=[OM].[SalesPersonID])) |--Nested Loops(Inner Join, OUTER REFERENCES:([OS].[SalesPersonID])) | |--Sort(ORDER BY:([OS].[SalesPersonID] ASC)) | | |--Table Scan(OBJECT:(@Sales_Data AS [OS])) | |--Clustered Index Seek(OBJECT:([HumanResources].[Employee].[PK_Employee_EmployeeID] AS [E]), SEEK:([E].[EmployeeID]=[OS].[SalesPersonID]) ORDERED FORWARD) |--Table Scan(OBJECT:(@Sales_Data AS [OM]))
Явная материализация результата CTE (как и просмотра или подзапроса) не всегда обеспечивает лучшую производительность. Во-первых, мы должны учитывать стоимость создания и заполнения временной таблицы. Если стоимость самого CTE не слишком велика, может оказаться дешевле просто вычислить результат CTE нужное число раз. Во-вторых, бывает, что оптимизатор может найти более удачный план, в котором не понадобиться получать все строки CTE. Например, предположим, что мы хотим вычислить число заказов только по одному сотруднику:
DECLARE @EID INT SET @EID = 268; WITH Sales_CTE (SalesPersonID, NumberOfOrders, MaxDate) AS ( SELECT SalesPersonID, COUNT(*), MAX(OrderDate) FROM Sales.SalesOrderHeader GROUP BY SalesPersonID ) SELECT E.EmployeeID, OS.NumberOfOrders, OS.MaxDate, E.ManagerID, OM.NumberOfOrders, OM.MaxDate FROM HumanResources.Employee AS E JOIN Sales_CTE AS OS ON E.EmployeeID = OS.SalesPersonID LEFT OUTER JOIN Sales_CTE AS OM ON E.ManagerID = OM.SalesPersonID WHERE E.EmployeeID = @EIDЭтот запрос дает другой план:
|--Nested Loops(Left Outer Join, OUTER REFERENCES:([E].[ManagerID])) |--Nested Loops(Inner Join) | |--Clustered Index Seek(OBJECT:([HumanResources].[Employee].[PK_Employee_EmployeeID] AS [E]), SEEK:([E].[EmployeeID]=[@EID]) ORDERED FORWARD) | |--Compute Scalar(DEFINE:([Expr1005]=CONVERT_IMPLICIT(int,[Expr1021],0))) | |--Stream Aggregate(DEFINE:([Expr1021]=Count(*), [Expr1006]=MAX([Sales].[SalesOrderHeader].[OrderDate]))) | |--Clustered Index Scan(OBJECT:([Sales].[SalesOrderHeader].[PK_SalesOrderHeader_SalesOrderID]), WHERE:([Sales].[SalesOrderHeader].[SalesPersonID]=[@EID]) ) |--Compute Scalar(DEFINE:([Expr1010]=[Expr1010], [Expr1011]=[Expr1011])) |--Compute Scalar(DEFINE:([Expr1010]=CONVERT_IMPLICIT(int,[Expr1022],0))) |--Stream Aggregate(DEFINE:([Expr1022]=Count(*), [Expr1011]=MAX([Sales].[SalesOrderHeader].[OrderDate]))) |--Clustered Index Scan(OBJECT:([Sales].[SalesOrderHeader].[PK_SalesOrderHeader_SalesOrderID]), WHERE:([E].[ManagerID]=[Sales].[SalesOrderHeader].[SalesPersonID]) )
Исходный план получал число заказов и дату последнего заказа для всех сотрудников, а этот план получает это для одного сотрудника и его руководителя. Фильтрацию при сканировании кластерного индекса таблицы SalesOrderHeader обеспечивают предикаты WHERE. И этот план использует скалярные Stream Aggregate вместо Hash Match агрегатов в исходном плане. Наконец, в этом примере оптимизатор выбрал просмотр, но, если бы данных в таблице было больше, а предикаты были бы более избирательными, он выбрал бы поиск по индексу, что избавляет план от дорогого просмотра всей таблицы.
SQL-Ex blog

Как и во многих реляционных системах управления базами данных, MySQL предлагает разнообразные методы комбинирования данных в операторах языка манипуляции данными (DML). Вы можете соединять несколько таблиц в одном запросе или добавлять подзапросы, которые извлекают данные из других таблиц. Вы можете также обращаться к представлениям и временным таблицам из оператора наряду с постоянными таблицами.
MySQL предлагает также другой ценный инструмент для работы с данными — общие табличные выражения (CTE). CTE — это именованный результирующий набор, который вы определяете в предложении WITH. Предложение WITH связано с единственным оператором DML, но создается вне этого оператора. Однако только этот оператор может иметь доступ к результирующему набору.
В некоторых случаях вы можете включить CTE в оператор SELECT, который встроен в другой оператор, как в случае подзапроса или оператора DELETE…SELECT. Но даже тогда предложение WITH определяется вне этого оператора SELECT, и только этот оператор SELECT может иметь доступ к результирующему набору.
Можно думать о CTE как о неком представлении с очень ограниченной (одним оператором) областью видимости. Можно также представлять себе CTE как именованный подзапрос, который определен в предложении, отдельном от главного запроса. Однако CTE не является ни тем, ни другим, и в этой статье я объясняю, как работает CTE, и представлю ряд примеров, которые демонстрируют различные способы, которые вы можете использовать для получения данных.
Замечание: примеры используют таблицы и данные, которые создаются в последнем разделе статьи «Приложение: подготовка демонстрационных объектов и данных».
Начало работы с общими табличными выражениями
Общее табличное выражение определяется внутри предложения WITH. Это предложение предшествует основному оператору DML, который иногда называют оператором верхнего уровня. Кроме того, предложение может содержать одно или более определений CTE, как показано в следующем синтаксисе:
WITH [RECURSIVE]
имя_cte [(имя_столбца [, имя_столбца] . )] AS (оператор_select)
[, имя_cte [(имя_столбца [, имя_столбца] . )] AS (оператор_select)] .
оператор_верхнего_уровня;
Если предложение WITH содержит более одного CTE, вы должны разделять их запятыми и присвоить уникальное имя каждому CTE, хотя это применимо только в пределах предложения WITH. Например, два оператора SELECT могут включать CTE с одним и тем же именем, поскольку область видимости CTE ограничена связанным с ним оператором верхнего уровня.
За именем CTE следует одно или более необязательных имен столбцов, затем ключевое слово AS и, наконец, запрос SELECT в круглых скобках. Если вы указываете имена столбцов, их число должно соответствовать числу столбцов, возвращаемых запросом SELECT. Если имена столбцов не указываются, будут использоваться имена столбцов, возвращаемых запросом SELECT.
Общие табличные выражения обычно используются с операторами SELECT. Однако вы можете также использовать их с операторами UPDATE и DELETE, следуя вышеприведенному синтаксису. Кроме того, вы можете включать CTE с подзапросами при передаче их во внешние операторы. Вы можете также использовать CTE в операторах, которые поддерживают использование SELECT как части определения оператора. Например, вы можете добавить предложение WITH в оператор SELECT в операторе INSERT…SELECT или в операторе CREATE TABLE…SELECT.
В этой статье я сосредоточусь, главным образом, на создании CTE, которые используют оператор SELECT на верхнем уровне, поскольку это наиболее частое использование CTE. Такой подход является также хорошим способом начать изучение CTE, не рискуя данными. Затем вы можете применить изученные фундаментальные принципы к другим типам операторов, когда освоитесь с CTE.
Имея это в виду, давайте начнем с простого примера. Следующий оператор SELECT включает предложение WITH, которое определяет CTE с именем planes:
WITH planes AS
(SELECT plane, engine_count, max_weight
FROM airplanes WHERE engine_type = 'jet')
SELECT plane, max_weight FROM planes
ORDER BY max_weight DESC;
Запрос SELECT в CTE извлекает все самолеты из таблицы airplanes, для которых типом мотора (engine_type) является jet. Результирующий набор CTE составляют данные, возвращаемые запросом SELECT, они доступны для оператора SELECT верхнего уровня.
Оператор верхнего уровня извлекает данные непосредственно из CTE подобно тому, как оператор мог бы извлекать данные из представления. Основное различие состоит в том, что определение представления постоянно находится в базе данных и может использоваться всеми, кто имеет соответствующие привилегии. С другой стороны, CTE имеет очень ограниченную область видимости и доступно только в пределах оператора верхнего уровня.
В этом случае оператор SELECT верхнего уровня извлекает из CTE только столбцы plane и max_weight и упорядочивает результаты по столбцу max_weight в порядке убывания. На следующем рисунке показаны результаты, возвращаемые оператором.
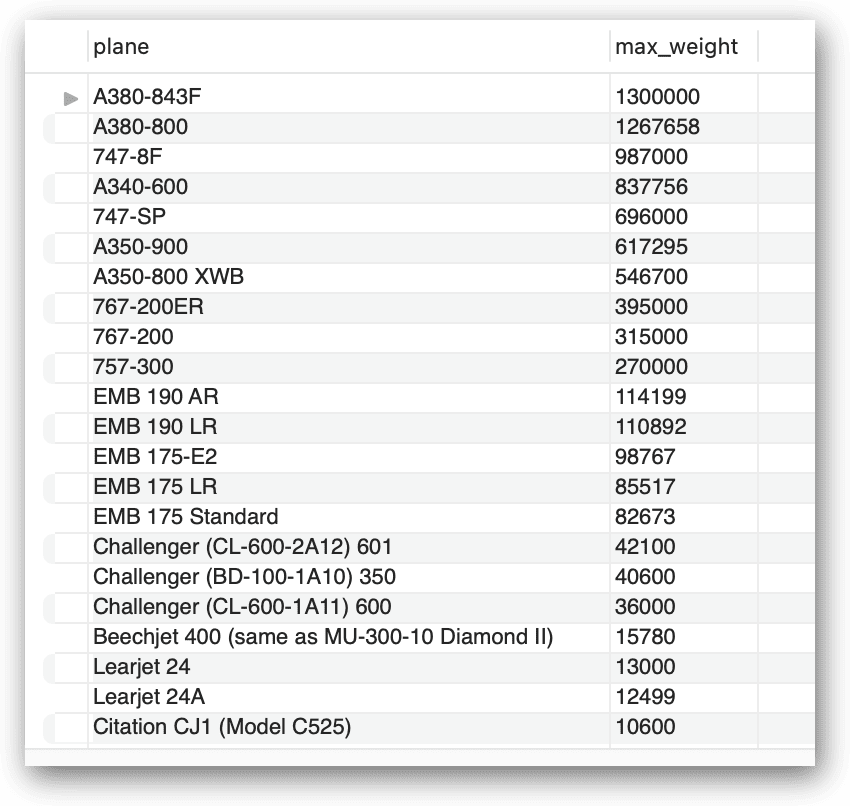
Конечно, вы можете легко достичь тех же результатов без использования CTE, непосредственно выполнив запрос к таблице airplanes:
SELECT plane, max_weight
FROM airplanes
WHERE engine_type = 'jet'
ORDER BY max_weight DESC;
Однако я хотел продемонстрировать основные компоненты работы с CTE и то, как вы можете получить доступ к CTE из оператора SELECT верхнего уровня. Как CTE, так и оператор верхнего уровня, несомненно могут быть значительно более сложными — обычно так и есть — но принцип остается тем же.
Работа с CTE в операторе SELECT верхнего уровня
Как упомянуто ранее, CTE — это, по сути, именованный результирующий набор. Когда вы обращаетесь к CTE из оператора верхнего уровня, данные возвращаются в табличном формате, подобно обращению к представлению, постоянной таблице, временной таблице или производной таблице (например, такой, которая производится подзапросом в предложении FROM оператора SELECT). Это означает, что вы можете работать с CTE в той же манере, как и с упомянутыми объектами других типов. Например, одним из обычных подходов к обращению с CTE в запросе верхнего уровня является соединение его с другой таблицей, как показано в следующем примере:
WITH mfcs AS
(SELECT manufacturer_id, manufacturer FROM manufacturers)
SELECT a.plane, m.manufacturer, a.max_weight
FROM airplanes a INNER JOIN mfcs m
ON a.manufacturer_id = m.manufacturer_id
WHERE a.engine_type = 'jet'
ORDER BY a.max_weight DESC;
Предложение WITH определяет единственное CTE с именем mfcs. Запрос SELECT в CTE возвращает значения manufacturer_id и manufacturer из таблицы manufacturers. Оператор SELECT верхнего уровня соединяет затем таблицу airplanes с CTE mfcs на основе столбца manufacturer_id. На следующем рисунке показаны результаты выполнения оператора:
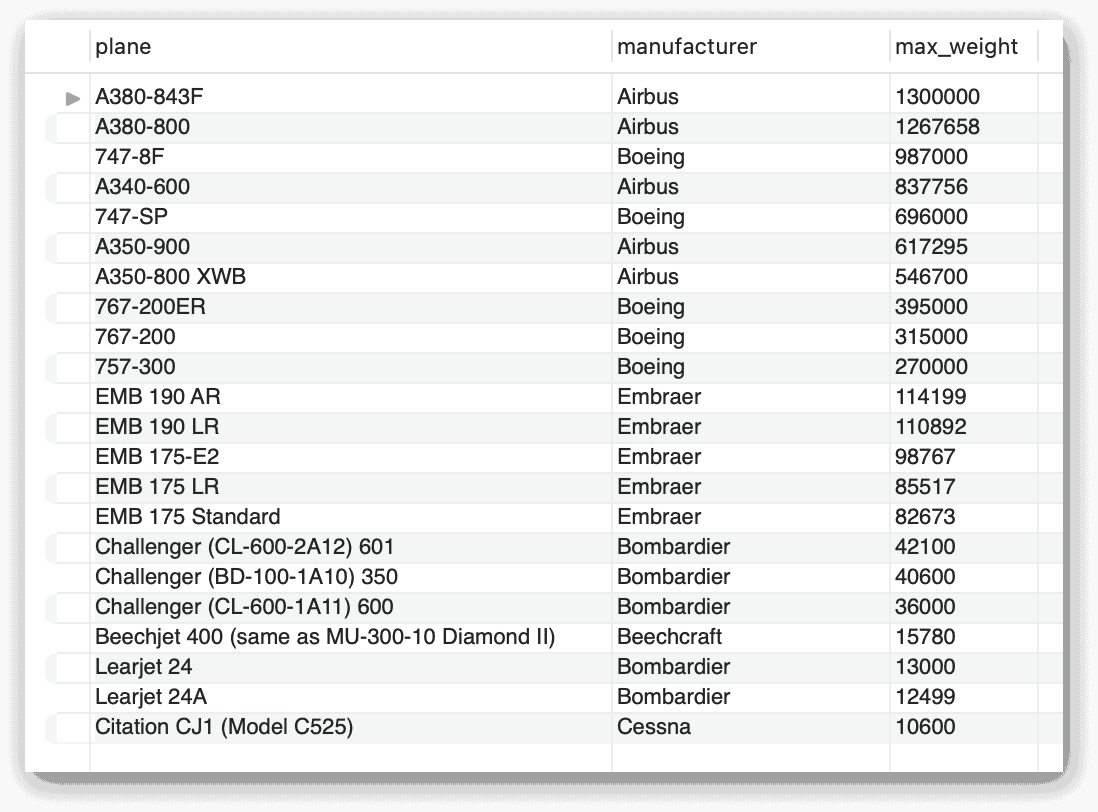
Как показывает этот пример, вы можете считать CTE подобным любой другой табличной структуре в вашем запросе верхнего уровня. Однако, как вы уже видели ранее, вы можете также переписать этот оператор без CTE, соединив таблицу airplanes непосредственно с таблицей manufacturers:
SELECT a.plane, m.manufacturer, a.max_weight
FROM airplanes a INNER JOIN manufacturers m
ON a.manufacturer_id = m.manufacturer_id
WHERE a.engine_type = 'jet'
ORDER BY a.max_weight DESC;
Поскольку здесь совсем немного данных, разница в производительности этих двух операторов незначительна, но это может быть не так для больших наборов данных. Однако, как это часто бывает с MySQL, трудно сказать, какой из подходов является лучшим, пока не выполнишь оба оператора на реальных данных. Даже в этом случае может не быть существенной разницы в производительности, тогда все может зависеть от предпочтений разработчика.
Как отмечалось ранее, MySQL часто поддерживает множество способов получения одних и тех же результатов, что демонстрировали предыдущие примеры. Общие табличные выражения иногда могут помочь упростить код и сделать его более читабельным, что является важным аргументом в их пользу, но производительность, как правило, должна быть главным соображением.
Сравнение различных подходов обычно требует тестирования на соответствующем наборе данных, в частности, потому что может быть сложно найти конкретные рекомендации при сравнении подходов. Например, мало кто из разработчиков смог бы утверждать, что вы всегда должны использовать CTE, а не внутренние соединения, при любых обстоятельствах, или наоборот.
Тем не менее, вы можете встретить менее жесткие рекомендации, которые, возможно, стоит рассмотреть, скажем, при сравнении CTE с подзапросами. Например, CTE часто считается лучшим выбором, если оператор SELECT включает несколько подзапросов, требующих одни и те же данные, как в следующем примере:
SELECT manufacturer_id, plane_id, plane, max_weight,
(SELECT ROUND(AVG(max_weight)) FROM airplanes a2
WHERE a.manufacturer_id = a2.manufacturer_id) AS avg_weight,
(max_weight - (SELECT ROUND(AVG(max_weight)) FROM airplanes a2
WHERE a.manufacturer_id = a2.manufacturer_id)) AS amt_over
FROM airplanes a
WHERE max_weight >
(SELECT ROUND(AVG(max_weight)) FROM airplanes a2
WHERE a.manufacturer_id = a2.manufacturer_id);
Если этот оператор кажется вам знакомым, это потому, что я взял его из моей предыдущей статьи, посвященной подзапросам. Как видно, оператор включает три одинаковых подзапроса, что может привести к избыточной обработке, в зависимости от того, как ядро базы данных предпочтет обрабатывать запрос. На следующем рисунке показаны результаты, возвращаемые оператором.
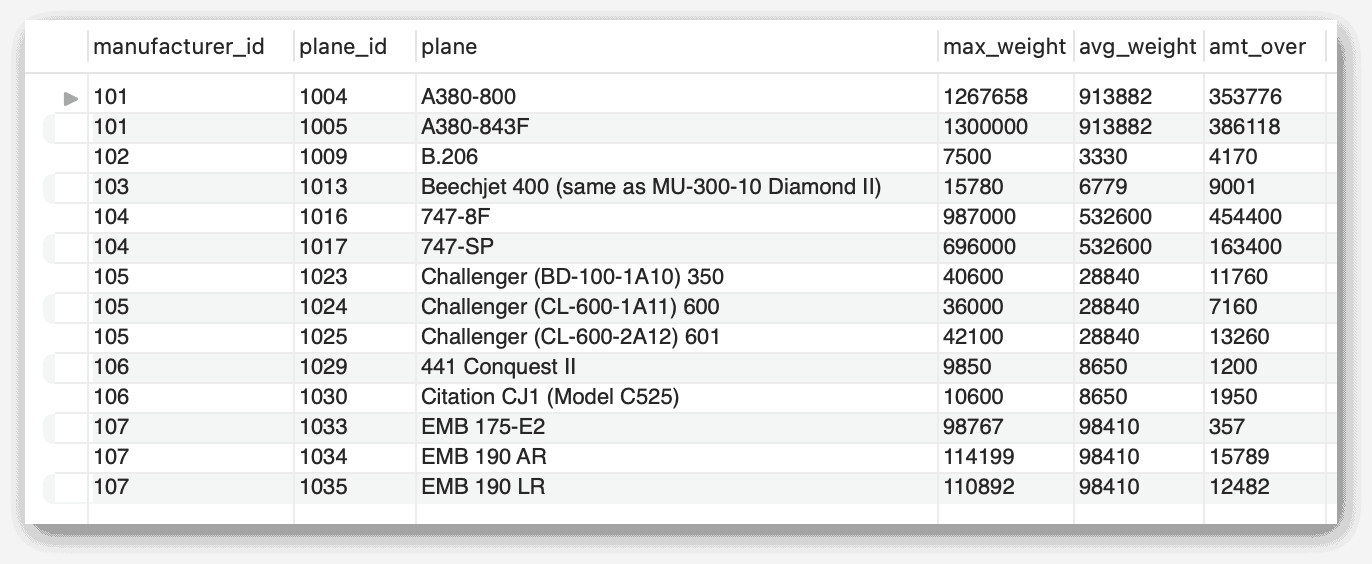
Вместо использования подзапросов вы можете достичь тех же результатов, определив CTE, которое получает среднее значение max_weight для каждого производителя. Затем в запросе верхнего уровня вы можете соединить таблицу airplanes с CTE по ИД производителя, как показано в следующем примере:
WITH mfc_weights (id, avg_weight) AS
(SELECT manufacturer_id, ROUND(AVG(max_weight))
FROM airplanes GROUP BY manufacturer_id)
SELECT a.manufacturer_id, a.plane_id, a.plane,
a.max_weight, m.avg_weight,
(a.max_weight - m.avg_weight) AS amt_over
FROM airplanes a INNER JOIN mfc_weights m
ON a.manufacturer_id = m.id
WHERE max_weight > m.avg_weight;
В этом случае CTE задает имена столбцов для их использования в результирующем наборе, поэтому значения manufacturer_id возвращаются как столбец id. Кроме того, CTE группирует данные в таблице manufacturers по значениям manufacturer_id и подсчитывает для каждого из них среднее значение avg_weight.
Затем запрос верхнего уровня соединяет таблицу airplanes с CTE и ограничивает результаты только теми самолетами, у которых значение max_weight больше среднего веса, возвращаемого CTE. Обратите внимание, что вместо подзапросов оператор теперь использует столбец avg_weight из CTE.
Повторю, что разница в производительности этих двух подходов незначительна, поскольку мы работаем с небольшим набором данных. Только выполнение этих операторов на более реалистичных данных может дать вам более правдивую картину разницы в производительности. Однако на мой вкус CTE делает код более читабельным, т.е. легче отслеживать логику оператора.
Определение нескольких CTE в одном предложении WITH
До сих пор в примерах этой статьи было только по одному CTE на предложение WITH, но вы можете определить несколько CTE и ссылаться на любое из них в операторе верхнего уровня. Просто следите, чтобы имена CTE различались и разделялись запятыми. Например, следующее предложение WITH определяет три CTE, на каждое из которых ссылается оператор SELECT верхнего уровня:
WITH
jets AS
(SELECT plane, engine_type, engine_count, max_weight
FROM airplanes WHERE engine_type = 'jet'),
turbos AS
(SELECT plane, engine_type, engine_count, max_weight
FROM airplanes WHERE engine_type = 'turboprop'),
pistons AS
(SELECT plane, engine_type, engine_count, max_weight
FROM airplanes WHERE engine_type = 'piston')
SELECT * FROM jets
UNION ALL
SELECT * FROM turbos
UNION ALL
SELECT * FROM pistons;
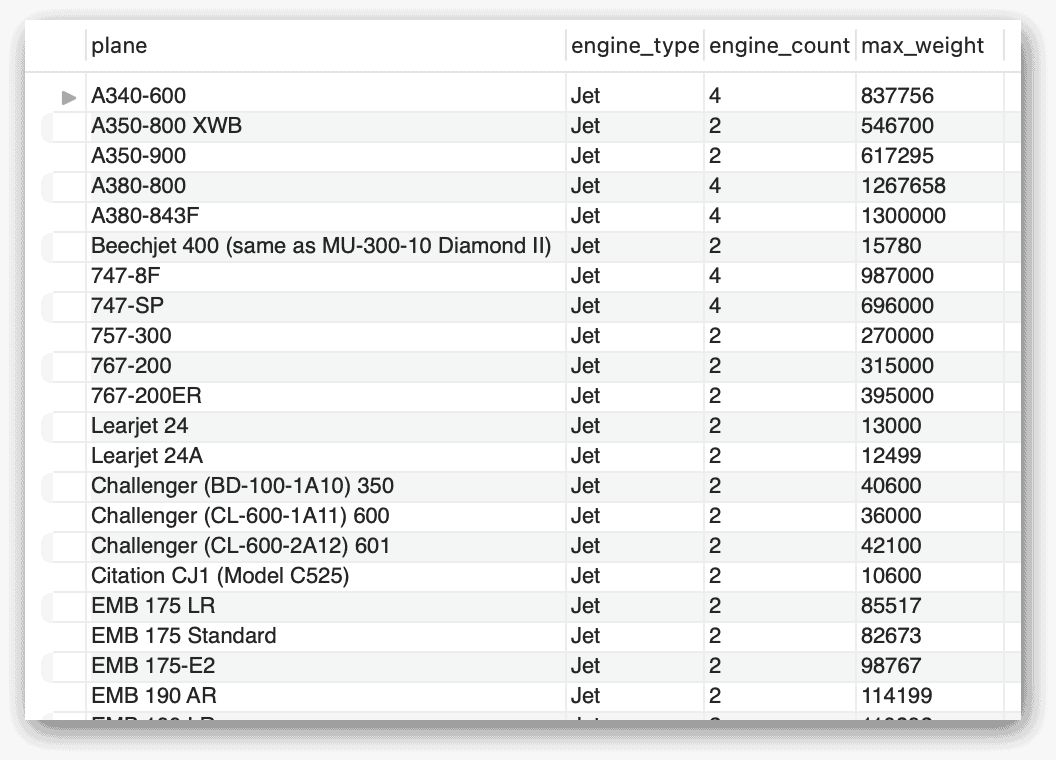
Три CTE похожи, они отличаются лишь тем, что выбирают данные на основе разных значений engine_type. Запрос SELECT верхнего уровня использует затем оператор UNION для их объединения. (Оператор UNION ALL собирает результаты нескольких операторов SELECT в единый результирующий набор.) Следующий рисунок показывает фрагмент результатов, возвращаемых этим оператором.
Это довольно простой пример, но он демонстрирует принцип определения нескольких CTE и ссылки на них в запросе верхнего уровня. В этом случае три CTE работают независимо друг от друга, но вы не всегда должны принимать этот подход. Например, предложение WITH в следующем примере также включает три CTE, но теперь второе CTE (mfc_avg) ссылается на первое CTE (mfcs), в то время как третье CTE (pl_avg) остается автономным:
WITH
mfcs (id, mfc) AS
(SELECT manufacturer_id, manufacturer FROM manufacturers),
mfc_avg (id, mfc, avg_parking) AS
(SELECT m.id, m.mfc, ROUND(AVG(a.parking_area))
FROM mfcs m INNER JOIN airplanes a
ON m.id = a.manufacturer_id
GROUP BY manufacturer_id),
pl_avg (avg_all) AS
(SELECT ROUND(AVG(parking_area)) FROM airplanes)
SELECT id, mfc, avg_parking
FROM mfc_avg m
WHERE avg_parking > (SELECT avg_all FROM pl_avg);
Как показывает данный пример, CTE может ссылаться на CTE, который находится до него. Однако это работает только в одном направлении; CTE не может ссылаться на CTE, который идет после него. В данном случае CTE mfc_avg соединяет таблицу airplanes с CTE mfcs и группирует данные по значению manufacturer_id. Затем запрос верхнего уровня извлекает данные из этого CTE, но возвращает только те строки, для которых значение avg_parking больше среднего, возвращаемого CTE pl_avg. На следующей картинке показаны результаты, возвращаемые этим оператором.
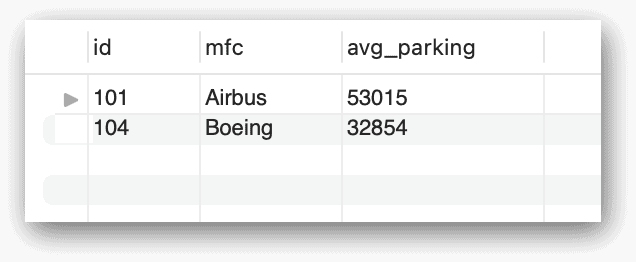
Стоит обратить внимание на то, что предложение WHERE запроса верхнего уровня включает подзапрос, который извлекает данные из CTE pl_avg. Это говорит не только о гибкости, присущей CTE, но и том, что CTE и подапросы не исключают друг друга.
Работа с рекурсивными CTE
Одним из наиболее полезных аспектов CTE является возможность выполнять рекурсивные запросы. Этот тип CTE — известный как рекурсивный CTE — ссылается на самого себя в пределах запроса CTE. Предложение WITH в рекурсивном CTE должно включать ключевое слово RECURSIVE, а запрос CTE должен включать две части, которые разделяются оператором UNION. Первая (нерекурсивная) часть заполняет начальную строку данными, а вторая (рекурсивная) часть фактически выполняет рекурсию на основе первой строки. Только рекурсивная часть может ссылаться на само CTE.
Чтобы понять, как это работает, рассмотрим следующий пример, который генерирует список четных чисел до 20 включтельно:
WITH RECURSIVE counter (val) AS
(SELECT 2
UNION ALL
SELECT val + 2 FROM counter WHERE val < 20)
SELECT * FROM counter;
CTE называется counter, и оно возвращает только один столбец val. Нерекурсвная часть запроса CTE устанавливает для первой строки значение 2, которое присваивается столбцу val. Рекурсивная часть запроса извлекает данные из CTE, но увеличивает значение столбца val на 2 на каждой итерации. Запрос продолжает инкрементровать столбец на 2, пока значение val меньше 20. Затем оператор SELECT верхнего уровня извлекает данные из CTE, возвращая результаты, показанные на следующем рисунке.
Замечание. Поскольку рекурсивный запрос говорит Категории: MySQL —>
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой