Кэширование функций в Python

В сегодняшней статье мы рассмотрим как оптимизировать время выполнения программы в Python c помощью операции кэширования. Мы рассмотрим данную операцию на примере рекурсивной функции в Python. Но сначала — пара слов о рекурсии. Рекурсия — это понятие в программировании, при котором функция вызывает сама себя один или несколько раз. Данные типы функций часто сталкиваются с проблемами скорости, из-за того, что функция постоянно вызывает сама себя. Операция рекурсии занимает достаточно много памяти из за постоянного повторения одних и тех же шагов. Кэшировнаие или Мемоизация (англ. memoization от англ. memory и англ. optimization) помогает этому процессу, сохраняя значения, которые уже были рассчитаны для последующего использования. Давайте сначала вспомним что такое рекурсивные функции. Давайте посмотрим несколько примеров!
Написание факториальной функции.
Факториалы — один из самых простых примеров рекурсии, и является результатом умножения всех чисел меньших на единицу чем данное:
def factorial(n):
# установите базовый случай!
if n return 1
else:
return factorial( n – 1 ) * n
print( factorial(5) ) # результат от умножения 5 * 4 * 3 * 2 * 1
Последовательность Фибоначчи. Последовательность Фибоначчи — одна из самых известных формул в математике. Это также одна из самых известных рекурсивных функций в программировании. Каждое число в последовательность — это сумма двух предыдущих чисел, таких, что fib(5) = fib(4) + fib(3). Вычислим ее для 20.
from datetime import datetime
import time
def fib(n):
if n return n
else:
return fib( n — 1 ) + fib( n — 2 )
9227465
0:00:17.647056 # время вычисления
Как видно на вычисление результата для числа 35, ушло целых 17 секунд.
По мере того, как растет количество передаваемых данных, растет структура и количество рекурсивных вызовов . Он экспоненциальный, что может значительно замедлить работу программы. Даже попытка выполнить fib(40) может занять пару минут, а fib(100) обычно не работает из-за проблем с максимальной глубиной рекурсии. Что приводит нас к нашей следующей теме о том, как решить эту проблему… кэширование .
Понимание мемоизации.
Когда вы заходите на веб-страницу в первый раз, вашему браузеру требуется некоторое время, чтобы загрузить изображения и файлы, необходимые странице. Когда вы во второй раз зайдете на ту же самую страницу, она обычно загружается намного быстрее. Это связано с тем, что ваш браузер использует технику, известную как «кэширование». В вычислительной технике мемоизация — это метод оптимизации, используемый в первую очередь для ускорения программы, сохраняя результаты ранее вызванных функций и возвращая сохраненный результат при попытке вычислить ту же последовательность. Это просто известно как кэширование.
Использование мемоизации.
Чтобы применить ее к последовательности Фибоначчи, мы должны понять, какой наилучший метод кэширования значений. В Python словари дают нам возможность для хранения значений на основе заданного ключа. Благодаря скорости и уникальной ключевой структуре словарей мы можем использовать их для хранения значение каждой последовательности Фибоначчи. Таким образом, как только одна последовательность, такая как fib(3), рассчитывается, его не нужно вычислять снова. Он просто сохраняется в кэше и извлекаются по мере необходимости. Давайте попробуем:
cache = < >
def fib(n):
if n in cache:
return cache[ n ]
result = 0
if n < = 1:
result = n
else:
result = fib( n – 1 ) + fib( n -2 )
cache[ n ] = result
return result
Использование @lru_cache
Теперь, когда мы знаем, как самостоятельно создать систему кэширования, давайте воспользуемся встроенными средствами Python. способ запоминания. Он известен как lru_cache.
from functools import lru_cache
@lru_cache( ) # встроенный инструмент кэширования
def fib(n):
if n return n
else:
return fib( n – 1 ) + fib( n – 2 )
Мы получим тот же результат, что и в предыдущем примере, но на этот раз с меньшим количеством строк. Таким образом, язык Python предоставляет возможность оптимизации кода библиотекой functools.

![]()
Создано 26.04.2022 09:31:08
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
- Кнопка:
Она выглядит вот так: - Текстовая ссылка:
Она выглядит вот так: Как создать свой сайт - BB-код ссылки для форумов (например, можете поставить её в подписи):
Комментарии ( 0 ):
Для добавления комментариев надо войти в систему.
Если Вы ещё не зарегистрированы на сайте, то сначала зарегистрируйтесь.
Copyright © 2010-2024 Русаков Михаил Юрьевич. Все права защищены.
Мне нужно ускорить рекурсию
Мне задали решить задачу. Я написал код, но он работает медленно. Мне нужно ускорить рекурсию. Если n будет равен даже 70 расчеты займет очень много времени. Помогите мне улучшить мой код. Максимальное n может быть 500!
def a(n): if n == 1: return 1 if n == 2: return 2 return 1 + a(n - a(a(n - 1))) Отслеживать
задан 29 окт 2020 в 19:01
130 15 15 бронзовых знаков
вы бы еще сказали что эта рекурсия делает, может можно было бы обойтись и без рекурсии
29 окт 2020 в 19:05
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
дело в том, что функция a(n) вызывается многократно, а значит рекурсий больше, чем нужно
можно вычислить a(n) однократно и дальше только использовать уже вычисленные значения
res = [0 for _ in range(1000)] def a(n): if res[n] == 0: if n > 2: res[n] = 1 + a(n - a(a(n - 1))) elif n == 1: res[n] = 1 elif n == 2: res[n] = 2 return res[n] print(a(900)) a(900) работает мгновенно, так что можно считать это оптимизацией 🙂
только учтите одну важную вещь, я не знаю как у питона, но при рекурсии у того же c++ вызовы запихиваются в стек и стек может просто переполниться
в моем примере при n = 1000 питон уже ругается
RecursionError: maximum recursion depth exceeded in comparison P.S.
в коде много if, поэтому лучше сделать ее покороче
res = [0, 1, 2] + [0 for _ in range(10)] def a(n): if res[n] == 0: res[n] = 1 + a(n - a(a(n - 1))) return res[n] print(a(10)) да и вообще зачем нам эти if?
res = [0, 1, 2] + [0 for _ in range(20)] def a(n): res[n] = res[n] or (1 + a(n - a(a(n - 1)))) return res[n] print(res) Мемоизация в Python для ускорения медленных функций

В данном руководстве мы рассмотрим использование функций lru_cache и cache для оптимизации расчетов в функциях Python.
Введение
Мемоизация — это техника оптимизации, которая ускоряет работу программ за счет кэширования результатов предыдущих вызовов функций. Это позволяет последующим вызовам повторно использовать кэшированные результаты, избегая трудоемкого пересчета.
Числа Фибоначчи
Числа Фибоначчи — это последовательность целых чисел, где каждое число является суммой двух предыдущих чисел, начиная с чисел 0 и 1.
Функция, которая вычисляет n-ое число Фибоначчи, часто реализуется рекурсивно.
Посмотрим на пример реализации
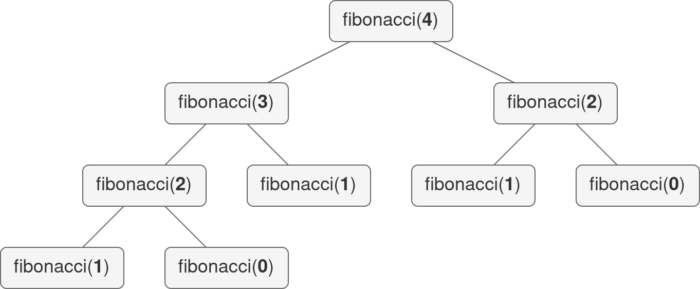
def fibonacci(n): if nВызовы функций fibonacci(4) можно визуализировать с помощью дерева рекурсии.
Обратите внимание, что функция вызывается с одним и тем же входом несколько раз. В частности, fibonacci(2) вычисляется с нуля дважды. По мере увеличения входных данных время работы растет экспоненциально. Это неоптимальный вариант, который можно значительно улучшить с помощью мемоизации.
Мемоизация в Python
В Python 3 запоминать функции невероятно просто. Модуль functools, входящий в стандартную библиотеку Python, предоставляет два полезных декоратора для мемоизации: lru_cache (новый в Python 3.2) и cache (новый в Python 3.9). Эти декораторы используют кэш с наименьшим последним использованием (LRU), который хранит элементы в порядке их использования, отбрасывая наименее недавно использованные элементы, чтобы освободить место для новых.
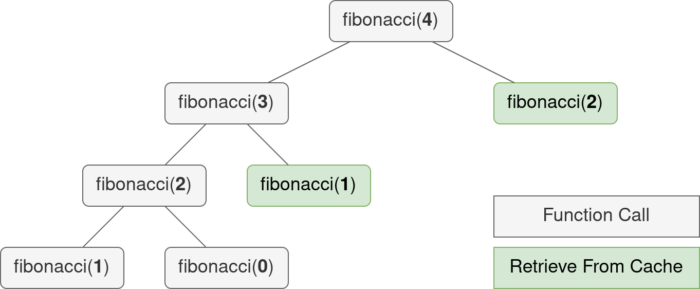
Чтобы избежать дорогостоящих повторных вызовов функций, fibonacci может быть обернут lru_cache, который сохраняет значения, которые уже были вычислены. Предельный размер lru_cache можно задать с помощью параметра maxsize, значение которого по умолчанию равно 128.
from functools import lru_cache @lru_cache(maxsize=64) def fibonacci(n): if nТеперь дерево рекурсии для fibonacci(4) не имеет узлов, которые встречаются более двух раз. Время работы теперь растет линейно, что гораздо быстрее экспоненциального роста.
Декоратор cache эквивалентен lru_cache(maxsize=None).
from functools import cache @cache def fibonacci(n): if nПоскольку cache не нуждается в отбрасывании последних использованных элементов, он одновременно меньше и быстрее, чем lru_cache с ограничением размера.
Заключение
Мемоизация повышает производительность за счет кэширования результатов вызовов функций и возврата кэшированного результата при повторном вызове функции с теми же входными данными.
Python 3 позволяет легко реализовать мемоизацию. Просто импортируйте lru_cache или cache из functools и примените декоратор.
Увеличиваем скорость работы Python до уровня C++ с Numba
Повышаем скорость работы Python с использованием библиотеки Numba и сравниваем с «плюсами» на примере простенького алгоритма.
В этой статье автор разобрался, как увеличить скорость работы Python, и продемонстрировал реализацию на реальном примере.
Прим. ред. Это перевод. Мнение редакции может не совпадать с мнением автора оригинала.
Тест базовой скорости
Для сравнения базовой скорости Python и C++ я буду использовать алгоритм генерации случайных простых чисел.
Блок-схема алгоритма генерации простых чисел
Реализация на Python
import math from time import per_counter def is_prime(num): if num == 2: return True; if numРеализация на C++
#include #include #include using namespace std; bool isPrime(int num) < if (num == 2) return true; if (num return true; > int main() < int N = 10000000; clock_t start,end; start = clock(); for (int i; i < N; i++) isPrime(i); end = clock(); coutРезультат
- Python: скорость выполнения 80,137 секунд;
- C++: скорость выполнения 3,174 секунды.
Комментарий
Как и ожидалось, программа на C++ выполняется в 25 раз быстрее, чем на Python. Ожидания подтвердились, потому что:
- Python — это динамически типизированный язык;
- GIL(Global Interpreter Lock) — не поддерживает параллельное программирование.
Благодаря тому, что Python это гибкий универсальный язык, наш результат можно улучшить. Один из лучших способов увеличить скорость Python — Numba.
Numba
Чтобы начать использовать Numba, просто установите её через консоль:
pip install numba Реализация на Python с использованием Numba
import math from time import per_counter from numba import njit, prange @njit(fastmath=True, cache=True) def is_prime(num): if num == 2: return True; if num Как вы могли заметить, в коде добавились декораторы njit:
- parallel=True — включает параллельное выполнение программы на процессоре;
- fastmath=True — разрешает использование небезопасных преобразований с плавающей точкой;
- cache=True — позволяет сократить время компиляции функции, если она уже была скомпилирована.
Итоговая скорость Python
- Python: скорость выполнения 1,401 секунды;
- C++: скорость выполнения 3,174 секунды.
Теперь вы знаете что Python способен обогнать C++. О других способах увеличения скорости работы Python читайте в статьях про пять проектов, которые помогают ускорить код на Python и про количество памяти, которое занимают разные типы данных в Python.