Как создать временную таблицу в sql запросе
В дополнение к табличным переменным можно определять временные таблицы. Такие таблицы могут быть полезны для хранения табличных данных внутри сложного комплексного скрипта.
Временные таблицы существуют на протяжении сессии базы данных. Если такая таблица создается в редакторе запросов (Query Editor) в SQL Server Management Studio, то таблица будет существовать пока открыт редактор запросов. Таким образом, к временной таблице можно обращаться из разных скриптов внутри редактора запросов.
После создания все временные таблицы сохраняются в таблице tempdb , которая имеется по умолчанию в MS SQL Server.
Если необходимо удалить таблицу до завершения сессии базы данных, то для этой таблицы следует выполнить команду DROP TABLE .
Название временной таблицы начинается со знака решетки #. Если используется один знак #, то создается локальная таблица, которая доступна в течение текущей сессии. Ели используются два знака ##, то создается глобальная временная таблица. В отличие от локальной глобальная временная таблица доступна всем открытым сессиям базы данных.
Например, создадим локальную временную таблицу:
CREATE TABLE #ProductSummary (ProdId INT IDENTITY, ProdName NVARCHAR(20), Price MONEY) INSERT INTO #ProductSummary VALUES ('Nokia 8', 18000), ('iPhone 8', 56000) SELECT * FROM #ProductSummary

И с этой таблицей можно работать в большей степени как и с обычной таблицей — получать данные, добавлять, изменять и удалять их. Только после закрытия редактора запросов эта таблица перестанет существовать.
Подобные таблицы удобны для каких-то временных промежуточных данных. Например, пусть у нас есть три таблицы:
CREATE TABLE Products ( Id INT IDENTITY PRIMARY KEY, ProductName NVARCHAR(30) NOT NULL, Manufacturer NVARCHAR(20) NOT NULL, ProductCount INT DEFAULT 0, Price MONEY NOT NULL ); CREATE TABLE Customers ( Id INT IDENTITY PRIMARY KEY, FirstName NVARCHAR(30) NOT NULL ); CREATE TABLE Orders ( Id INT IDENTITY PRIMARY KEY, ProductId INT NOT NULL REFERENCES Products(Id) ON DELETE CASCADE, CustomerId INT NOT NULL REFERENCES Customers(Id) ON DELETE CASCADE, CreatedAt DATE NOT NULL, ProductCount INT DEFAULT 1, Price MONEY NOT NULL );
Выведем во временную таблицу промежуточные данные из таблицы Orders:
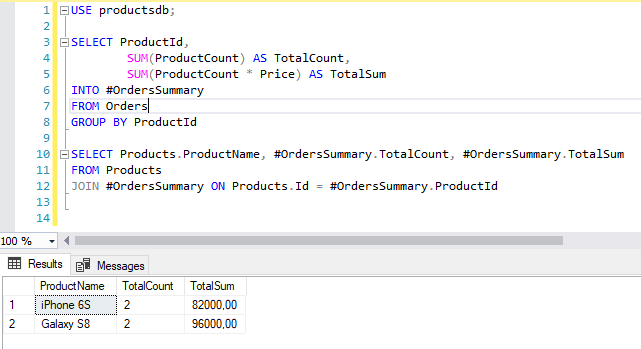
SELECT ProductId, SUM(ProductCount) AS TotalCount, SUM(ProductCount * Price) AS TotalSum INTO #OrdersSummary FROM Orders GROUP BY ProductId SELECT Products.ProductName, #OrdersSummary.TotalCount, #OrdersSummary.TotalSum FROM Products JOIN #OrdersSummary ON Products.Id = #OrdersSummary.ProductId
Здесь вначале извлекаются данные во временную таблицу #OrdersSummary. Причем так как данные в нее извлекаются с помощью выражения SELECT INTO, то предварительно таблицу не надо создавать. И эта таблица будет содержать id товара, общее количество проданного товара и на какую сумму был продан товар.
Затем эта таблица может использоваться в выражениях INNER JOIN.
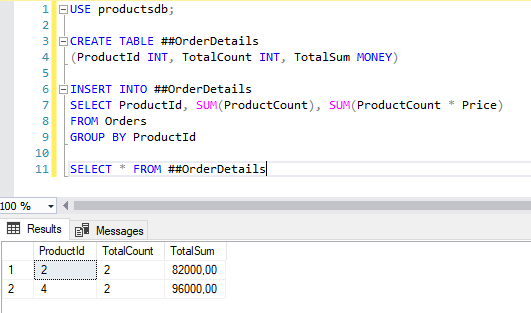
Подобным образом определяются глобальные временные таблицы, единственное, что их имя начинается с двух знаков ##:
CREATE TABLE ##OrderDetails (ProductId INT, TotalCount INT, TotalSum MONEY) INSERT INTO ##OrderDetails SELECT ProductId, SUM(ProductCount), SUM(ProductCount * Price) FROM Orders GROUP BY ProductId SELECT * FROM ##OrderDetails
Обобщенные табличные выражения
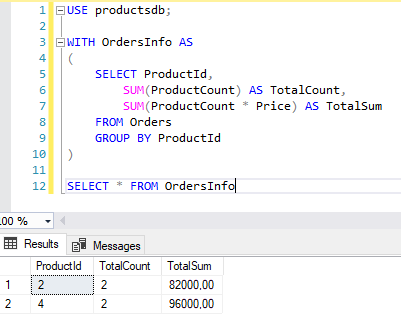
Кроме временных таблиц MS SQL Server позволяет создавать обобщенные табличные выражения (common table expression или CTE), которые являются производными от обычного запроса и в плане производительности являются более эффективным решением, чем временные. Обобщенное табличное выражение задается с помощью ключевого слова WITH :
WITH OrdersInfo AS ( SELECT ProductId, SUM(ProductCount) AS TotalCount, SUM(ProductCount * Price) AS TotalSum FROM Orders GROUP BY ProductId ) SELECT * FROM OrdersInfo -- здесь нормально SELECT * FROM OrdersInfo -- здесь ошибка SELECT * FROM OrdersInfo -- здесь ошибка
В отличие от временных таблиц табличные выполнения хранятся в оперативной памяти и существуют только во время первого выполнения запроса, который представляет это табличное выражение.
Временные таблицы выделенного пула SQL в Azure Synapse Analytics
В этой статье содержатся важные рекомендации по использованию временных таблиц и приводятся основные концепции временных таблиц уровня сеанса.
На основе сведений, содержащихся в этой статье, вы сможете разбить код на модули, чтобы улучшить его повторное использование и повысить удобство управления.
Что собой представляют временные таблицы
Временные таблицы удобны при обработке данных — особенно во время преобразования, где промежуточные результаты являются временными. В выделенном пуле SQL временные таблицы существуют на уровне сеанса.
Их можно просмотреть только в сеансе, в котором они были созданы. После закрытия сеанса они автоматически удаляются.
Временные таблицы позволяют оптимизировать производительность, так как их результаты записываются в локальное, а не удаленное хранилище.
Временные таблицы в выделенном пуле SQL
Временные таблицы в ресурсе выделенного пула SQL позволяют оптимизировать производительность, так как их результаты записываются в локальное, а не удаленное хранилище.
Создание временной таблицы
Для создания временной таблицы к имени таблицы добавляется префикс # . Пример:
CREATE TABLE #stats_ddl ( [schema_name] NVARCHAR(128) NOT NULL , [table_name] NVARCHAR(128) NOT NULL , [stats_name] NVARCHAR(128) NOT NULL , [stats_is_filtered] BIT NOT NULL , [seq_nmbr] BIGINT NOT NULL , [two_part_name] NVARCHAR(260) NOT NULL , [three_part_name] NVARCHAR(400) NOT NULL ) WITH ( DISTRIBUTION = HASH([seq_nmbr]) , HEAP ) Временные таблицы можно также создать с помощью CTAS точно таким же образом:
CREATE TABLE #stats_ddl WITH ( DISTRIBUTION = HASH([seq_nmbr]) , HEAP ) AS ( SELECT sm.[name] AS [schema_name] , tb.[name] AS [table_name] , st.[name] AS [stats_name] , st.[has_filter] AS [stats_is_filtered] , ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS [seq_nmbr] , QUOTENAME(sm.[name])+'.'+QUOTENAME(tb.[name]) AS [two_part_name] , QUOTENAME(DB_NAME())+'.'+QUOTENAME(sm.[name])+'.'+QUOTENAME(tb.[name]) AS [three_part_name] FROM sys.objects AS ob JOIN sys.stats AS st ON ob.[object_id] = st.[object_id] JOIN sys.stats_columns AS sc ON st.[stats_id] = sc.[stats_id] AND st.[object_id] = sc.[object_id] JOIN sys.columns AS co ON sc.[column_id] = co.[column_id] AND sc.[object_id] = co.[object_id] JOIN sys.tables AS tb ON co.[object_id] = tb.[object_id] JOIN sys.schemas AS sm ON tb.[schema_id] = sm.[schema_id] WHERE 1=1 AND st.[user_created] = 1 GROUP BY sm.[name] , tb.[name] , st.[name] , st.[filter_definition] , st.[has_filter] ) ; CTAS — мощная команда, которая особенно эффективна при использовании пространства журнала транзакций.
Удаление временных таблиц
При создании сеанса не должно быть ни одной временной таблицы.
Если вы вызываете одну и ту же хранимую процедуру, в которой создается временная таблица с тем же именем, чтобы обеспечить успешное выполнение инструкций CREATE TABLE , можно использовать простую проверку на наличие с помощью DROP , как показано в следующем примере.
IF OBJECT_ID('tempdb..#stats_ddl') IS NOT NULL BEGIN DROP TABLE #stats_ddl END Для согласованности кода целесообразно использовать этот шаблон как для обычных, так и для временных таблиц. Рекомендуется также удалить временные таблицы с помощью DROP TABLE , когда вы закончите работу с ними в коде.
При разработке хранимой процедуры команды удаления обычно помещаются вместе в конце процедуры, чтобы гарантировать удаление объектов.
DROP TABLE #stats_ddl Разбиение кода на модули
Так как временные таблицы можно просмотреть где угодно в сеансе пользователя, эту возможность можно использовать для модульной организации кода приложения.
Например, в представленной ниже хранимой процедуре создается DDL для обновления всей статистики в базе данных по имени статистического показателя.
CREATE PROCEDURE [dbo].[prc_sqldw_update_stats] ( @update_type tinyint -- 1 default 2 fullscan 3 sample 4 resample ,@sample_pct tinyint ) AS IF @update_type NOT IN (1,2,3,4) BEGIN; THROW 151000,'Invalid value for @update_type parameter. Valid range 1 (default), 2 (fullscan), 3 (sample) or 4 (resample).',1; END; IF @sample_pct IS NULL BEGIN; SET @sample_pct = 20; END; IF OBJECT_ID('tempdb..#stats_ddl') IS NOT NULL BEGIN DROP TABLE #stats_ddl END CREATE TABLE #stats_ddl WITH ( DISTRIBUTION = HASH([seq_nmbr]) ) AS ( SELECT sm.[name] AS [schema_name] , tb.[name] AS [table_name] , st.[name] AS [stats_name] , st.[has_filter] AS [stats_is_filtered] , ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS [seq_nmbr] , QUOTENAME(sm.[name])+'.'+QUOTENAME(tb.[name]) AS [two_part_name] , QUOTENAME(DB_NAME())+'.'+QUOTENAME(sm.[name])+'.'+QUOTENAME(tb.[name]) AS [three_part_name] FROM sys.objects AS ob JOIN sys.stats AS st ON ob.[object_id] = st.[object_id] JOIN sys.stats_columns AS sc ON st.[stats_id] = sc.[stats_id] AND st.[object_id] = sc.[object_id] JOIN sys.columns AS co ON sc.[column_id] = co.[column_id] AND sc.[object_id] = co.[object_id] JOIN sys.tables AS tb ON co.[object_id] = tb.[object_id] JOIN sys.schemas AS sm ON tb.[schema_id] = sm.[schema_id] WHERE 1=1 AND st.[user_created] = 1 GROUP BY sm.[name] , tb.[name] , st.[name] , st.[filter_definition] , st.[has_filter] ) SELECT CASE @update_type WHEN 1 THEN 'UPDATE STATISTICS '+[two_part_name]+'('+[stats_name]+');' WHEN 2 THEN 'UPDATE STATISTICS '+[two_part_name]+'('+[stats_name]+') WITH FULLSCAN;' WHEN 3 THEN 'UPDATE STATISTICS '+[two_part_name]+'('+[stats_name]+') WITH SAMPLE '+CAST(@sample_pct AS VARCHAR(20))+' PERCENT;' WHEN 4 THEN 'UPDATE STATISTICS '+[two_part_name]+'('+[stats_name]+') WITH RESAMPLE;' END AS [update_stats_ddl] , [seq_nmbr] FROM #stats_ddl ; GO На этом этапе единственное выполненное действие заключается в создании хранимой процедуры, в которой создается временная таблица #stats_ddl с использованием инструкций DDL.
В этой хранимой процедуре удаляется существующая таблица #stats_ddl . Это обеспечивает бесперебойную работу таблицы в случае ее повторного запуска на протяжении сеанса.
Но так как в конце хранимой процедуры нет команды DROP TABLE , после выполнения этой процедуры созданная таблица сохранится и ее можно будет читать вне хранимой процедуры.
В отличие от других баз данных SQL Server, в выделенном пуле SQL временную таблицу можно использовать вне процедуры, в которой она была создана. Временные таблицы выделенного пула SQL можно использовать в любом месте внутри сеанса. Это может улучшить модульность и управляемость кода, как показано в следующем примере.
EXEC [dbo].[prc_sqldw_update_stats] @update_type = 1, @sample_pct = NULL; DECLARE @i INT = 1 , @t INT = (SELECT COUNT(*) FROM #stats_ddl) , @s NVARCHAR(4000) = N'' WHILE @i Ограничения временной таблицы
В выделенном пуле SQL есть несколько ограничений, касающихся реализации временных таблиц. В настоящее время поддерживаются временные таблицы, которые можно просмотреть только в сеансе. Глобальные временные таблицы не поддерживаются.
Также для временных таблиц нельзя создавать представления. Временные таблицы можно создавать только с помощью хэша или циклического распределения. Распределение реплицированных временных таблиц не поддерживается.
Подзапросы и временные таблицы

Во всех рассмотренных ранее примерах значения столбцов сравниваются с выражением, константой или набором констант. Кроме таких возможностей сравнения язык Transact-SQL позволяет сравнивать значения столбца с результатом другой инструкции SELECT. Такая конструкция, где предложение WHERE инструкции SELECT содержит одну или больше вложенных инструкций SELECT, называется . Первая инструкция SELECT подзапроса называется внешним запросом (outer query), а внутренняя инструкция (или инструкции) SELECT, используемая в сравнении, называется вложенным запросом (inner query). Первым выполняется вложенный запрос, а его результат передается внешнему запросу. Вложенные запросы также могут содержать инструкции INSERT, UPDATE и DELETE.
Существует два типа подзапросов: независимые и связанные. В независимых подзапросах вложенный запрос логически выполняется ровно один раз. Связанный запрос отличается от независимого тем, что его значение зависит от переменной, получаемой от внешнего запроса. Таким образом, вложенный запрос связанного подзапроса выполняется каждый раз, когда система получает новую строку от внешнего запроса. В этом разделе приводится несколько примеров независимых подзапросов. Связанные подзапросы рассматриваются далее в следующей статье совместно с оператором соединения JOIN.
Независимый подзапрос может применяться со следующими операторами:
- операторами сравнения;
- оператором IN;
- операторами ANY и ALL.
Подзапросы и операторы сравнения
Использование оператора равенства (=) в независимом подзапросе показано в примере ниже:
USE SampleDb; SELECT FirstName, LastName FROM Employee WHERE DepartamentNumber = (SELECT Number FROM Department WHERE DepartmentName = 'Исследования');В этом примере происходит выборка имен и фамилий сотрудников отдела 'Исследования'. Результат выполнения этого запроса:

В примере выше сначала выполняется вложенный запрос, возвращая номер отдела разработки (d1). После выполнения внутреннего запроса подзапрос в примере можно представить следующим эквивалентным запросом:
USE SampleDb; SELECT FirstName, LastName FROM Employee WHERE DepartamentNumber = 'd1';В подзапросах можно также использовать любые другие операторы сравнения, при условии, что вложенный запрос возвращает в результате одну строку. Это очевидно, поскольку невозможно сравнить конкретные значения столбца, возвращаемые внешним запросом, с набором значений, возвращаемым вложенным запросом. В последующем разделе рассматривается, как можно решить проблему, когда результат вложенного запроса содержит набор значений.
Подзапросы и оператор IN
Оператор IN позволяет определить набор выражений (или констант), которые затем можно использовать в поисковом запросе. Этот оператор можно использовать в подзапросах при таких же обстоятельствах, т.е. когда вложенный запрос возвращает набор значений. Использование оператора IN в подзапросе показано в примере ниже:
USE SampleDb; SELECT FirstName, LastName FROM Employee WHERE DepartamentNumber IN (SELECT Number FROM Department WHERE DepartmentName = 'Исследования')Этот запрос аналогичен предыдущему. Каждый вложенный запрос может содержать свои вложенные запросы. Подзапросы такого типа называются подзапросами с многоуровневым вложением. Максимальная глубина вложения (т.е. количество вложенных запросов) зависит от объема памяти, которым компонент Database Engine располагает для каждой инструкции SELECT. В случае подзапросов с многоуровневым вложением система сначала выполняет самый глубокий вложенный запрос и возвращает полученный результат запросу следующего высшего уровня, который в свою очередь возвращает свой результат запросу следующего уровня над ним и т.д. Конечный результат выдается запросом самого высшего уровня.
Запрос с несколькими уровнями вложенности показан в примере ниже:
USE SampleDb; SELECT FirstName, LastName FROM Employee WHERE ID IN (SELECT EmpId FROM Works_on WHERE ProjectNumber IN (SELECT Number FROM Project WHERE ProjectName = 'Apollo') )В этом примере происходит выборка фамилий всех сотрудников, работающих над проектом Apollo. Самый глубокий вложенный запрос выбирает из таблицы ProjectNumber значение p1. Этот результат передается следующему вышестоящему запросу, который обрабатывает столбец ProjectNumber в таблице Works_on. Результатом этого запроса является набор табельных номеров сотрудников: (10102, 29346, 9031, 28559). Наконец, самый внешний запрос выводит фамилии сотрудников, чьи номера были выбраны предыдущим запросом.
Подзапросы и операторы ANY и ALL
Операторы ANY и ALL всегда используются в комбинации с одним из операторов сравнения. Оба оператора имеют одинаковый синтаксис:
Параметр operator обозначает оператор сравнения, а параметр query - вложенный запрос. Оператор ANY возвращает значение true (истина), если результат соответствующего вложенного запроса содержит хотя бы одну строку, удовлетворяющую условию сравнения. Ключевое слово SOME является синонимом ANY. Использование оператора ANY показано в примере ниже:
USE SampleDb; SELECT DISTINCT EmpId, ProjectNumber, Job FROM Works_on WHERE EnterDate > ANY (SELECT EnterDate FROM Works_on);В этом примере происходит выборка табельного номера, номера проекта и названия должности для сотрудников, которые не затратили большую часть своего времени при работе над одним из проектов. Каждое значение столбца EnterDate сравнивается со всеми другими значениями этого же столбца. Для всех дат этого столбца, за исключением самой ранней, сравнение возвращает значение true (истина), по крайней мере, один раз. Строка с самой ранней датой не попадает в результирующий набор, поскольку сравнение ее даты со всеми другими датами никогда не возвращает значение true (истина). Иными словами, выражение "EnterDate > ANY (SELECT EnterDate FROM Works_on)" возвращает значение true, если в таблице Works_on имеется любое количество строк (одна или больше), для которых значение столбца EnterDate меньше, чем значение EnterDate текущей строки. Этому условию удовлетворяют все значения столбца EnterDate, за исключением наиболее раннего.
Оператор ALL возвращает значение true, если вложенный запрос возвращает все значения, обрабатываемого им столбца.
Настоятельно рекомендуется избегать использования операторов ANY и ALL. Любой запрос с применением этих операторов можно сформулировать лучшим образом посредством функции EXISTS, которая рассматривается далее в следующей статье. Кроме этого, семантическое значение оператора ANY можно легко принять за семантическое значение оператора ALL и наоборот.
Временные таблицы
- это объект базы данных, который хранится и управляется системой базы данных на временной основе. Временные таблицы могут быть локальными или глобальными. Локальные временные таблицы представлены физически, т.е. они хранятся в системной базе данных tempdb. Имена временных таблиц начинаются с префикса #, например #table_name.
Временная таблица принадлежит создавшему ее сеансу, и видима только этому сеансу. Временная таблица удаляется по завершению создавшего ее сеанса. (Также локальная временная таблица, определенная в хранимой процедуре, удаляется по завершению выполнения этой процедуры.)
Глобальные временные таблицы видимы любому пользователю и любому соединению и удаляются после отключения от сервера базы данных всех обращающихся к ним пользователей. В отличие от локальных временных таблиц имена глобальных временных таблиц начинаются с префикса ##. В примере ниже показано создание временной таблицы, называющейся project_temp, используя две разные инструкции языка Transact-SQL:
USE SampleDb; CREATE TABLE #project_temp ( Number NCHAR(4) NOT NULL, Name NCHAR(25) NOT NULL ); -- Аналог предыдущей инструкции со вставкой -- данных во временную таблицу из существующей -- таблицы Project SELECT Number, ProjectName INTO #project_temp FROM Project;Два этих подхода похожи в том, что в обоих создается локальная временная таблица #project_temp. При этом таблица, созданная инструкцией CREATE TABLE, остается пустой, а созданная инструкцией SELECT заполняется данными из таблицы Project.
Создание и использование временных таблиц в SQL запросах
Создание литеральной таблицы в SQL возможно при помощи ключевого слова VALUES , которое используется для непосредственного ввода данных. Такой подход, известный как конструктор таблицы значений, позволяет мгновенно формировать таблицу прямо в SQL-запросе. Пример создания таблицы с полями id и name выглядит так:
Скопировать код
SELECT * FROM (VALUES (1, 'Алиса'), (2, 'Боб'), (3, 'Чарли')) AS tbl(id, name);Таким образом, мы создаём временную таблицу tbl , которая содержит определённые строки.
За поверхностным пользованием литеральными таблицами скрываются различные нюансы и приёмы, способные ускорить и упростить создание SQL-запросов.
Эффективное использование литеральных таблиц
Литеральные таблицы, определённые прямо в SQL-запросе, могут существенно уменьшить время операций с временными таблицами, избегая таких команд как CREATE TEMPORARY TABLE и ввод данных. Этот подход позволяет одновременно формировать структуру и содержимое таблицы, делая выполнение запросов гораздо оперативнее.
MySQL и T-SQL: Похожие, но отличающиеся
- В MySQL и его форке MariaDB, начиная с версии 8.0.19 и 10.3.3 соответственно, были внесены упрощения в синтаксис для определения литеральных таблиц. Так, с использованием ключевого слова WITH стало возможным создание Общих Табличных Выражений (CTE), которые функционируют как временные таблицы: