Основы работы с Pandas: Series и DataFrames

Одним из наиболее популярных инструментов для системного анализа данных является Pandas. Давайте рассмотрим, какими особенностями обладает данная библиотека, для чего и как используется. Предложенная информацию будет полезна не только новичкам, но и опытным специалистам.
Описание
Pandas – программная библиотека, написанная на Python. Она используется для обработки и анализа данных. Работа здесь строится поверх library NumPy.
Если говорить простыми словами, Pandas – это как Excel, но мощнее. Здесь программист сможет работать с данными, объемом в тысячи и даже миллионы строк. Pandas предоставляет высокопроизводительные структуры информации, а также инструменты для их анализа.
Ключевые функции
Pandas широко используется в разработке. Она обеспечивает простоту в рамках среды Python. Используется для:
- сбора и очистки данных;
- задач, связанных с анализом информации;
- моделирования данных без переключения на специфичные для стартовой обработки языки (пример – Octave или R).
Библиотека предназначается для очистки, а также первичной оценки данных по общим показателям. Пример – среднее значение, квантили и так далее.
Pandas – это не статистический пакет, но его наборы информации применяются в виде входных в большинстве модулей анализа данных, а также при машинном обучении.
Для чего нужен проект
Pandas – это ключевая библиотека Питона, необходимая для работы с электронными материалами. Активно используется специалистами по BigDatas. Часто применяется для следующих задач:
- Аналитика. Инструмент позволяет подготовить datas к дальнейшему использованию. Он удаляет или заполняет пропуски, проводит сортировку или вносит необходимые изменения. Обычно большую часть соответствующих процессов удается автоматизировать через изучаемый проект.
- Data Science. Используется для подготовки и первичного анализа имеющихся сведений. Это необходимо для машинного/глубокого обучения.
- Статистика. В изучаемом проекте поддерживаются ключевые статистические методы. Они позволяют работать с информацией в электронном виде максимально эффективно и быстро. Пример – расчет средних значений.
Инструмент используется не только для обработки информации, но и для ее визуализации. Легко осваивается как опытными разработчиками, так и новичками.
Историческая справка
Рассматриваемый инструмент начал разрабатываться Уэсом Маккини, работающем в AQR Capital Management, в 2008 году. Он смог убедить работодателя перед увольнением разрешить опубликовать исходный код библиотеки. Так она получила открытость и свободную лицензию.
Позже, в 2012 году, к поддержке и совершенствованию продукта присоединился еще один сотрудник AQR – Чан Шэ. Он стал вторым главным разработчиком проекта. Примерно в этот момент Пандас стала набирать популярность в Python. Теперь соответствующий инструмент активно совершенствуется и дорабатывается свободными разработчиками.
Ключевые возможности
Рассматриваемый продукт для Питона обладает мощным функционалом. Он поддерживает следующие возможности:
- объекты data frame для управления индексированными массивами двумерной информации;
- встроенные средства совмещения данных, а также способы обработки сопутствующих сведений;
- инструменты, необходимые для обмена электронными материалами между структурами памяти, а также всевозможными файлами и документами;
- срезы по значениям индексов;
- расширенные возможности при индексировании;
- наличие выборки из больших объемов наборов информации;
- вставка, а также удаление столбцов в массиве;
- встроенные средства совмещения информации;
- обработка отсутствующих сведений;
- слияние и объединение имеющихся информационных наборов;
- иерархическое индексирование, при помощи которой удается обрабатывать материалы высокой размерности в структурах с меньшей размерностью;
- группировка, позволяющая выполнять трехэтапные операции типа «разделение, изменение и объединение» одновременно.
Проект поддерживает временные ряды. Он позволяет формировать временные периоды, изменять интервалы и так далее. Изначально создавался для обеспечения высокой производительности. Наиболее важные его части сформированы на C и Cython.
Начало работы
Pandas – функциональный и удобный проект для обработки данных. Далее предстоит разобраться с основами работы с ним. Для машинного обучения часто используются специальные библиотеки – Google Colab и Jupyter Notebook. Такие названия получили специализированные IDE. Они дают возможность работать с данными итеративно и пошагово. При их применении не требуется писать полноценное программное обеспечение.
Рекомендуется сначала установить IDE. В них Pandas встроен по умолчанию – ничего и никуда инициализировать не придется. Остается лишь произвести импорт в исходный код.
Если не использовать специализированные среды, разработчику потребуется Python выше версии 2.7. Импортирование Пандас происходит при помощи такой команды:
или , где pd – это официальное сокращение Pandas.
При использовании PIP необходимо воспользоваться следующей командой:

Для импорта PD и NumPy в Python-скрипт потребуется добавить такой блок кода:
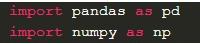
Связано это с тем, что PD зависит от NumPy. Соответствующая зависимость тоже должна быть импортирована в исходный код приложения. Теперь все готово к полноценному применению модуля при разработке программных продуктов разной сложности.
Структуры данных
Изучаемый модуль поддерживает несколько информационных структур:
- Series. Выражается одномерным массивом неизменного размера. Напоминает структуру с однородными данными.
- DataFrames. Двумерная табличная структуру. Поддерживает изменение размера. Столбцы в ней будут неоднородно типизированными.
- Panel. Трехмерный массив, который может меняться в размерах.
Других вариантов у PD нет. Далее первые две структурные единицы будут изучены более подробно. Они используются в программных кодах чаще всего.
Класс Series
Series – объект, который напоминает одномерный массив. Может включать в себя любые типы данных. Часто представлен в виде столбца таблицы с последовательностями тех или иных значений. Каждый из них будет наделен индексом – номером строки.

При обработке соответствующего кода на экране появится такая запись:

Series будет отображаться в виде таблицы с индексами компонентов. Соответствующая информация выводится в первом столбце. Второй отводится непосредственно под заданные значения.
Data Frame
DataFrame – это таблица с разными типами столбцов. Представляет собой двумерную информационную структуру. Является основным типом информации в Pandas. Вокруг DataFrame строится вся дальнейшая работа.
Соответствующий объект может быть представлен обычной таблицей (подобной той, что встречается в Excel), с любым количеством не только строк, но и столбцов. Внутри ее ячеек содержатся самые разные сведения:
- числовые;
- булевы;
- строковые и так далее.
DataFrame имеет индексы не только столбцов, но и строк. За счет подобной особенности удается сортировать и фильтровать сведения и находить нужные значения быстро и максимально комфортно.
В DataFrame поддерживается жесткое кодирование, а также импорт:
- CSV;
- TSV;
- Excel-документов;
- SQL-таблиц.
Для создания соответствующего компонента допускается использование команды:

- data – это создание объекта из входных сведений (NumPy, series, dict и им подобные);
- index – строковые метки;
- columns – создание подписей столбцов;
- dtype – ссылка на тип сведений, содержащихся в каждом столбце (этот параметр не является обязательным);
- copy – копирование сведений, если они предусмотрены изначально.
Создание DataFrame может производиться различными способами. Пример – формирование объекта из словаря или их списков, кортежей, файла Excel.
Вот пример кода, использующего список словарей для создания DataFrame:
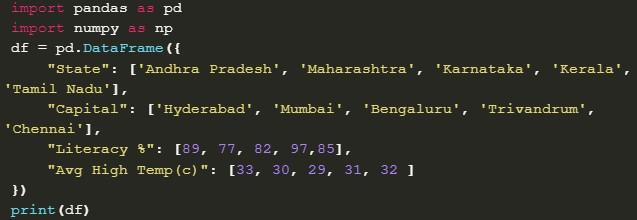
При обработке предложенного фрагмента система выведен на терминал/экран устройства следующую информацию:
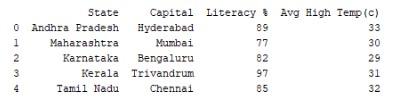
Работает код достаточно просто: сначала создается словарь, а затем в него передается в качестве аргумента метод DataFrame(). После получения тех или иных значений система выводит объект на печать в терминале.
Индекс здесь будет отображаться в самом первом левом столбце. Он имеет метки строк. Заголовки и электронные материалы – это сама таблица. При помощи настройки индексных параметров удается создавать индексированные DataFrames.
Импорт CSV
При создании DataFrame можно воспользоваться импортом файла CSV. Так называется текстовый документ. В нем запись материалов и значений ведется в каждой строке, разделяясь символом запятой.
Pandas поддерживает метод read_csv. С его помощью удается считывать содержимое CSV. Соответствующая команда поддерживает несколько параметров управления импортом:
- Sep. Он позволяет явно указывать разделители, используемые при выгрузке материалов. По умолчанию это символ запятой. Данный параметр является полезным при нестандартных разделителях в исходном документе. Пример – когда там применяются точки с запятыми или табуляция.
- Dtype. При помощи этой характеристики удается явно указывать тип, используемый в столбцах. Применяется, когда автоматически определяемый формат оказывается неверным. Пример – если дата импортируется в качестве строковой переменной.
А вот фрагмент кода, позволяющий импортировать сведения о скорости мобильного и стационарного интернета в разных странах. Здесь необходимо скачать исходный документ. После этого останется указать метод:

Чтобы увидеть DataFrame, останется вывести его на печать:

При работе в Jupiter Notebook и Google Collab для вывода DataFrame, а также Series, необходимо использовать команду print. Без нее модуль тоже сможет показать интересующие сведения. При написании print(df) будет потеряна табличная верстка.

В верхней части – названия столбцов, а слева указываются индексы. В нижней части выводится детализация о количестве столбцов и строк.
Полностью выводить табличку не обязательно. Для первого знакомства достаточно первых или последних пяти строчек. Чтобы воспользоваться соответствующими операциями, рекомендуется использование df.head() или df.tail() соответственно. В скобках указывается, сколько строчек выводить на экран. Этот параметр в Pandas по умолчанию равен 5.
Здесь можно увидеть больше информации об изученном модуле. А лучше программировать с его применением в Python помогут специализированные дистанционные компьютерные курсы.
Интересуют курсы по системному анализу и не только? Огромный выбор обучающих онлайн-программ по востребованным IT-направлениям есть в Otus !
Введение в pandas: анализ данных на Python

4 Март 2017 , Python, 766466 просмотров, Introduction to pandas: data analytics in Python
pandas это высокоуровневая Python библиотека для анализа данных. Почему я её называю высокоуровневой, потому что построена она поверх более низкоуровневой библиотеки NumPy (написана на Си), что является большим плюсом в производительности. В экосистеме Python, pandas является наиболее продвинутой и быстроразвивающейся библиотекой для обработки и анализа данных. В своей работе мне приходится пользоваться ею практически каждый день, поэтому я пишу эту краткую заметку для того, чтобы в будущем ссылаться к ней, если вдруг что-то забуду. Также надеюсь, что читателям блога заметка поможет в решении их собственных задач с помощью pandas, и послужит небольшим введением в возможности этой библиотеки.
DataFrame и Series
Чтобы эффективно работать с pandas, необходимо освоить самые главные структуры данных библиотеки: DataFrame и Series. Без понимания что они из себя представляют, невозможно в дальнейшем проводить качественный анализ.
Series
Структура/объект Series представляет из себя объект, похожий на одномерный массив (питоновский список, например), но отличительной его чертой является наличие ассоциированных меток, т.н. индексов, вдоль каждого элемента из списка. Такая особенность превращает его в ассоциативный массив или словарь в Python.
>>> import pandas as pd >>> my_series = pd.Series([5, 6, 7, 8, 9, 10]) >>> my_series 0 5 1 6 2 7 3 8 4 9 5 10 dtype: int64 >>> В строковом представлении объекта Series, индекс находится слева, а сам элемент справа. Если индекс явно не задан, то pandas автоматически создаёт RangeIndex от 0 до N-1, где N общее количество элементов. Также стоит обратить, что у Series есть тип хранимых элементов, в нашем случае это int64, т.к. мы передали целочисленные значения.
У объекта Series есть атрибуты через которые можно получить список элементов и индексы, это values и index соответственно.
>>> my_series.index RangeIndex(start=0, stop=6, step=1) >>> my_series.values array([ 5, 6, 7, 8, 9, 10], dtype=int64) Доступ к элементам объекта Series возможны по их индексу (вспоминается аналогия со словарем и доступом по ключу).
>>> my_series[4] 9 Индексы можно задавать явно:
>>> my_series2 = pd.Series([5, 6, 7, 8, 9, 10], index=['a', 'b', 'c', 'd', 'e', 'f']) >>> my_series2['f'] 10 Делать выборку по нескольким индексам и осуществлять групповое присваивание:
>>> my_series2[['a', 'b', 'f']] a 5 b 6 f 10 dtype: int64 >>> my_series2[['a', 'b', 'f']] = 0 >>> my_series2 a 0 b 0 c 7 d 8 e 9 f 0 dtype: int64 Фильтровать Series как душе заблагорассудится, а также применять математические операции и многое другое:
>>> my_series2[my_series2 > 0] c 7 d 8 e 9 dtype: int64 >>> my_series2[my_series2 > 0] * 2 c 14 d 16 e 18 dtype: int64 Если Series напоминает нам словарь, где ключом является индекс, а значением сам элемент, то можно сделать так:
>>> my_series3 = pd.Series() >>> my_series3 a 5 b 6 c 7 d 8 dtype: int64 >>> 'd' in my_series3 True У объекта Series и его индекса есть атрибут name, задающий имя объекту и индексу соответственно.
>>> my_series3.name = 'numbers' >>> my_series3.index.name = 'letters' >>> my_series3 letters a 5 b 6 c 7 d 8 Name: numbers, dtype: int64 Индекс можно поменять «на лету», присвоив список атрибуту index объекта Series
>>> my_series3.index = ['A', 'B', 'C', 'D'] >>> my_series3 A 5 B 6 C 7 D 8 Name: numbers, dtype: int64 Имейте в виду, что список с индексами по длине должен совпадать с количеством элементов в Series.
DataFrame
Объект DataFrame лучше всего представлять себе в виде обычной таблицы и это правильно, ведь DataFrame является табличной структурой данных. В любой таблице всегда присутствуют строки и столбцы. Столбцами в объекте DataFrame выступают объекты Series, строки которых являются их непосредственными элементами.
DataFrame проще всего сконструировать на примере питоновского словаря:
>>> df = pd.DataFrame(< . 'country': ['Kazakhstan', 'Russia', 'Belarus', 'Ukraine'], . 'population': [17.04, 143.5, 9.5, 45.5], . 'square': [2724902, 17125191, 207600, 603628] . >) >>> df country population square 0 Kazakhstan 17.04 2724902 1 Russia 143.50 17125191 2 Belarus 9.50 207600 3 Ukraine 45.50 603628 Чтобы убедиться, что столбец в DataFrame это Series, извлекаем любой:
>>> df['country'] 0 Kazakhstan 1 Russia 2 Belarus 3 Ukraine Name: country, dtype: object >>> type(df['country'])
Объект DataFrame имеет 2 индекса: по строкам и по столбцам. Если индекс по строкам явно не задан (например, колонка по которой нужно их строить), то pandas задаёт целочисленный индекс RangeIndex от 0 до N-1, где N это количество строк в таблице.
>>> df.columns Index([u'country', u'population', u'square'], dtype='object') >>> df.index RangeIndex(start=0, stop=4, step=1) В таблице у нас 4 элемента от 0 до 3.
Доступ по индексу в DataFrame
Индекс по строкам можно задать разными способами, например, при формировании самого объекта DataFrame или «на лету»:
>>> df = pd.DataFrame(< . 'country': ['Kazakhstan', 'Russia', 'Belarus', 'Ukraine'], . 'population': [17.04, 143.5, 9.5, 45.5], . 'square': [2724902, 17125191, 207600, 603628] . >, index=['KZ', 'RU', 'BY', 'UA']) >>> df country population square KZ Kazakhstan 17.04 2724902 RU Russia 143.50 17125191 BY Belarus 9.50 207600 UA Ukraine 45.50 603628 >>> df.index = ['KZ', 'RU', 'BY', 'UA'] >>> df.index.name = 'Country Code' >>> df country population square Country Code KZ Kazakhstan 17.04 2724902 RU Russia 143.50 17125191 BY Belarus 9.50 207600 UA Ukraine 45.50 603628 Как видно, индексу было задано имя — Country Code. Отмечу, что объекты Series из DataFrame будут иметь те же индексы, что и объект DataFrame:
>>> df['country'] Country Code KZ Kazakhstan RU Russia BY Belarus UA Ukraine Name: country, dtype: object Доступ к строкам по индексу возможен несколькими способами:
- .loc — используется для доступа по строковой метке
- .iloc — используется для доступа по числовому значению (начиная от 0)
>>> df.loc['KZ'] country Kazakhstan population 17.04 square 2724902 Name: KZ, dtype: object >>> df.iloc[0] country Kazakhstan population 17.04 square 2724902 Name: KZ, dtype: object Можно делать выборку по индексу и интересующим колонкам:
>>> df.loc[['KZ', 'RU'], 'population'] Country Code KZ 17.04 RU 143.50 Name: population, dtype: float64 Как можно заметить, .loc в квадратных скобках принимает 2 аргумента: интересующий индекс, в том числе поддерживается слайсинг и колонки.
>>> df.loc['KZ':'BY', :] country population square Country Code KZ Kazakhstan 17.04 2724902 RU Russia 143.50 17125191 BY Belarus 9.50 207600 Фильтровать DataFrame с помощью т.н. булевых массивов:
>>> df[df.population > 10][['country', 'square']] country square Country Code KZ Kazakhstan 2724902 RU Russia 17125191 UA Ukraine 603628 Кстати, к столбцам можно обращаться, используя атрибут или нотацию словарей Python, т.е. df.population и df[‘population’] это одно и то же.
Сбросить индексы можно вот так:
>>> df.reset_index() Country Code country population square 0 KZ Kazakhstan 17.04 2724902 1 RU Russia 143.50 17125191 2 BY Belarus 9.50 207600 3 UA Ukraine 45.50 603628 pandas при операциях над DataFrame, возвращает новый объект DataFrame.
Добавим новый столбец, в котором население (в миллионах) поделим на площадь страны, получив тем самым плотность:
>>> df['density'] = df['population'] / df['square'] * 1000000 >>> df country population square density Country Code KZ Kazakhstan 17.04 2724902 6.253436 RU Russia 143.50 17125191 8.379469 BY Belarus 9.50 207600 45.761079 UA Ukraine 45.50 603628 75.377550 Не нравится новый столбец? Не проблема, удалим его:
>>> df.drop(['density'], axis='columns') country population square Country Code KZ Kazakhstan 17.04 2724902 RU Russia 143.50 17125191 BY Belarus 9.50 207600 UA Ukraine 45.50 603628 Особо ленивые могут просто написать del df[‘density’].
Переименовывать столбцы нужно через метод rename:
>>> df = df.rename(columns=) >>> df country_code country population square 0 KZ Kazakhstan 17.04 2724902 1 RU Russia 143.50 17125191 2 BY Belarus 9.50 207600 3 UA Ukraine 45.50 603628
В этом примере перед тем как переименовать столбец Country Code, убедитесь, что с него сброшен индекс, иначе не будет никакого эффекта.
Чтение и запись данных
pandas поддерживает все самые популярные форматы хранения данных: csv, excel, sql, буфер обмена, html и многое другое:
Чаще всего приходится работать с csv-файлами. Например, чтобы сохранить наш DataFrame со странами, достаточно написать:
>>> df.to_csv('filename.csv')Функции to_csv ещё передаются различные аргументы (например, символ разделителя между колонками) о которых подробнее можно узнать в официальной документации.
Считать данные из csv-файла и превратить в DataFrame можно функцией read_csv.
>>> df = pd.read_csv('filename.csv', sep=',') Аргумент sep указывает разделитесь столбцов. Существует ещё масса способов сформировать DataFrame из различных источников, но наиболее часто используют CSV, Excel и SQL. Например, с помощью функции read_sql, pandas может выполнить SQL запрос и на основе ответа от базы данных сформировать необходимый DataFrame. За более подробной информацией стоит обратиться к официальной документации.
Группировка и агрегирование в pandas
Группировка данных один из самых часто используемых методов при анализе данных. В pandas за группировку отвечает метод .groupby. Я долго думал какой пример будет наиболее наглядным, чтобы продемонстрировать группировку, решил взять стандартный набор данных (dataset), использующийся во всех курсах про анализ данных — данные о пассажирах Титаника. Скачать CSV файл можно тут.
>>> titanic_df = pd.read_csv('titanic.csv') >>> print(titanic_df.head()) PassengerID Name PClass Age \ 0 1 Allen, Miss Elisabeth Walton 1st 29.00 1 2 Allison, Miss Helen Loraine 1st 2.00 2 3 Allison, Mr Hudson Joshua Creighton 1st 30.00 3 4 Allison, Mrs Hudson JC (Bessie Waldo Daniels) 1st 25.00 4 5 Allison, Master Hudson Trevor 1st 0.92 Sex Survived SexCode 0 female 1 1 1 female 0 1 2 male 0 0 3 female 0 1 4 male 1 0 Необходимо подсчитать, сколько женщин и мужчин выжило, а сколько нет. В этом нам поможет метод .groupby.
>>> print(titanic_df.groupby(['Sex', 'Survived'])['PassengerID'].count()) Sex Survived female 0 154 1 308 male 0 709 1 142 Name: PassengerID, dtype: int64 А теперь проанализируем в разрезе класса кабины:
>>> print(titanic_df.groupby(['PClass', 'Survived'])['PassengerID'].count()) PClass Survived * 0 1 1st 0 129 1 193 2nd 0 160 1 119 3rd 0 573 1 138 Name: PassengerID, dtype: int64 Сводные таблицы в pandas
Термин «сводная таблица» хорошо известен тем, кто не по наслышке знаком с инструментом Microsoft Excel или любым иным, предназначенным для обработки и анализа данных. В pandas сводные таблицы строятся через метод .pivot_table. За основу возьмём всё тот же пример с Титаником. Например, перед нами стоит задача посчитать сколько всего женщин и мужчин было в конкретном классе корабля:
>>> titanic_df = pd.read_csv('titanic.csv') >>> pvt = titanic_df.pivot_table(index=['Sex'], columns=['PClass'], values='Name', aggfunc='count') В качестве индекса теперь у нас будет пол человека, колонками станут значения из PClass, функцией агрегирования будет count (подсчёт количества записей) по колонке Name.
>>> print(pvt.loc['female', ['1st', '2nd', '3rd']]) PClass 1st 143.0 2nd 107.0 3rd 212.0 Name: female, dtype: float64 Всё очень просто.
Анализ временных рядов
В pandas очень удобно анализировать временные ряды. В качестве показательного примера я буду использовать цену на акции корпорации Apple за 5 лет по дням. Файл с данными можно скачать тут.
>>> import pandas as pd >>> df = pd.read_csv('apple.csv', index_col='Date', parse_dates=True) >>> df = df.sort_index() >>> print(df.info()) DatetimeIndex: 1258 entries, 2017-02-22 to 2012-02-23 Data columns (total 6 columns): Open 1258 non-null float64 High 1258 non-null float64 Low 1258 non-null float64 Close 1258 non-null float64 Volume 1258 non-null int64 Adj Close 1258 non-null float64 dtypes: float64(5), int64(1) memory usage: 68.8 KB Здесь мы формируем DataFrame с DatetimeIndex по колонке Date и сортируем новый индекс в правильном порядке для работы с выборками. Если колонка имеет формат даты и времени отличный от ISO8601, то для правильного перевода строки в нужный тип, можно использовать метод pandas.to_datetime.
Давайте теперь узнаем среднюю цену акции (mean) на закрытии (Close):
>>> df.loc['2012-Feb', 'Close'].mean() 528.4820021999999 А если взять промежуток с февраля 2012 по февраль 2015 и посчитать среднее:
>>> df.loc['2012-Feb':'2015-Feb', 'Close'].mean() 430.43968317018414 А что если нам нужно узнать среднюю цену закрытия по неделям?!
>>> df.resample('W')['Close'].mean() Date 2012-02-26 519.399979 2012-03-04 538.652008 2012-03-11 536.254004 2012-03-18 576.161993 2012-03-25 600.990001 2012-04-01 609.698003 2012-04-08 626.484993 2012-04-15 623.773999 2012-04-22 591.718002 2012-04-29 590.536005 2012-05-06 579.831995 2012-05-13 568.814001 2012-05-20 543.593996 2012-05-27 563.283995 2012-06-03 572.539994 2012-06-10 570.124002 2012-06-17 573.029991 2012-06-24 583.739993 2012-07-01 574.070004 2012-07-08 601.937489 2012-07-15 606.080008 2012-07-22 607.746011 2012-07-29 587.951999 2012-08-05 607.217999 2012-08-12 621.150003 2012-08-19 635.394003 2012-08-26 663.185999 2012-09-02 670.611995 2012-09-09 675.477503 2012-09-16 673.476007 . 2016-08-07 105.934003 2016-08-14 108.258000 2016-08-21 109.304001 2016-08-28 107.980000 2016-09-04 106.676001 2016-09-11 106.177498 2016-09-18 111.129999 2016-09-25 113.606001 2016-10-02 113.029999 2016-10-09 113.303999 2016-10-16 116.860000 2016-10-23 117.160001 2016-10-30 115.938000 2016-11-06 111.057999 2016-11-13 109.714000 2016-11-20 108.563999 2016-11-27 111.637503 2016-12-04 110.587999 2016-12-11 111.231999 2016-12-18 115.094002 2016-12-25 116.691998 2017-01-01 116.642502 2017-01-08 116.672501 2017-01-15 119.228000 2017-01-22 119.942499 2017-01-29 121.164000 2017-02-05 125.867999 2017-02-12 131.679996 2017-02-19 134.978000 2017-02-26 136.904999 Freq: W-SUN, Name: Close, dtype: float64 Resampling мощный инструмент при работе с временными рядами (time series), помогающий переформировать выборку так, как удобно вам. Метод resample первым аргументом принимает строку rule. Все доступные значения можно найти в документации.
Визуализация данных в pandas
Для визуального анализа данных, pandas использует библиотеку matplotlib. Продемонстрирую простейший способ визуализации в pandas на примере с акциями Apple.
Берём цену закрытия в промежутке между 2012 и 2017.
>>> import matplotlib.pyplot as plt >>> new_sample_df = df.loc['2012-Feb':'2017-Feb', ['Close']] >>> new_sample_df.plot() >>> plt.show() И видим вот такую картину:
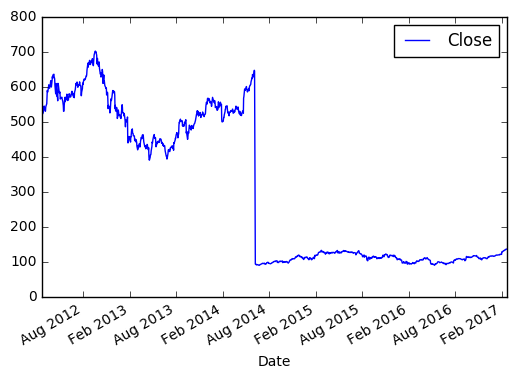
По оси X, если не задано явно, всегда будет индекс. По оси Y в нашем случае цена закрытия. Если внимательно посмотреть, то в 2014 году цена на акцию резко упала, это событие было связано с тем, что Apple проводила сплит 7 к 1. Так мало кода и уже более-менее наглядный анализ 😉
Эта заметка демонстрирует лишь малую часть возможностей pandas. Со своей стороны я постараюсь по мере своих сил обновлять и дополнять её.
Полезные ссылки
- pandas cheatsheet
- Официальная документация pandas
- Почему Python
- Python Data Science Handbook
Интересные записи:
- Обзор Python 3.9
- Celery: начинаем правильно
- FastAPI, asyncio и multiprocessing
- Руководство по работе с HTTP в Python. Библиотека requests
- Django Channels: работа с WebSocket и не только
- Почему Python?
- Введение в logging на Python
- Pyenv: удобный менеджер версий python
- Что нового появилось в Django Channels?
- Работа с MySQL в Python
- Как написать Telegram бота: практическое руководство
- Авторизация через Telegram в Django и Python
- Python-RQ: очередь задач на базе Redis
- Разворачиваем Django приложение в production на примере Telegram бота
- Работа с PostgreSQL в Python
- Django, RQ и FakeRedis
- Итоги первой встречи Python программистов в Алматы
- Обзор Python 3.8
- Интеграция Trix editor в Django
- Участие в подкасте TalkPython
- Строим Data Pipeline на Python и Luigi
- Видео презентации ETL на Python
- Авторизация через Telegram в Django приложении
Анализируем данные: структура Series в Pandas
Обработка и анализ данных – важнейшая часть работы специалиста по системному анализу. В этом может помочь Pandas — программная высокоуровневая библиотека, написанная на Python. Главными структурами данных в ней являются Series и DataFrame. Не понимая их работу, выполнить качественный анализ будет невозможно. Сегодня поговорим про Series.
Series — объект, напоминающий одномерный массив (к примеру, список в Python). Отличительная черта — ассоциированные метки или так называемые индексы, расположенные, вдоль каждого элемента списка. Это особенность и превращает Series в ассоциативный массив либо словарь в Python.
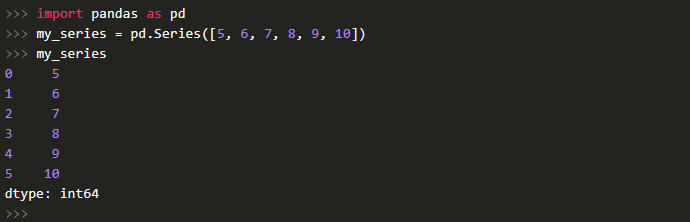
В строковом представлении Series индекс находится слева, а элемент справа. Если же индекс не задан явно, pandas автоматически создаст RangeIndex от 0 до N-1, где N — общее число элементов. Кроме того, следует учесть, что в Series существует тип хранимых элементов (в примере это int64, ведь мы передавали целочисленные значения).
Также у объекта Series есть атрибуты, посредством которых вы сможете получить список элементов и индексы — values и index соответственно.
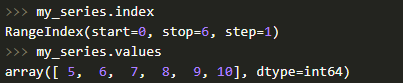
Доступ к элементам Series осуществляется по индексу этих элементов.

При этом мы можем задавать индексы явно:

Также есть возможность осуществлять выборку по нескольким индексам и выполнять групповое присваивание:
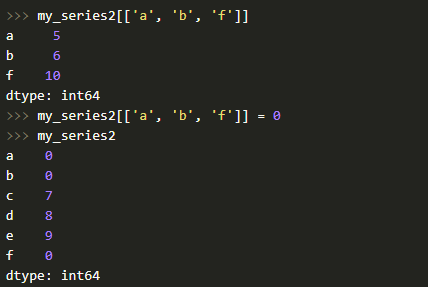
Что касается фильтрации, то это тоже не проблема для Series, плюс можно применять математические операции и т. д.:
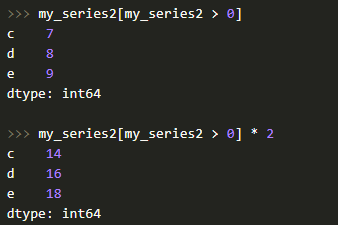
Но если сам объект Series напоминает словарь, где ключ — это индекс, а значение — сам элемент, то мы можем сделать следующее:
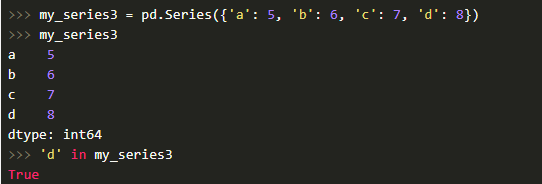
У объекта Series и его индекса присутствует атрибут name, который задает имя объекту и индексу.
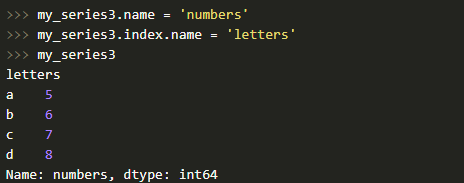
Индекс мы можем поменять без проблем, присвоив список атрибуту index объекта Series.
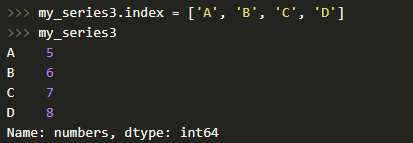
Также имейте в виду, что список с индексами по длине в обязательном порядке должен совпадать с числом элементов в Series.
Изучаем pandas. Урок 2. Структуры данных Series и DataFrame


Во втором уроке мы познакомимся со структурами данных pandas – это Series и DataFrame. Основное внимание будет уделено вопросам создания и получения доступа к элементам данных структур, а также общим понятиям, которые позволят более интуитивно работать с ними в будущем.
Введение
Библиотека pandas предоставляет две структуры: Series и DataFrame для быстрой и удобной работы с данными (на самом деле их три, есть еще одна структура – Panel , но в данный момент она находится в статусе deprecated и в будущем будет исключена из состава библиотеки pandas ). Series – это маркированная одномерная структура данных, ее можно представить, как таблицу с одной строкой. С Series можно работать как с обычным массивом (обращаться по номеру индекса), и как с ассоциированным массивом, когда можно использовать ключ для доступа к элементам данных. DataFrame – это двумерная маркированная структура. Идейно она очень похожа на обычную таблицу, что выражается в способе ее создания и работе с ее элементами. Panel – про который было сказано, что он вскоре будет исключен из pandas , представляет собой трехмерную структуру данных. О Panel мы больше говорить не будем. В рамках этой части мы остановимся на вопросах создания и получения доступа к элементам данных структур Series и DataFrame .
Структура данных Series
Для того, чтобы начать работать со структурами данных из pandas требуется предварительно импортировать необходимые модули. Убедитесь, что нужные модули установлены на вашем компьютере, о том, как это сделать, можно прочитать в первой части данного курса. Также будем считать, что вы знакомы с языком Python . Если нет, то специально для вас мы подготовили он-лайн курс и книгу.
Помимо самого pandas нам понадобится библиотека numpy . Наши эксперименты будем проводить с использованием пакета Anaconda , в качестве среды разработки советуем взять Spyder , который входит в базовую поставку Anaconda . Для того, чтобы запустить Spyder , перейдите в каталог Scripts , который находится в папке с установленной Anaconda и запустите spyder.exe . Для нас он в первую очередь имеет ценность в том, что в нем есть редактор исходного кода, на случай, если нам понадобится написать довольно большую программу, и интерпретатор для быстрых экспериментов. Если строки кода будут содержать префикс в виде цифры в квадратных скобках, то это означает, что данные команды мы вводим в интерпретаторе, в ином случае, это будет означать, что код написан в редакторе.
Пора переходить к практике!
Импортируем нужные нам библиотеки.
In [1]: import numpy as np In [2]: import pandas as pd
Создать структуру Series можно на базе различных типов данных:
- словари Python ;
- списки Python ;
- массивы из numpy: ndarray ;
- скалярные величины.
Конструктор класса Series выглядит следующим образом:
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
data – массив, словарь или скалярное значение, на базе которого будет построен Series;
index – список меток, который будет использоваться для доступа к элементам Series . Длина списка должна быть равна длине data ;
dtype – объект numpy.dtype , определяющий тип данных;
copy – создает копию массива данных, если параметр равен True в ином случае ничего не делает.
В большинстве случаев, при создании Series, используют только первые два параметра. Рассмотрим различные варианты как это можно сделать.
Создание Series из списка Python
Самый простой способ создать Series – это передать в качестве единственного параметра в конструктор класса список Python.
In [3]: s1 = pd.Series([1, 2, 3, 4, 5]) In [4]: print(s1) 0 1 1 2 2 3 3 4 4 5 dtype: int64
В данном примере была создана структура Series на базе списка из языка Python . Для доступа к элементам Series , в данном случае, можно использовать только положительные целые числа – левый столбец чисел, начинающийся с нуля – это как раз и есть индексы элементов структуры, которые представлены в правом столбце.
Можно попробовать использоваться больше возможностей из тех, что предлагает pandas , для этого передадим в качестве второго элемента список строк (в нашем случае – это отдельные символы). Такой шаг позволит нам обращаться к элементам структуры Series не только по численному индексу, но и по метке, что сделает работу с таким объектом, похожей на работу со словарем.
In [5]: s2 = pd.Series([1, 2, 3, 4, 5], ['a', 'b', 'c', 'd', 'e']) In [6]: print(s2) a 1 b 2 c 3 d 4 e 5 dtype: int64
Обратите внимание на левый столбец, в нем содержатся метки, которые мы передали в качестве index параметра при создании структуры. Правый столбец – это по-прежнему элементы нашей структуры.
Создание Series из ndarray массива из numpy
Создадим простой массив из пяти чисел, аналогичный списку из предыдущего раздела. Библиотеки pandas и numpy должны быть предварительно импортированы.
In [3]: ndarr = np.array([1, 2, 3, 4, 5]) In [4]: type(ndarr) Out[4]: numpy.ndarray
Теперь создадим Series с буквенными метками.
In [5]: s3 = pd.Series(ndarr, ['a', 'b', 'c', 'd', 'e']) In [6]: print(s3) a 1 b 2 c 3 d 4 e 5 dtype: int32
Создание Series из словаря (dict)
Еще один способ создать структуру Series – это использовать словарь для одновременного задания меток и значений.
In [7]: d = 'a':1, 'b':2, 'c':3> In [8]: s4 = pd.Series(d) In [9]: print(s4) a 1 b 2 c 3 dtype: int64
Ключи ( keys ) из словаря d станут метками структуры s4 , а значения ( values ) словаря – значениями в структуре.
Создание Series с использованием константы
Рассмотрим еще один способ создания структуры. На этот раз значения в ячейках структуры будут одинаковыми.
In [10]: a = 7 In [11]: s5 = pd.Series(a, ['a', 'b', 'c']) In [12]: print(s5) a 7 b 7 c 7 dtype: int64
В созданной структуре Series имеется три элемента с одинаковым содержанием.
Работа с элементами Series
В будущем будет написан отдельный урок, посвященный индексации и работе с элементами Series и DataFrame , сейчас рассмотрим основные подходы.
К элементам Series можно обращаться по численному индексу, при таком подходе работа со структурой не отличается от работы со списками в Python .
In [13]: s6 = pd.Series([1, 2, 3, 4, 5], ['a', 'b', 'c', 'd', 'e']) In [14]: s6[2] Out[14]: 3
Можно использовать метку, тогда работа с Series будет похожа на работу со словарем (dict) в Python.
In [15]: s6['d'] Out[15]: 4
Доступно получение slice’ов.
In [16]: s6[:2] Out[16]: a 1 b 2 dtype: int64
В поле для индекса можно поместить условное выражение.
In [17]: s6[s6 3] Out[17]: a 1 b 2 c 3 dtype: int64
Со структурами Series можно работать как с векторами: складывать, умножать вектор на число и т.п.
In [18]: s7 = pd.Series([10, 20, 30, 40, 50], ['a', 'b', 'c', 'd', 'e']) In [19]: s6 + s7 Out[19]: a 11 b 22 c 33 d 44 e 55 dtype: int64 In [20]: s6 * 3 Out[20]: a 3 b 6 c 9 d 12 e 15 dtype: int64
Структура данных DataFrame
Если Series представляет собой одномерную структуру, которую для себя можно представить как таблицу с одной строкой, то DataFrame – это уже двумерная структура – полноценная таблица с множеством строк и столбцов.
Перед работой с DataFrame не забудьте импортировать библиотеку pandas .
Конструктор класса DataFrame выглядит так:
class pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
data – массив ndarray , словарь ( dict ) или другой DataFrame ;
index – список меток для записей (имена строк таблицы);
columns – список меток для полей (имена столбцов таблицы);
dtype – объект numpy.dtype , определяющий тип данных;
copy – создает копию массива данных, если параметр равен True в ином случае ничего не делает.
Структуру DataFrame можно создать на базе:
- словаря ( dict ) в качестве элементов которого должны выступать: одномерные ndarray , списки, другие словари, структуры Series ;
- двумерные ndarray ;
- структуры Series ;
- структурированные ndarray ;
- другие DataFrame .
Рассмотрим на практике различные подходы к созданию DataFrame’ов .
Создание DataFrame из словаря
В данном случае будет использоваться одномерный словарь, элементами которого будут списки, структуры Series и т.д.
Начнем с Series.
In [3]: d = "price":pd.Series([1, 2, 3], index=['v1', 'v2', 'v3']), . : "count": pd.Series([10, 12, 7], index=['v1', 'v2', 'v3'])> In [4]: df1 = pd.DataFrame(d) In [5]: print(df1) count price v1 10 1 v2 12 2 v3 7 3 In [6]: print(df1.index) Index(['v1', 'v2', 'v3'], dtype='object') In [7]: print(df1.columns) Index(['count', 'price'], dtype='object')
Теперь построим аналогичный словарь, но на элементах ndarray .
In [8]: d2 = "price":np.array([1, 2, 3]), . : "count": np.array([10, 12, 7])> In [9]: df2 = pd.DataFrame(d2, index=['v1', 'v2', 'v3']) In [10]: print(df2) count price v1 10 1 v2 12 2 v3 7 3 In [11]: print(df2.index) Index(['v1', 'v2', 'v3'], dtype='object') In [12]: print(df2.columns) Index(['count', 'price'], dtype='object')
Как видно – результат аналогичен предыдущему. Вместо ndarray можно использовать обычный список из Python .
Создание DataFrame из списка словарей
До это мы создавали DataFrame из словаря, элементами которого были структуры Series , списки и массивы, сейчас мы создадим DataFrame из списка, элементами которого являются словари.
In [13]: d3 = ["price": 3, "count":8>, "price": 4, "count": 11>] In [14]: df3 = pd.DataFrame(d3) In [15]: print(df3) count price 0 8 3 1 11 4 In [16]: print(df3.info()) class 'pandas.core.frame.DataFrame'> RangeIndex: 2 entries, 0 to 1 Data columns (total 2 columns): count 2 non-null int64 price 2 non-null int64 dtypes: int64(2) memory usage: 112.0 bytes None
Создание DataFrame из двумерного массива
Создать DataFrame можно также и из двумерного массива, в нашем примере это будет ndarray из библиотеки numpy .
In [17]: nda1 = np.array([[1, 2, 3], [10, 20, 30]]) In [18]: df4 = pd.DataFrame(nda1) In [19]: print(df4) 0 1 2 0 1 2 3 1 10 20 30
Работа с элементами DataFrame
Работа с элементами DataFrame – доступ к элементам данной структуры – тема достаточно обширная и она будет освещена в одном из ближайших уроков. Сейчас мы рассмотрим наиболее часто используемые способы работы с элементами DataFrame .
Основные подходы представлены в таблице ниже.
| Операция | Синтаксис | Возвращаемый результат |
| Выбор столбца | df[col] | Series |
| Выбор строки по метке | df.loc[label] | Series |
| Выбор строки по индексу | df.iloc[loc] | Series |
| Слайс по строкам | df[0:4] | DataFrame |
| Выбор строк, отвечающих условию | df[bool_vec] | DataFrame |
Теперь посмотрим, как использовать данные операций на практике.
Для начала создадим DataFrame .
In [3]: d = "price":np.array([1, 2, 3]), . : "count": np.array([10, 20, 30])> In [4]: df = pd.DataFrame(d, index=['a', 'b', 'c']) In [5]: print(df) count price a 10 1 b 20 2 c 30 3
Операция: выбор столбца.
In [6]: df['count'] Out[6]: a 10 b 20 c 30 Name: count, dtype: int32
Операция: выбор строки по метке.
In [7]: df.loc['a'] Out[7]: count 10 price 1 Name: a, dtype: int32
Операция: выбор строки по индексу.
In [8]: df.iloc[1] Out[8]: count 20 price 2 Name: b, dtype: int32
Операция: slice по строкам.
In [9]: df[0:2] Out[9]: count price a 10 1 b 20 2
Операция: выбор строк, отвечающих условию.
In [10]: df[df['count'] >= 20] Out[10]: count price b 20 2 c 30 3
P.S.
Раздел: Pandas Python Машинное обучение и анализ данных Метки: ML, Pandas, Python, Машинное обучение
Изучаем pandas. Урок 2. Структуры данных Series и DataFrame : 6 комментариев
- Lumen 15.03.2019 Опечатка: случае[т]
В большинстве случает, при создании Series P.S. Спасибо за статью!
- writer 16.03.2019 Спасибо! Поправили))
- writer 21.10.2019 Спасибо! Добавим!
- writer 21.10.2019 Как мне кажется, ‘slice’ стало уже сленговым словом, и его вполне можно употреблять. Но слово ‘срез’ звучит тоже не плохо))) В данном случае выбор был сделан в пользу первого.