Передача потоковых данных (streaming)

Передача потоковых данных (streaming) – услуга сети, которая позволяет передавать аудио или видео данные в непрерывном (потоковом) режиме. В качестве содержимого могут выступать программы телевизионных передач, трансляции матчей и концертов, радиопередачи и т.п. Набольший интерес к данной услуге появился после широкого распространения сети Internet. Многие web-ресурсы для борьбы за авторские права не допускают скачивать видео и аудио файлы, а только просматривать и прослушивать их в поточном режиме. При этом сам файл не сохраняется на пользовательской стороне и не может быть растиражирован. Однако для минимальных задержек во время просмотра (прослушивания) файла и сохранения его исходного качества при просмотре необходима довольно высокая скорость передачи данных (несколько сотен килобит в секунду).
С появлением сетей 3G, в частности, построенных на основании стандарта UMTS (Universal Mobile Telecommunications System), streaming стал активно использоваться и в сотовой связи. А audio streaming использовался еще в сетях второго поколения, благодаря технологии EDGE.
Для организации услуги потоковой передачи данных оборудование абонента должно быть способно обрабатывать входящий поток данных (буферизировать и исправлять ошибки) и отправлять данные на медиа проигрыватель для воспроизведения. Благодаря буферизации удается немного снизить проблемы с неравномерным поступлением пакетов на оконечное оборудование. Преимуществом потоковой передачи данных перед VoD (Video on demand) или скачиванием файла является отсутствие необходимости хранения данных. Таким образом, в мобильном устройстве не требуется большого места для хранения медиа файлов.
Сервер, который является источником данных, может быть размещен на площадке данного оператора, либо в другой сети. Кроме того, поток может поступать из Internet. От сети оператора сотовой связи требуется лишь обеспечить передачу потока с заданным качеством обслуживания. Для услуги streaming в стандартах 3G и 4G изначально предусматриваются механизмы, не допускающие большие задержки и высокий процент потери данных.
При использовании материалов ссылка на сайт обязательна
—С автором сайта можно связаться по e-mail: ipleto@gmail.com
Что такое потоковая передача данных в режиме реального времени?

Что такое потоковая передача данных в режиме реального времени?
Потоковая передача данных в режиме реального времени включает сбор и получение последовательности данных из различных источников. Кроме того, такие данные также оперативно обрабатываются, что дает возможность извлекать значение и аналитические сведения.
Примеры потоковых данных: файлы журналов, генерируемые пользователями мобильных или интернет-приложений, покупки в интернет-магазинах, действия игроков в играх, информация из социальных сетей, финансовых торговых площадок и геопространственных сервисов, а также телеметрические данные, полученные от подключенных устройств или оборудования в центрах обработки данных.
Потоковая передача данных в режиме реального времени дает возможность оперативно анализировать и обрабатывать данные вместо того, чтобы ждать ответов в течение нескольких часов, дней или даже недель.
Из чего состоит передача данных в режиме реального времени?

Источник. Сотни и тысячи устройств или приложений, которые производят большие объемы непрерывных данных с высокой скоростью. Примерами могут служить мобильные устройства, веб-приложения (история посещений), журналы приложений, датчики Интренета вещей, смарт-устройства и игровые приложения.
Получение потоковых данных. Простая интеграция с более чем 15 сервисами AWS (Amazon API Gateway, AWS IoT Core, Amazon Cloudwatch и другими) дает возможность надежно и безопасно осуществлять непрерывный сбор данных, поступающих от тысяч устройств.
Хранилище потоковых данных. Выберите решение, отвечающее вашим потребностям в хранении данных с учетом требований к масштабированию, задержкам и обработке, например Потоки данных Amazon Kinesis, Данные Amazon Kinesis Firehose и Управляемая потоковая передача Amazon для Apache Kafka (Amazon MSK).
Обработка потоковых данных. Выберите один из множества сервисов, от решений для преобразования и непрерывной передачи данных в несколько щелчков мышью в такие места, как Данные Amazon Kinesis Firehose, до работающих в режиме реального времени мощных специализированных приложений и интеграций машинного обучения с применением таких сервисов, как Управляемый сервис Amazon для Apache Flink и AWS Lambda.
Место назначения. Передавайте потоковые данные в ряд полностью интегрированных озер данных, хранилищ данных и аналитических сервисов для дальнейшего анализа или длительного хранения, таких как Amazon S3, Amazon Redshift, Сервис Amazon OpenSearch и Amazon EMR.
Каковы примеры использования потоковой передачи данных в режиме реального времени?
Перемещение данных в режиме реального времени
Потоковая передача данных с сотен тысяч устройств и выполнение ETL-преобразований при больших объемах непрерывных и высокоскоростных данных в режиме реального времени дают пользователям возможность осуществлять анализ данных сразу после их получения, а затем длительное время хранить их в озере данных, хранилище данных или базе данных для дальнейшего анализа.
Аналитика в режиме реального времени
Анализируйте данные сразу после их получения и принимайте решения в масштабах организации в режиме реального времени, чтобы реализовать открывающиеся возможности, улучшить качество обслуживания клиентов, предотвратить сбои в работе сети или оперативно обновлять критически важные показатели деятельности.
Журналы. Собирайте, обрабатывайте и анализируйте журналы приложений в режиме реального времени.
Обновления в режиме реального времени. Привлекайте потребителей, геймеров, финансовых трейдеров и других пользователей, обеспечивая оперативное обновление важнейших показателей для принятия решений, рекомендаций и данных о взаимодействии с клиентами.
История посещений. Получите представление о производительности вашего интернет-контента и взаимодействии пользователей с вашими приложениями и веб-сайтами в режиме реального времени, в том числе об их поведении, затраченном времени, популярном контенте и других показателях.
Интернет вещей. Подключайтесь к сотням тысяч устройств Интернета вещей, собирайте, обрабатывайте и анализируйте потоковые данные в режиме реального времени.
Потоковая обработка событий
Фиксируйте события и оперативно реагируйте на них по мере возникновения в различных приложениях. Наиболее распространенные варианты использования – взаимодействие между сотнями изолированных микросервисов и ведение системы регистрации за счет сбора данных об изменениях.
Взаимодействие между изолированными микросервисами. При срабатывании любого микросервиса событие может отправляться в поток данных в режиме реального времени, и другие микросервисы могут «наблюдать» за потоком, чтобы определить, произошло ли какое-либо событие, инициирующее требуемое действие.
Сбор данных об изменениях. Все изменения данных в нескольких приложениях и базах данных могут в режиме реального времени передаваться в центральную систему регистрации.
Какие сервисы потоковой передачи данных доступны на базе AWS?
AWS предоставляет несколько вариантов работы с потоковыми данными в реальном времени.
- Потоки данных Amazon Kinesis– это масштабируемый и надежный сервис для потоковой передачи данных в реальном времени, который может ежесекундно обрабатывать гигабайты данных, поступающих из сотен тысяч источников.
- Данные Amazon Kinesis Firehoseдают возможность всего в несколько кликов захватывать, преобразовывать и загружать потоки данных в хранилища данных AWS для анализа в режиме, близком к реальному времени, с помощью существующих инструментов бизнес-аналитики.
- Управляемый сервис Amazon для Apache Flinkпреобразует и анализирует потоковые данные в реальном времени с помощью Apache Flink, платформы с открытым исходным кодом и механизма для обработки потоков данных.
- Управляемая потоковая передача Amazon для Apache Kafka – это полностью управляемый сервис, который упрощает создание и запуск приложений, использующих Apache Kafka для обработки потоковых данных.
Создайте аккаунт и начните потоковую передачу данных в реальном времени на базе AWS уже сегодня.
Потоковая передача данных: варианты использования, преимущества и примеры
Потоковая передача данных — это процесс непрерывного сбора данных по мере их создания и перемещения. Эти данные обычно обрабатываются программным обеспечением потоковой обработки.
Потоковая передача данных в сочетании с обработкой позволяет получать интеллектуальные данные в режиме реального времени.
Потоки данных могут создаваться из различных источников в любом формате и объеме. Самые мощные потоки объединяют несколько источников для формирования полной картины операций и процессов.
Например, данные сети, сервера и приложений можно объединить для мониторинга работоспособности вашего веб-сайта, а также для того, чтобы обнаружить снижение производительности.
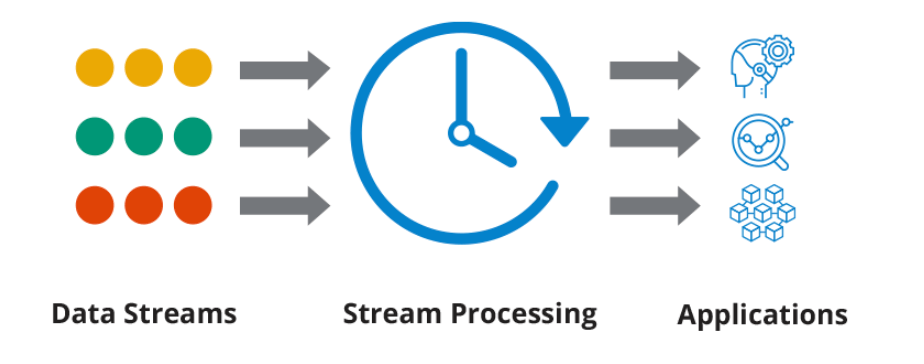
Что такое потоковая обработка?
Помимо передачи данных вам необходимо их обработать. ПО для потоковой обработки настроено на прием и анализ данных по конвейеру, чтобы выявить закономерности и тенденции. Потоковая обработка может также включать в себя визуализацию данных для информационных панелей.
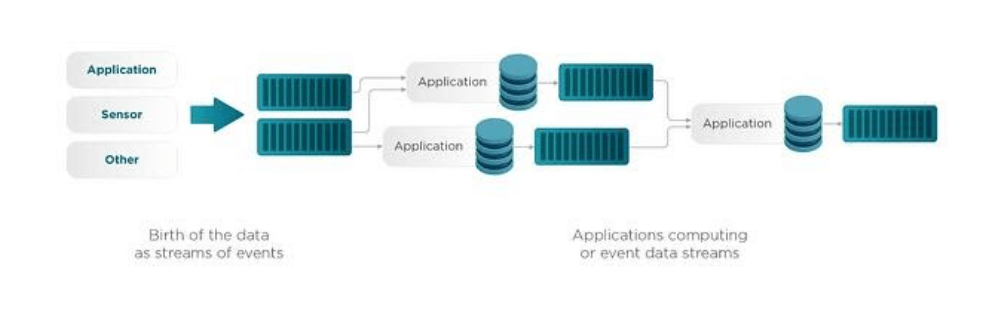
Далее потоки данных и потоковая обработка объединяются для получения информации в режиме реального времени. Падение производительности может привести к отставанию или пропуску точек данных.
ПО для потоковой обработки со временем необходимо масштабировать. Например, в том случае, если на вашем веб-сайте повышен трафик, и вы не хотите потерять данные о поведении пользователей.
Потоковые процессоры должны быть высоко доступными. Они должны продолжать выполнять свои задачи, даже если компоненты выходят из строя. Иначе это снизит качество данных, поскольку поток не будет анализироваться во время сбоя.
Преимущества потоковой передачи данных
- Действие в реальном времени.
Это основное преимущество потоковой передачи данных, так как в век информационных технологий новые данные появляются ежесекундно. Поэтому лучшие компании будут использовать самую свежую информацию из внутренних и внешних ресурсов.
- Конкурентное преимущество на рынке.
Возможность быстро собирать, анализировать и действовать на основе текущих данных дает компаниям конкурентное преимущество на рынке. Аналитика в режиме реального времени позволяет компаниям лучше реагировать на тенденции рынка, потребности клиентов и возможности для бизнеса.
- Удовлетворенность клиентов.
Чем быстрее компания сможет отреагировать на отзывы клиентов и решать возникающие проблемы, тем выше будет ее репутация. Таким образом удовлетворенность и лояльность клиентов будет увеличена.
Сокращение потерь.
Потоковая передача данных не только помогает удержать клиентов, но и предотвращает другие потери. Аналитика в режиме реального времени предупредит возможные сбои в работе, финансовые спады и утечки данных.
Эта информация поможет компании предотвратить или, по крайней мере, смягчить последствия этих событий.
Различия между потоковой обработкой и традиционной пакетной обработкой
Пакетная обработка — это поэтапный подход к сбору и обработке данных, а потоковая обработка выполняется с постоянной скоростью.
Потоковая обработка — это идеальный метод, когда скорость является основным фактором. Пакетная обработка используется там, где не требуется аналитика в реальном времени или данные не могут быть преобразованы в поток данных для анализа, например, при работе с устаревшими технологиями.
Примеры потока данных
Потоки данных нужны для того, чтобы охватить данные всех типов. Важно, чтобы эти данные были критически важны для отслеживания в режиме реального времени.
Это могут быть данные о местонахождении, цены на акции, мониторинг IT-систем, обнаружение мошенничества, продажи, активность клиентов и многое другое.
Ниже рассмотрим две компании, которые используют некоторые из этих типов данных, чтобы обеспечить свою активность.
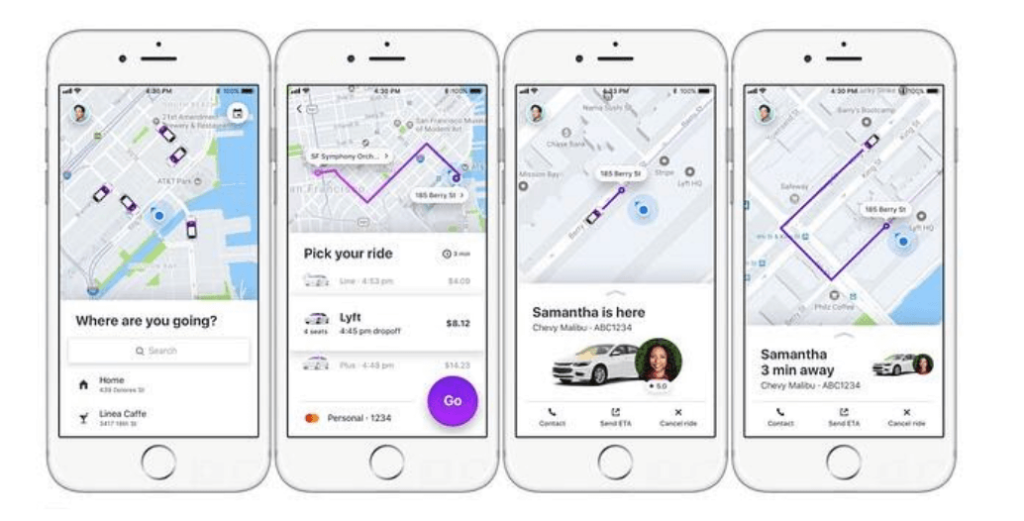
1. Lyft
Lyft — это приложение для обмена поездками, которому необходимы данные с точностью до секунды, чтобы скоординировать пассажиров и водителей.
Lyft показывает пассажиру доступные автомобили и цены на различные уровни обслуживания в зависимости от расстояния, спроса и условий движения. Все эти факторы могут измениться за считанные секунды, а это означает, что Lyft должен иметь доступ к этим данным мгновенно.
После того, как пассажир выбирает уровень обслуживания, Lyft собирает данные о доступном транспорте в этой категории и учитывает расстояние, чтобы подобрать лучшего водителя для пассажира. Эти показатели основаны на дополнительных данных GPS и трафика.
Во время поездки данные о местоположении передаются с телефона водителя, поэтому Lyft может отслеживать прогресс и местоположение, а также сопоставлять его с другими запросами на поездку.
Передача данных в Lyft идет непрерывно — это обеспечивает максимальный комфорт для пользователей и клиентов.
2. YouTube
По данным Statista , каждую минуту на YouTube загружается более 500 часов видеоконтента — это огромный поток данных, который обрабатывается непрерывно.
YouTube необходимо одновременно анализировать множество данных, чтобы отслеживать и отображать количество просмотров, комментариев, подписчиков и другие показателей в режиме реального времени.
Учитывая большой размер и количество видеофайлов, YouTube по-прежнему остается очень доступным и удобным для пользователей.
YouTube также поддерживает видео, в которых создатели контента и зрители могут взаимодействовать друг с другом с помощью видеопотока и чата в реальном времени. В этом случае мгновенная передача данных очень важна, чтобы обеспечить бесперебойную работу.
Проблемы с потоками данных
1. Доступность.
Помимо записи данных их необходимо регистрировать в хранилище. Если клиент продлил подписку на ваш премиум контент — это прекрасно, но если вы не сможете проанализировать историю его покупок, то скорее всего вы не сформируете для него новые предложения на основе его предпочтений.
2. Своевременность.
Данные из потоков быстро устаревают, поэтому очень важно, чтобы ваше приложение могло реагировать на последнюю информацию и обновлять свои алгоритмы.
3. Масштабируемость.
Объем потока данных может быть огромным, поэтому важно убедиться, что ваши инструменты хранения и обработки готовы к работе.
Зачем нужна потоковая обработка данных, как её сочетать с пакетной, почему не обойтись без Apache Spark

Что такое потоковая обработка данных? Это – когда решение в реальном времени обрабатывает данные, которые поступают также в реальном времени, в формате потока, генерируются непрерывно. В потоке сложно определить полный и целостный набор данных. Обычно компании не имеют возможности хранить такие данные в полном объёме, произвольный доступ к ним есть не всегда.
Только знакомитесь с потоковой обработкой данных? Чтобы не запутаться в понятиях, прочитайте статью, 6 фактов об Apache Spark, которые нужно знать каждому. О значении потоковой обработки данных, необходимости сочетать её с пакетной и о том, как использовать для этого Apache Spark, размышляет Вамши Сриперумбудур. В Informatica Вашми занимается маркетингом решений Big Data и аналитики.
Задачи для потоковой обработки данных
Потоковая обработка данных применяется не только для данных, собранных через интернет вещей. Вот несколько примеров задач, для которых она будет полезна:
- Бороться с финансовыми мошенничествами (фродом) в реальном времени;
- Быстро сделать интересное предложение клиенту, который собирается перестать пользоваться вашими услугами или покупать у вас товары;
- Ввести динамическое ценообразование, в некоторых случая оперативно снижать цену для клиентов;
- Привлечь потенциального клиента в магазин, рядом с которым он находятся;
- В реальном времени мониторить данные пациентов.
Существует множество других примеров использования потоковой обработки данных в финансовом секторе, телекоме, рознице, здравоохранении, энергетике и государственном секторе.
Управляем одновременно потоковой обработкой данных и пакетной
Зачастую потоковая обработка данных не приносит пользы без привлечения пакетной. Давайте представим, то мы определили клиента для маркетинговых коммуникаций. Он входит в магазин? Мы его идентифицируем (например, с помощью видеокамеры) и сразу в реальном времени делаем ему персонализированное предложение. Для этого мы можем использовать его поисковую историю в браузере или историю его покупок в нашем магазине.
Данные с видеокамеры будут поступать в потоке, потребуют потоковой обработки данных. Пакетная используется системами, в которых хранится информации о клиенте, на основе которой мы будем делать наше предложение. Например, это может быть MDM-система. Данные в первом и втором случае будут значительно различаться. Они поступают на разных скоростях, с разной латентностью, задержкой. Эти различия нужно будет преодолеть, чтобы в реальном времени сделать клиенту персональное предложение. Данные нужно будет интегрировать.
Потоковая обработка данных с Apache Spark: разбить поток на фрагменты
Раньше потоковую обработку данных можно было осуществлять только отдельно от пакетной. Это подразумевало, что традиционные ETL-решения не могли работать с данными в потоке (обрабатывать данные и вносить их в базы). Для таких задач нужно было внедрять отдельное решение.
Некоторые вендоры, которые предлагают решения, которые ориентированы только на потоковую обработку данных, даже заявляли, что пакетная не нужна совсем. Они доходили до того, что называли её видом потоковой обработки данных.
Например, среди решений, которые успешно применялись для потоковой обработки данных – Apache Spark. Он разделяет информацию на устойчивые распределенные наборы данных (RDD). По сути, Apache Spark разбивает поток данных на RDD – фрагменты данных, которые распределяются по разным узлам кластера. Несколько таких фрагментов соединяются вместе в микро-пакет – DStream (Discretized Stream). Несколько DStream могут обрабатываться параллельно.
Проблема с механизмом DStream как раз была в том, при его применении приходилось разделять потоковую обработку данных и пакетную, а это усложняло весь механизм работы с данными и делало её дороже.
Потоковая обработка данных с Apache Spark: превратить поток в бесконечную таблицу для SQL
Со второй версии в Apache Spark доступен Structured Streaming, который помог преодолеть недостаток DStream. Structured Streaming – это масштабируемый и отказоустойчивый фреймворк для потоковой обработки данных, в основе его Spark SQL. Structured Streaming представляет поток данных в виде бесконечной таблицы.
Решение позволяет и проводить потоковую обработку данных, и интеграцию их с данными, которые обрабатываются пакетной. Другими словами, Structured Streaming для решений Big Data пытается унифицировать потоковые, итеративные и пакетные запросы с помощью абстрактного структурирования данных.