XMLHttpRequest
XMLHttpRequest – это встроенный в браузер объект, который даёт возможность делать HTTP-запросы к серверу без перезагрузки страницы.
Несмотря на наличие слова «XML» в названии, XMLHttpRequest может работать с любыми данными, а не только с XML. Мы можем загружать/скачивать файлы, отслеживать прогресс и многое другое.
На сегодняшний день не обязательно использовать XMLHttpRequest , так как существует другой, более современный метод fetch .
В современной веб-разработке XMLHttpRequest используется по трём причинам:
- По историческим причинам: существует много кода, использующего XMLHttpRequest , который нужно поддерживать.
- Необходимость поддерживать старые браузеры и нежелание использовать полифилы (например, чтобы уменьшить количество кода).
- Потребность в функциональности, которую fetch пока что не может предоставить, к примеру, отслеживание прогресса отправки на сервер.
Что-то из этого списка звучит знакомо? Если да, тогда вперёд, приятного знакомства с XMLHttpRequest . Если же нет, возможно, имеет смысл изучать сразу Fetch.
Основы
XMLHttpRequest имеет два режима работы: синхронный и асинхронный.
Сначала рассмотрим асинхронный, так как в большинстве случаев используется именно он.
Чтобы сделать запрос, нам нужно выполнить три шага:
let xhr = new XMLHttpRequest(); // у конструктора нет аргументовxhr.open(method, URL, [async, user, password])- method – HTTP-метод. Обычно это «GET» или «POST» .
- URL – URL, куда отправляется запрос: строка, может быть и объект URL.
- async – если указать false , тогда запрос будет выполнен синхронно, это мы рассмотрим чуть позже.
- user , password – логин и пароль для базовой HTTP-авторизации (если требуется).
Заметим, что вызов open , вопреки своему названию, не открывает соединение. Он лишь конфигурирует запрос, но непосредственно отсылается запрос только лишь после вызова send .
xhr.send([body])- load – происходит, когда получен какой-либо ответ, включая ответы с HTTP-ошибкой, например 404.
- error – когда запрос не может быть выполнен, например, нет соединения или невалидный URL.
- progress – происходит периодически во время загрузки ответа, сообщает о прогрессе.
xhr.onload = function() < alert(`Загружено: $$`); >; xhr.onerror = function() < // происходит, только когда запрос совсем не получилось выполнить alert(`Ошибка соединения`); >; xhr.onprogress = function(event) < // запускается периодически // event.loaded - количество загруженных байт // event.lengthComputable = равно true, если сервер присылает заголовок Content-Length // event.total - количество байт всего (только если lengthComputable равно true) alert(`Загружено $из $`); >;Вот полный пример. Код ниже загружает /article/xmlhttprequest/example/load с сервера и сообщает о прогрессе:
// 1. Создаём новый XMLHttpRequest-объект let xhr = new XMLHttpRequest(); // 2. Настраиваем его: GET-запрос по URL /article/. /load xhr.open('GET', '/article/xmlhttprequest/example/load'); // 3. Отсылаем запрос xhr.send(); // 4. Этот код сработает после того, как мы получим ответ сервера xhr.onload = function() < if (xhr.status != 200) < // анализируем HTTP-статус ответа, если статус не 200, то произошла ошибка alert(`Ошибка $: $`); // Например, 404: Not Found > else < // если всё прошло гладко, выводим результат alert(`Готово, получили $байт`); // response -- это ответ сервера > >; xhr.onprogress = function(event) < if (event.lengthComputable) < alert(`Получено $из $ байт`); > else < alert(`Получено $байт`); // если в ответе нет заголовка Content-Length > >; xhr.onerror = function() < alert("Запрос не удался"); >;После ответа сервера мы можем получить результат запроса в следующих свойствах xhr :
status Код состояния HTTP (число): 200 , 404 , 403 и так далее, может быть 0 в случае, если ошибка не связана с HTTP. statusText Сообщение о состоянии ответа HTTP (строка): обычно OK для 200 , Not Found для 404 , Forbidden для 403 , и так далее. response (в старом коде может встречаться как responseText ) Тело ответа сервера.
Мы можем также указать таймаут – промежуток времени, который мы готовы ждать ответ:
xhr.timeout = 10000; // таймаут указывается в миллисекундах, т.е. 10 секундЕсли запрос не успевает выполниться в установленное время, то он прерывается, и происходит событие timeout .
URL с параметрами
Чтобы добавить к URL параметры, вида ?name=value , и корректно закодировать их, можно использовать объект URL:
let url = new URL('https://google.com/search'); url.searchParams.set('q', 'test me!'); // параметр 'q' закодирован xhr.open('GET', url); // https://google.com/search?q=test+me%21Тип ответа
Мы можем использовать свойство xhr.responseType , чтобы указать ожидаемый тип ответа:
- «» (по умолчанию) – строка,
- «text» – строка,
- «arraybuffer» – ArrayBuffer (для бинарных данных, смотрите в ArrayBuffer, бинарные массивы),
- «blob» – Blob (для бинарных данных, смотрите в Blob),
- «document» – XML-документ (может использовать XPath и другие XML-методы),
- «json» – JSON (парсится автоматически).
К примеру, давайте получим ответ в формате JSON:
let xhr = new XMLHttpRequest(); xhr.open('GET', '/article/xmlhttprequest/example/json'); xhr.responseType = 'json'; xhr.send(); // тело ответа xhr.onload = function() < let responseObj = xhr.response; alert(responseObj.message); // Привет, мир! >;На заметку:
В старом коде вы можете встретить свойства xhr.responseText и даже xhr.responseXML .
Они существуют по историческим причинам, раньше с их помощью получали строки или XML-документы. Сегодня следует устанавливать желаемый тип объекта в xhr.responseType и получать xhr.response , как показано выше.
Состояния запроса
У XMLHttpRequest есть состояния, которые меняются по мере выполнения запроса. Текущее состояние можно посмотреть в свойстве xhr.readyState .
Список всех состояний, указанных в спецификации:
UNSENT = 0; // исходное состояние OPENED = 1; // вызван метод open HEADERS_RECEIVED = 2; // получены заголовки ответа LOADING = 3; // ответ в процессе передачи (данные частично получены) DONE = 4; // запрос завершёнСостояния объекта XMLHttpRequest меняются в таком порядке: 0 → 1 → 2 → 3 → … → 3 → 4 . Состояние 3 повторяется каждый раз, когда получена часть данных.
Изменения в состоянии объекта запроса генерируют событие readystatechange :
xhr.onreadystatechange = function() < if (xhr.readyState == 3) < // загрузка >if (xhr.readyState == 4) < // запрос завершён >>;Вы можете наткнуться на обработчики события readystatechange в очень старом коде, так уж сложилось исторически, когда-то не было событий load и других. Сегодня из-за существования событий load/error/progress можно сказать, что событие readystatechange «морально устарело».
Отмена запроса
Если мы передумали делать запрос, можно отменить его вызовом xhr.abort() :
xhr.abort(); // завершить запросПри этом генерируется событие abort , а xhr.status устанавливается в 0 .
Синхронные запросы
Если в методе open третий параметр async установлен на false , запрос выполняется синхронно.
Другими словами, выполнение JavaScript останавливается на send() и возобновляется после получения ответа. Так ведут себя, например, функции alert или prompt .
Вот переписанный пример с параметром async , равным false :
let xhr = new XMLHttpRequest(); xhr.open('GET', '/article/xmlhttprequest/hello.txt', false); try < xhr.send(); if (xhr.status != 200) < alert(`Ошибка $: $`); > else < alert(xhr.response); >> catch(err) < // для отлова ошибок используем конструкцию try. catch вместо onerror alert("Запрос не удался"); >Выглядит, может быть, и неплохо, но синхронные запросы используются редко, так как они блокируют выполнение JavaScript до тех пор, пока загрузка не завершена. В некоторых браузерах нельзя прокручивать страницу, пока идёт синхронный запрос. Ну а если же синхронный запрос по какой-то причине выполняется слишком долго, браузер предложит закрыть «зависшую» страницу.
Многие продвинутые возможности XMLHttpRequest , такие как выполнение запроса на другой домен или установка таймаута, недоступны для синхронных запросов. Также, как вы могли заметить, ни о какой индикации прогресса речь тут не идёт.
Из-за всего этого синхронные запросы используют очень редко. Мы более не будем рассматривать их.
HTTP-заголовки
XMLHttpRequest умеет как указывать свои заголовки в запросе, так и читать присланные в ответ.
Для работы с HTTP-заголовками есть 3 метода:
Устанавливает заголовок запроса с именем name и значением value .
xhr.setRequestHeader('Content-Type', 'application/json');Ограничения на заголовки
Некоторые заголовки управляются исключительно браузером, например Referer или Host , а также ряд других. Полный список тут.
XMLHttpRequest не разрешено изменять их ради безопасности пользователей и для обеспечения корректности HTTP-запроса.
Поставленный заголовок нельзя снять
Ещё одной особенностью XMLHttpRequest является то, что отменить setRequestHeader невозможно.
Если заголовок определён, то его нельзя снять. Повторные вызовы лишь добавляют информацию к заголовку, а не перезаписывают его.
xhr.setRequestHeader('X-Auth', '123'); xhr.setRequestHeader('X-Auth', '456'); // заголовок получится такой: // X-Auth: 123, 456getResponseHeader(name)
Возвращает значение заголовка ответа name (кроме Set-Cookie и Set-Cookie2 ).
xhr.getResponseHeader('Content-Type')getAllResponseHeaders()
Возвращает все заголовки ответа, кроме Set-Cookie и Set-Cookie2 .
Заголовки возвращаются в виде единой строки, например:
Cache-Control: max-age=31536000 Content-Length: 4260 Content-Type: image/png Date: Sat, 08 Sep 2012 16:53:16 GMTМежду заголовками всегда стоит перевод строки в два символа «\r\n» (независимо от ОС), так что мы можем легко разделить их на отдельные заголовки. Значение заголовка всегда отделено двоеточием с пробелом «: » . Этот формат задан стандартом.
Таким образом, если хочется получить объект с парами заголовок-значение, нам нужно задействовать немного JS.
Вот так (предполагается, что если два заголовка имеют одинаковое имя, то последний перезаписывает предыдущий):
let headers = xhr .getAllResponseHeaders() .split('\r\n') .reduce((result, current) => < let [name, value] = current.split(': '); result[name] = value; return result; >, <>); // headers['Content-Type'] = 'image/png'POST, FormData
Чтобы сделать POST-запрос, мы можем использовать встроенный объект FormData.
let formData = new FormData([form]); // создаём объект, по желанию берём данные формы formData.append(name, value); // добавляем полеМы создаём объект, при желании указываем, из какой формы form взять данные, затем, если нужно, с помощью метода append добавляем дополнительные поля, после чего:
- xhr.open(‘POST’, . ) – создаём POST -запрос.
- xhr.send(formData) – отсылаем форму серверу.
Обычно форма отсылается в кодировке multipart/form-data .
Если нам больше нравится формат JSON, то используем JSON.stringify и отправляем данные как строку.
Важно не забыть поставить соответствующий заголовок Content-Type: application/json , многие серверные фреймворки автоматически декодируют JSON при его наличии:
let xhr = new XMLHttpRequest(); let json = JSON.stringify(< name: "Вася", surname: "Петров" >); xhr.open("POST", '/submit') xhr.setRequestHeader('Content-type', 'application/json; charset=utf-8'); xhr.send(json);Метод .send(body) весьма всеяден. Он может отправить практически что угодно в body , включая объекты типа Blob и BufferSource .
Прогресс отправки
Событие progress срабатывает только на стадии загрузки ответа с сервера.
А именно: если мы отправляем что-то через POST -запрос, XMLHttpRequest сперва отправит наши данные (тело запроса) на сервер, а потом загрузит ответ сервера. И событие progress будет срабатывать только во время загрузки ответа.
Если мы отправляем что-то большое, то нас гораздо больше интересует прогресс отправки данных на сервер. Но xhr.onprogress тут не поможет.
Существует другой объект, без методов, только для отслеживания событий отправки: xhr.upload .
Он генерирует события, похожие на события xhr , но только во время отправки данных на сервер:
- loadstart – начало загрузки данных.
- progress – генерируется периодически во время отправки на сервер.
- abort – загрузка прервана.
- error – ошибка, не связанная с HTTP.
- load – загрузка успешно завершена.
- timeout – вышло время, отведённое на загрузку (при установленном свойстве timeout ).
- loadend – загрузка завершена, вне зависимости от того, как – успешно или нет.
Примеры обработчиков для этих событий:
xhr.upload.onprogress = function(event) < alert(`Отправлено $из $ байт`); >; xhr.upload.onload = function() < alert(`Данные успешно отправлены.`); >; xhr.upload.onerror = function() < alert(`Произошла ошибка во время отправки: $`); >;Пример из реальной жизни: загрузка файла на сервер с индикацией прогресса:
Запросы на другой источник
XMLHttpRequest может осуществлять запросы на другие сайты, используя ту же политику CORS, что и fetch.
Точно так же, как и при работе с fetch , по умолчанию на другой источник не отсылаются куки и заголовки HTTP-авторизации. Чтобы это изменить, установите xhr.withCredentials в true :
let xhr = new XMLHttpRequest(); xhr.withCredentials = true; xhr.open('POST', 'http://anywhere.com/request'); . Детали по заголовкам, которые при этом необходимы, смотрите в главе fetch.
Итого
Типичный код GET-запроса с использованием XMLHttpRequest :
let xhr = new XMLHttpRequest(); xhr.open('GET', '/my/url'); xhr.send(); xhr.onload = function() < if (xhr.status != 200) < // HTTP ошибка? // обработаем ошибку alert( 'Ошибка: ' + xhr.status); return; >// получим ответ из xhr.response >; xhr.onprogress = function(event) < // выведем прогресс alert(`Загружено $из $`); >; xhr.onerror = function() < // обработаем ошибку, не связанную с HTTP (например, нет соединения) >;Событий на самом деле больше, в современной спецификации они все перечислены в том порядке, в каком генерируются во время запроса:
- loadstart – начало запроса.
- progress – прибыла часть данных ответа, тело ответа полностью на данный момент можно получить из свойства responseText .
- abort – запрос был прерван вызовом xhr.abort() .
- error – произошла ошибка соединения, например неправильное доменное имя. Событие не генерируется для HTTP-ошибок как, например, 404.
- load – запрос успешно завершён.
- timeout – запрос был отменён по причине истечения отведённого для него времени (происходит, только если был установлен таймаут).
- loadend – срабатывает после load , error , timeout или abort .
События error , abort , timeout и load взаимно исключают друг друга – может произойти только одно из них.
Наиболее часто используют события завершения загрузки ( load ), ошибки загрузки ( error ), или мы можем использовать единый обработчик loadend для всего и смотреть в свойствах объекта запроса xhr детали произошедшего.
Также мы уже видели событие: readystatechange . Исторически оно появилось одним из первых, даже раньше, чем была составлена спецификация. Сегодня нет необходимости использовать его, так как оно может быть заменено современными событиями, но на него можно часто наткнуться в старом коде.
Если же нам нужно следить именно за процессом отправки данных на сервер, тогда можно использовать те же события, но для объекта xhr.upload .
Как скачать потоковое видео с любого сайта на компьютер?
Я не любитель скачивать какие-либо видеоролики из Интернета, когда их можно без проблем посмотреть в режиме «онлайн» на сайте-источнике. Но в этот Новый год мне все же пришлось прибегнуть к скачиванию именного видеопоздравления Деда Мороза от отечественного сервиса Mail.ru.
Видео для детей получились красочными и интересными, за что отдельное спасибо сервису, но вся проблема в том, что там, где я хотел показать это видео – не было доступа к глобальной сети Интернет. Вариант здесь был только один – это скачивание необходимого медиафайла.
Поскольку видеосообщение генерировалось на основе тех данных, что я указывал о ребенке, то скачать полное видео не представлялось возможным, так как на сайте куча маленьких частичек воспроизводились последовательно, создавая при этом картину цельного видеосообщения.
Что такое потоковое видео (Streaming Video)?
Если отбросить все умные термины, то можно сказать, что потоковое видео – это технология, которая позволяет смотреть то или иное видео в режиме реального времени (онлайн). Сюда можно отнести различные онлайн трансляции телепередач и кино, стримы (stream) на YouTube и прочих подобных сервисах.
Как скачать потоковое видео с любого сайта на свой компьютер?
Видеопоздравление, которое мне было необходимо скачать, тоже является потоковым, и как я упоминал ранее – простая его загрузка не была возможной.
Поискав некоторую информацию в Интернете на этот счет, я узнал, что плеер «VLC Media Player» для Windows как раз позволяет в несколько шагов скачивать подобные видео. Мне, к сожалению, этот способ не подошел, так как по итогу я получил искаженное (зависающее) видео. Поэтому я не буду делать акцент на этой программе как о способе скачки потокового видео на ваш компьютер, а расскажу о другом рабочем способе, который помог решить мне поставленную задачу.
Представляю вашему вниманию «Xtreme Download Manager» – программу, позволяющую увеличить скорость загрузки видеофайлов и умеющую сохранять потоковые видео с популярных сервисов на вашем компьютере, в числе которых YouTube, Vimeo, Dailymotion, Google Video и десятки тысяч других.
Xtreme Download Manager легко встраивается во все известные браузеры, что, в свою очередь, дает возможность простого скачивания понравившегося видео.
На сколько мне известно, программа помимо операционной системы Windows поддерживает Linux обоих разрядностей и Mac OS X.
Внушающая доверие программа, согласитесь? За что ее автору тоже отдельное спасибо.
Чтобы начать скачивать потоковые видео на ваш компьютер, сделайте следующее.
1. Скачайте программу и установите ее на ваш компьютер. Официальные релизы для всех поддерживаемых операционных систем находятся здесь. В конце статьи я приложил актуальную (на момент написания статьи) версию программы для Windows.
2. После успешной установки запустите программу. В верхнем меню нажмите «Инструменты», а в выпадающем списке выберите «Отслеживание в браузере».
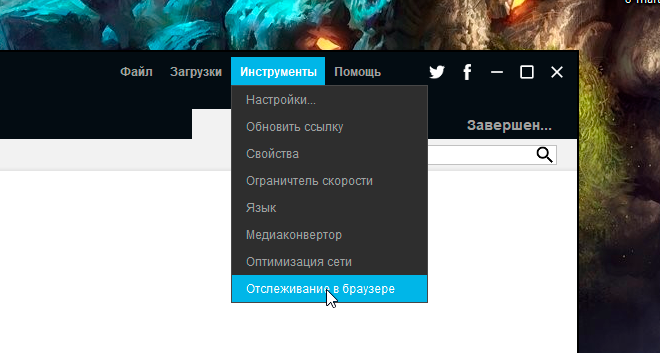
Если у вас интерфейс программы на английском языке – то переключить его на русский вы можете через верхнее меню «Tools», пункт «Language».
После изменения языка обязательно перезапустите программу для применения изменений.
3. В появившемся окне вы ищете тот браузер, которым пользуетесь чаще всего, и жмете под ним кнопку «Установить дополнение».

После чего переходите по предложенной ссылке и просто устанавливаете дополнение для своего браузера.
В программе обязательно должна быть включена функция «Отслеживание в браузере»:

А дальше все просто – идете на любой видеохостинг, включаете видео, и на экране вашего компьютера (сбоку) появится кнопка «DOWNLOAD VIDEO».

Нажмите на нее, и перед вами откроется список всех файлов, которые доступны для скачивания.

Жмете на название, в появившемся окне вводите желаемое название файла и то место, куда оно сохранится.

Вот и все. Просто, не так ли?
Приложение позволяет скачивать не только видеофайлы, но и музыку, например, из социальной сети «ВКонтакте».
Download streaming video with many xhr parts separated for audio and video
I want to download a streaming video. When I go to Chrome DevTools -> Network instead of a link to the mp4 video I find many links like . hd4b.mp4/fragment-1-v1.m4s and other like . a1.m4s for audio. There are also an initial . hd4b.mp4/init-v1.mp4 and . init-a1.mp4 . There are too many fragments to copy them manually. So I need to know how to filter all the .m4s fragment links for the .mp4 file I want. There is an answer here that gives me all the links in Networks and after executing it I can paste the links to a file but it gets links that are not part of the .mp4 I want too. It doesn’t really matter but it would be nice to get only the links for the . hd4b.mp4 . How do I get the video links in one file and the audio ones in another? What should I do with the init links? Add them to the list? Now that I think, the way to get the links would be going to the end of the video and getting the last number and generating the links modifying the number from one to last. How would I generate the links? Answer. And then when I have the links here’s the way to download them but how do I merge the video parts? And when I have the audio and video how do I combine them in the final mp4?
asked May 29, 2019 at 9:48
user428047 user428047
Use youtube-dl when possible.
May 29, 2019 at 10:14
I’ve tried it, but it doesn’t seem to work.
– user428047
May 29, 2019 at 10:15
1 Answer 1
youtube-dl
Try using the latest version to download the video. If you can’t follow the steps.
First get the links
In Chrome go to DevTools -> Networks and find the first and last fragment links. If the links are sequential generate the links like:
seq -f ". hd4b.mp4/fragment-%g-v1.m4s" 10 > video-links.txt Where %g will go from 1 to 10. If there is an init link it has to be included at the beginning of the video-links.txt file.
If the links are not sequential copy them like this:
- Switch devtools to detached window (click devtools settings icon, click «dock side» undock icon). Next time you can simply press Ctrl — Shift — D .
- Invoke devtools-for-devtools by pressing Ctrl — Shift — i
- Run this code to copy the URLs of all/filtered requests to clipboard: copy(UI.panels.network._networkLogView._dataGrid._rootNode._flatNodes.map(n => n._request._url).join(‘\n’))
You can save the code as a Snippet in Sources panel and run it via right-click or Ctrl-Enter:
var URLs = UI.panels.network._networkLogView._dataGrid._rootNode._flatNodes.map(n => n._request._url); copy(URLs.join('\n')); URLs; // displays it in the console as an expandable array After executing the script the links are in the clipboard so paste them to a file.
Download video and audio
wget -i "video-links.txt" -O "video.mp4" -B ". hd4b.mp4/" Use the -B option with the base of the URL.
Download the audio following the same steps as for the video.
Merge video and audio
ffmpeg -i video.mp4 -i audio.wav \ -c:v copy -c:a aac -strict experimental output.mp4 Скачать видео с YouTube через DevTools?
Всем доброго времени суток! Подскажите, пожалуйста, как можно скачать YouTube видео через DevTools?
Я знаю, что можно скачать через различные сайты или yt-dlp. Но как это сделать без них?
В консоли только xhr файлы идут. Может, оттуда можно как-то ссылку на видео вытащить?
Update:
У меня получилось вытащить видео из консоли как мне и нужно было.
1) Выбираете нужный вам ролик.
2) Перед запуском ролика выбираете нужное вам качество.
3) Открываете Developer tools — Network и запускаете ролик на несколько секунд
4) Во вкладке Network после начала проигрывания видео появятся файлы с именем videoplayback?expire=.
Какие-то из этих файлов с именем videoplayback?expire=. относятся к видео файлу, а какие-то к звуку.
5) Открываете ссылку на файл в новой вкладке, там будет окошко с видео, но там ничего нет.
6) В адресной строке в самом конце ищите &range=какое-то число-какое-то число. Например, &range=1680777-2230746 и записываете его так &range=0-99999999999999999. Девяток или других цифр может быть сколько угодно. Как я понял, это размер файла в байтах. Так у вас загрузится файл полностью.
7) Обновляете страницу с измененным &range и скачиваете полученный файл. Это будет либо видео, либо аудио.
Чтобы не проверять все ссылки подряд, чтобы определить видеофайл это или аудиофайл, справа в разделе headers в content-type указан формат.
Ну а потом склеиваете через ffmpeg или что вам нравится видео+аудио.
Может, кому-то это пригодится.
А так, пользуйтесь yt-dlp)
P.S. Я не программист.
- Вопрос задан более двух лет назад
- 1773 просмотра
2 комментария
Средний 2 комментария